







主要参考了InfiniTAM的文章:
Very High Frame Rate Volumetric Integration of Depth Images on Mobile Device
系统概述
InfiniTAM的系统主要分为三个阶段:
(1)跟踪阶段:用于新输入的图像进行定位,求得其对应的相机位姿等相关信息
(2)融合阶段:用于将新数据集成到现有的3D世界模型当中(主要是通过更新voxle中存储的SDF值来做到的),并在计算设备和主机之间进行数据交换
(3)渲染阶段:利用Raycasting从世界模型中提取与下一个跟踪步骤相关的信息,用于跟踪阶段的ICP匹配
可以看到其实InfiniTAM的主要流程和Kniect Fusion是非常相似的。
World Representation
InfiniTAM采用传统体积方法进行3D建模,主要用的算法还是TSDF。通过SDF值选取出在重建表面附近的voxel,然后通过寻找零叉点来得到具体的重建表面。因为大部分的空间都在截断带之外,所以大大节省了内存。和Voxel Hashing一样,采用的是888个体素构造成voxel block,用来密集的标识截断带内的场景部分。
为了减少voxel block的查找开销,所以使用了hash表的方式进行管理。
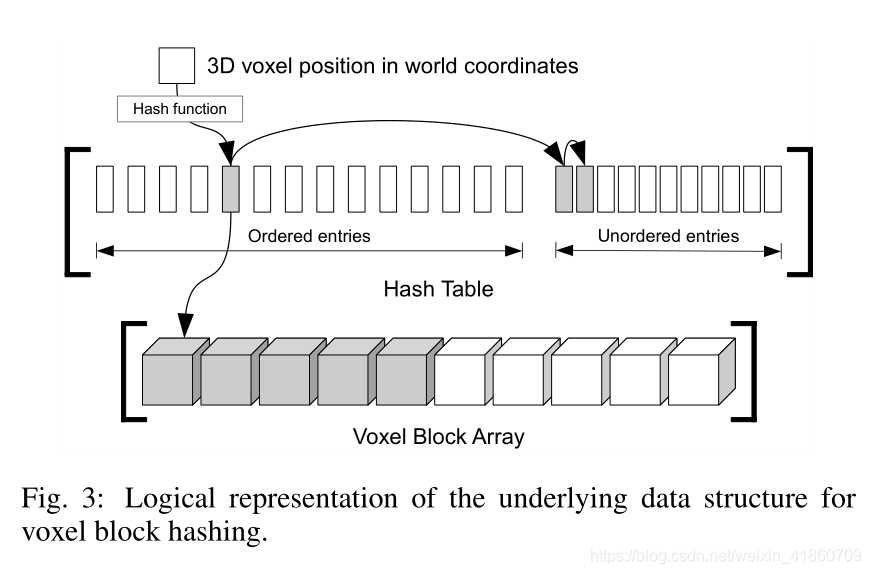
世界坐标中的每个3D位置都属于一个voxel block,每个voxel的坐标除以voxel block的大小,就可以获得每个3D voxel所在的voxel block的坐标。然后使用哈希函数将voxel block和哈希表中的条目进行关联。哈希函数如下
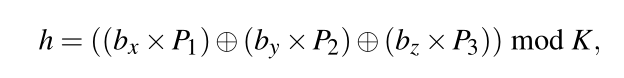
其中,(bx,by,bz)是voxel block的坐标,P1,P2,P3是三个大素数ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4167
4167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









