







了解 OpenAI 的强化微调技术,这是一种利用奖励驱动训练循环完善大型语言模型的新技术。
在 "12 Days of OpenAI "活动的第二天,OpenAI 宣布了一种微调模型的新技术,称为 “强化微调”。 强化微调与 OpenAI 已经可用的开发人员仪表板集成在一起,您可以在该仪表板上微调您的模型或在其平台上执行知识提炼。 在本文中,我将介绍我们目前对强化微调的了解,并探讨未来的发展前景。
什么是强化微调(Reinforcement Fine-Tuning)?
强化微调(RFT)是一种通过奖励驱动的训练循环来完善大型语言模型知识的技术。
前沿模型是了不起的通用语言模型。 它们中的佼佼者能胜任翻译、辅助、编程等多种任务。 然而,目前研究的一个重要领域是对这些模型进行有效的微调。 我们的目标是对这些模型进行调整,以适应特定的语气和风格,或专注于狭窄的领域,如提供专家医疗建议或执行特定领域的分类任务。
挑战在于如何高效地实现这种微调。 效率意味着消耗更少的计算能力,需要更少的标注数据集,同时仍能获得高质量的结果。 这正是 RFT 发挥作用的地方,它为这一问题提供了前景广阔的解决方案。
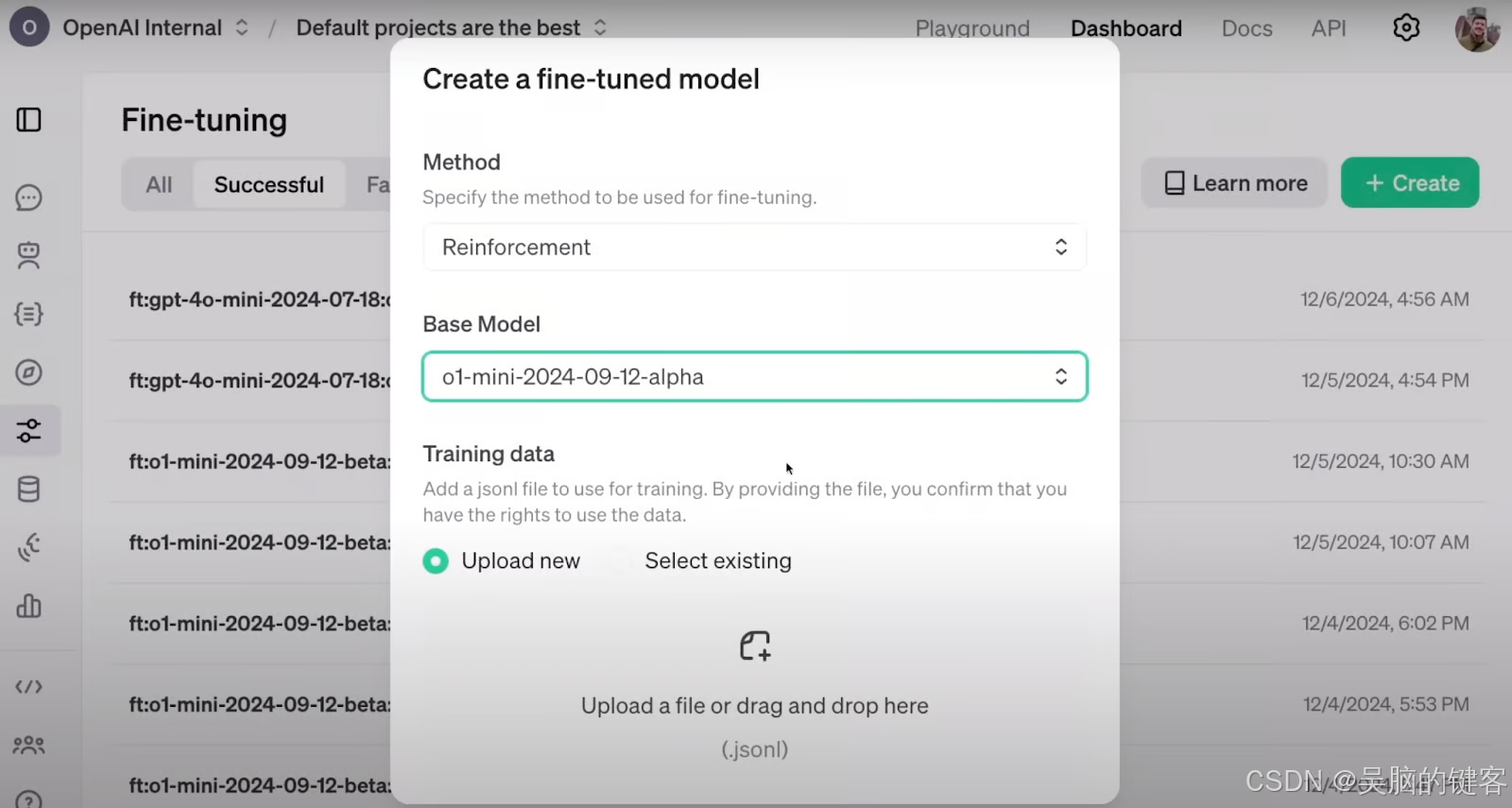
这就是在 OpenAI 的仪表板上配置 RFT 的过程。 来源:OpenAI
根据 OpenAI 的公告,RFT 只需几十个例子就能有效地对模型进行微调。 RFT 建立在强化学习(RL)的基础之上,即根据代理的行为给予积极或消极的奖励,使它们能够与我们期望的行为保持一致。
