









由于高博大佬已经推导得特别好,所以很多地方从高博大佬那粘贴过来。高博大佬的推导链接为:简明ESKF推导 - 知乎 (zhihu.com)
ESKF(error state Kalman filter)是Kalman滤波的一种特殊形式,采用ESKF的原因是由于对误差的线性化要比直接对函数进行线性化更加符合实际情况。如下图:
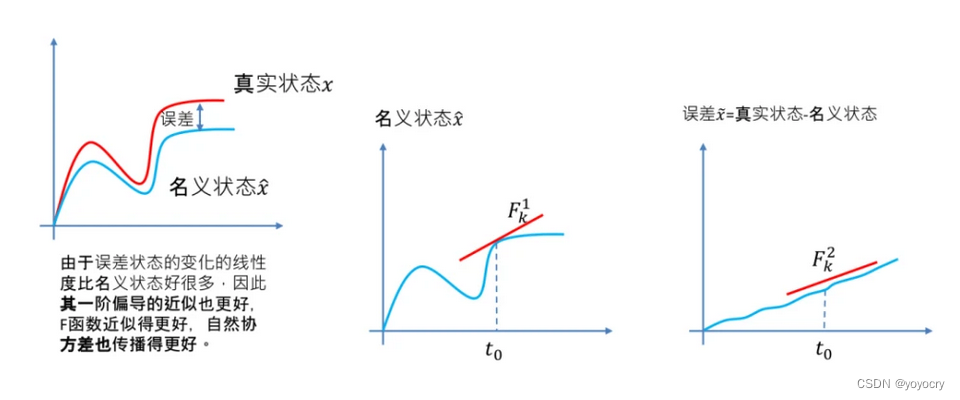 在ESKF中,我们通常把包含全部噪声的状态变量称为观测状态变量
在ESKF中,我们通常把包含全部噪声的状态变量称为观测状态变量。只有当前正态噪声(无维纳噪声)的变量称为名义状态变量(nominal state)
,然后把ESKF里的状态变量称为误差状态变量(error state)
。三者关系为:
。
1 true state kinematics
对于true state kinematics(动力学), 微分形式有:
对于IMU的真实值,
可测量值
之间的关系:
将等式(2)代入等式(1)有:
注意的存在维纳过程的噪声是
,
噪声是
。所以存在当前时刻测量噪声
和
,以及维纳过程中的噪声。
2 Nominal-state kinematics
无时间累计噪声或扰动(无维纳噪声)的理想建模系统,nominal-state中不包含时间累计噪声,从上面公式中去除时间累计Noise项。
其中加速度和角速度为:
3 error-state kinematics
将true-state部分的kinematics方程中减去nominal-state就可以得到error-state的kinematics方程。首先定义误差状态变量为:
等式两侧分别对时间求导(注意这里是维纳噪声):
(1)旋转项求导
对于旋转项两侧求导为:
两边同乘可得:
注意第三行因为为小量,实部接近于1,虚部近似为角度。注意
。所以只需要取虚部即可:
第二行忽略了第一行的第三项的两个小量相乘法。并且,注意 。
,将
代入有
。于是有:
。将这些代入等式(14)有:
(2)速度项推导
注意:1)与
和
乘法项全为0;2)
所以:
4 离散时间系统运动学
(1)error-state的预测步推导
除了,其余按照
来计算
nominal state kinematics的离散运动模型
error-state kinematics的离散运动模型
对第二行和第三行进行展开(第三行中使用泰勒展开):
结果为:
故设状态方程如下:
其中分别代表norminal state状态变量,error-state状态变量,输入参数和扰动的噪声项,error-state运动方程满足:
所以:
1)
2)
ESKF是扩展卡尔曼滤波的推导,所以下面使用的都是扩展卡尔曼滤波
(2)ESKF滤波
ESKF对IMU信息进行预测,其他信息用于校正滤波器,从而观察IMU bias误差和观测误差。纠正包括三个步骤:
-
使用ESKF对误差状态变量(error state)进行预测和更新
-
更新的误差状态(error state)修正名义状态变量(nominal state)
-
重置ESKF
(2.1)预测与更新
1)ESKF的预测过程(预测过程包括对误差状态的预测和协方差传播的预测):
其中为(
和
不存在扰动,所以为0):
(这里不理解为啥方差是这样子?)
噪声项为:
此外,需要使用nominal state kinematics的离散运动模型来估计名义状态的预测(IMU积分)
2)ESKF的更新过程:
假设一个抽象的传感器能够对状态变量产生观测(IMU以外的传感器观测),其观测方程为抽象的,则:
其中为观测数据(其他传感器对x的观测数据),
为观测噪声,
为该噪声的协方差矩阵。
在传统EKF中,我们可以直观对观测方程线性化,求出观测方程相对于状态变量的雅可比矩阵,进而更新卡尔曼滤波器。而在ESKF中,我们当前拥有名义状态(nominal state)的估计,以及误差状态
的估计。
所以算误差状态的更新过程:
其中为修正后的协方差矩阵,
是观测方程相比于误差状态的雅可比矩阵 ,计算方式如下:
其中第一项只需对观测方程进行线性化,第二项根据我们之前对状态变量的定义(见下方),可以得到:
其他几种都是平凡的,只有旋转部分,因为定义为
的右乘,我们用右乘的BCH近似为:
(2.2)修正nominal state
注意是当前时刻的nomial state。
(2.3)重置ESKF
ESKF的重置可以简单地实现为:
同时保留协方差的估计。















 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