这是通过给代理的输出分配分数来实现的。 通过基于这些分数的迭代训练,代理无需明确理解规则或记住解决问题的预定义步骤即可学习。
当与改进专门任务的 LLM 的努力相结合时,RFT 就会从 RL 和微调技术中脱颖而出。 我们的想法是通过一系列步骤来执行 RFT:
- 提供一个有标记的结构化数据集,使模型具备你希望它学习的知识。 与典型的机器学习任务一样,该数据集应分为训练集和验证集。
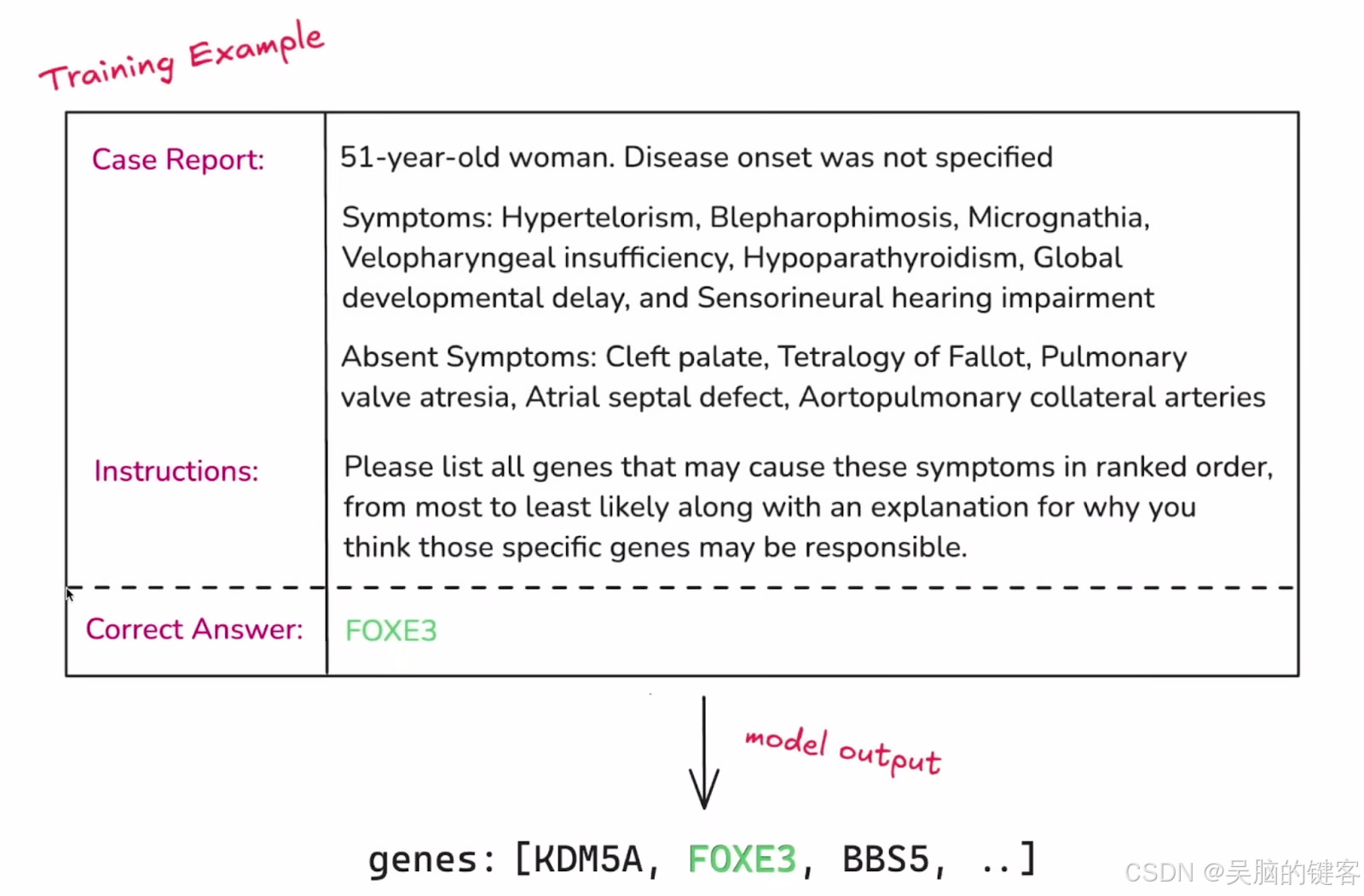
数据集单例示例。 来源:OpenAI
-
RFT 的下一个关键组成部分是建立一种评估模型输出的方法。在典型的微调过程中,模型只是试图重现标注的目标答案。然而,在 RFT 中,模型应该开发一个推理过程,从而得出这些答案。在微调过程中,对模型输出的分级是对模型的指导,它是通过 "分级器 "来完成的。等级可以从 0 到 1,也可以介于两者之间,有很多方法可以给模型的输出结果分配等级。OpenAI 宣布计划推出更多的分级器,并可能为用户引入一种实现自己自定义分级器的方法。
-
一旦模型对训练集的输入做出反应,其输出就会被评分器评分。这个分数就是 "奖励 "信号。然后对模型的权重和参数进行调整,使未来的奖励最大化。
-
通过重复步骤对模型进行微调。在每个循环中,模型都会改进其策略,并定期使用验证集(与训练集分开)来检查这些改进对新示例的泛化程度。当模型在验证数据上的得分有所提高时,就表明模型真正在学习有意义的策略,而不是简单地记忆解决方案。
这一解释抓住了 RFT 的本质,但实施和技术细节可能有所不同。
以下是 RFT 的评估结果,它将经过微调的 o1-mini 模型与标准 o1-mini 模型和 o1 模型进行了比较,令人惊讶的是,尽管 o1-mini 模型比 o1-mini 模型更大、更先进,但 RFT 在使用仅 1100 个示例的数据集时,获得了比 o1 模型更高的准确率。
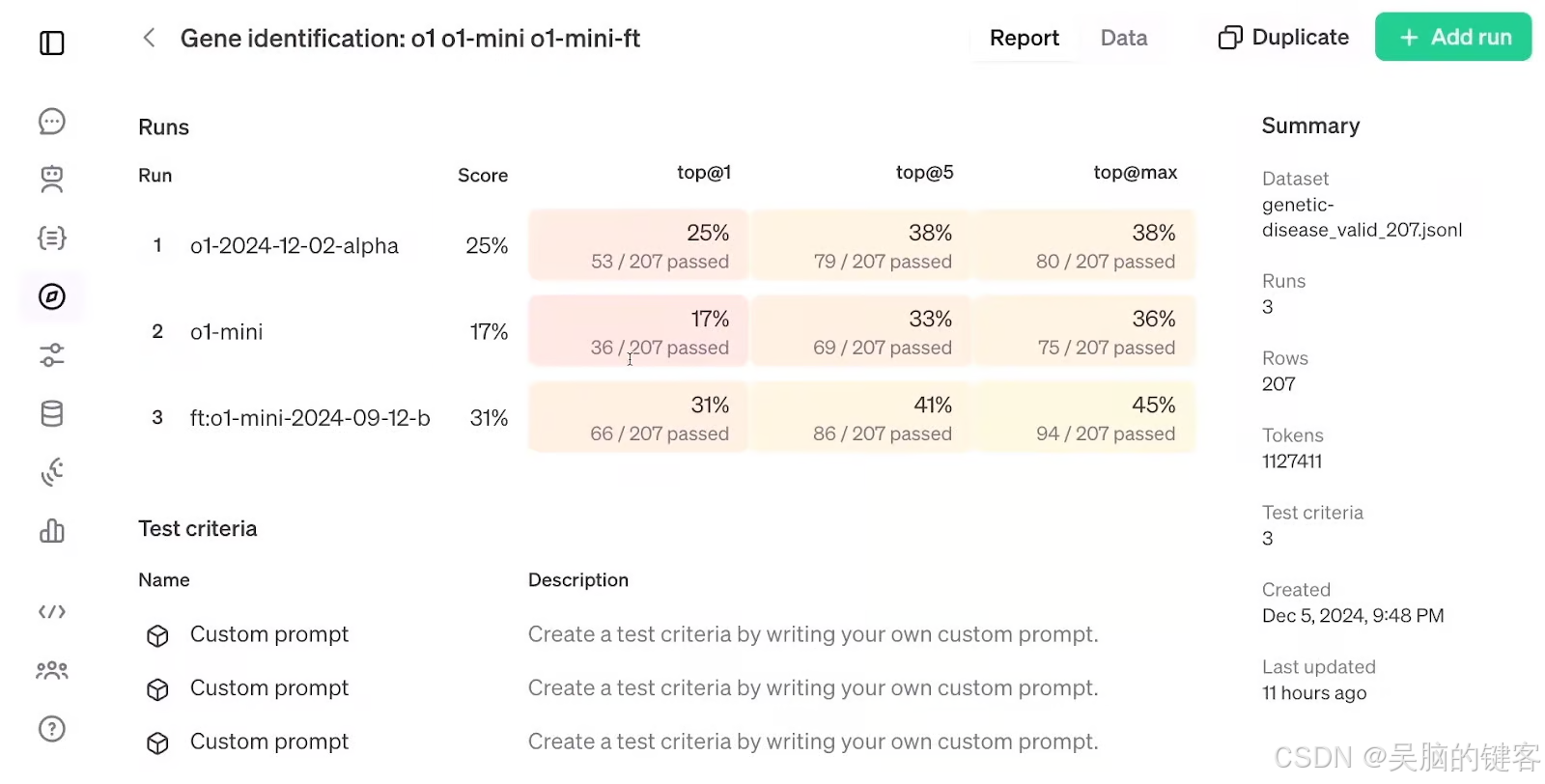
对 RFT 的评估。 来源:OpenAI
监督微调与强化微调
监督微调(SFT)是指使用监督学习技术,将预先训练好的模型与其他数据结合起来进行调整。在实践中,当目标是根据特定数据集调整模型的输出或格式,或确保模型遵循某些指令时,SFT 的效果最佳。
虽然监督微调和强化微调都依赖于标注数据,但它们的使用方式不同。在 SFT 中,标注数据直接驱动模型的更新。模型将其视为目标输出,并调整参数以缩小预测输出与已知正确答案之间的差异。
在 RFT 中,模型对标签的接触是间接的,因为它主要用于创建奖励信号,而不是直接目标。这就是为什么在 RFT 中,模型需要的标签数据会更少–模型的目的是找到产生我们想要的输出的模式,而不是直接以产生我们的输出为目标,这就保证了更大的泛化倾向。
让我们用这个表格来总结一下这些差异:
| 特征 | 监督微调(SFT) | 加固微调(RFT) |
| 核心思想 | 在标记的数据上直接训练模型以匹配所需的输出。 | 使用“分级器”为模型提供奖励以生成所需的输出。 |
| 标签用法 | 直接针对模型进行模仿。 | 间接用于为模型创建奖励信号。 |
| 数据效率 | 需要更多标记的数据。 | 由于泛化,可能需要较少标记的数据。 |
| 人类参与 | 仅在初始数据标签中。 | 仅在设计“分频器”功能时。 |
| 概括化 | 可能过度适应培训数据,从而限制了概括。 | 由于专注于模式和奖励,因此具有更高的泛化潜力。 |
| 与人类偏好保持一致 | 有限,因为它仅依赖于模仿标记的数据。 | 如果“分级器”准确地反映了人类的喜好,则可以更好地对齐。 |
| 例子 | 微调语言模型以生成特定类型的文本格式(例如诗歌或代码)。 | 培训语言模型以生成创意内容,这些内容由基于独创性和连贯性的“标尺”判断。 |
在阅读有关 RFT 的文章时,我不禁想到了另一种有效而经典的技术–人类反馈强化学习(RLHF)。 在 RLHF 中,人类注释者会就如何回应提示提供反馈,而奖励模型则会经过训练,将这些反馈转化为数字奖励信号。 然后通过近端策略优化 (PPO) 利用这些信号对预训练模型的参数进行微调。
虽然 RFT 将人的反馈从环路中剥离出来,并依靠分级器将奖励信号分配给模型的响应,但将强化学习整合到 LLM 微调中的想法仍与 RLHF 的想法一致。
有趣的是,RLHF 是他们之前在 ChatGPT 训练过程中用来更好地调整模型的方法。根据公告视频,RFT 是 OpenAI 内部用来训练 GPT-4o 或 o1 pro 模式等前沿模型的方法。
结论
强化学习之前已经被集成到了 LLM 的微调中,但 OpenAI 的强化微调似乎将其提升到了一个更高的水平。 虽然 RFT 的具体机制、发布日期以及对其有效性的科学评估还未披露,但我们可以祈祷 RFT 能够很快面世,并像承诺的那样功能强大。

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









