









SAM自推出以来,已经广泛应用于CV各任务,各种创新层出不穷。到了2025年,SAM仍然有相当大的优化空间,尤其是通过结合多模态图像融合,可以进一步提高分割精度和效率,增强适应性,大幅拓宽应用场景。
对论文er来说,这也意味着创新空间更大了。目前在CVPR、IJCAI等顶会上已经出现了不少相关成果,比如性能超越SOTA的SAGE方法、鲁棒多模态3D目标检测框架RoboFusion。感兴趣的论文er抓紧时机!
为了方便各位快速了解前沿,这次我挑选了10个SAM+多模态图像融合最新成果分享,基本都有开源代码,今年也推荐各位重点关注动态融合、开放词汇语义对齐、极端条件鲁棒性等小方向。
全部论文+开源代码需要的同学看文末
Every SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
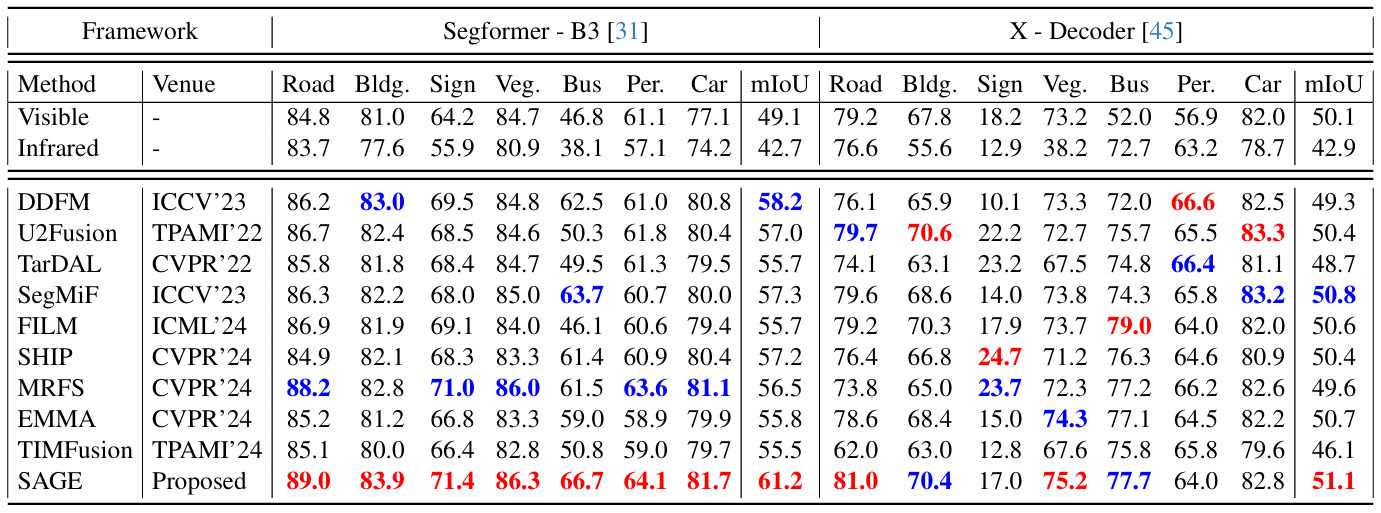
方法:论文提出了一种名为SAGE的多模态图像融合方法,通过结合 SAM 的语义先验知识和双层优化蒸馏机制,实现了高质量的图像融合和下游任务的适应性,同时降低了计算复杂度,提高了部署效率。
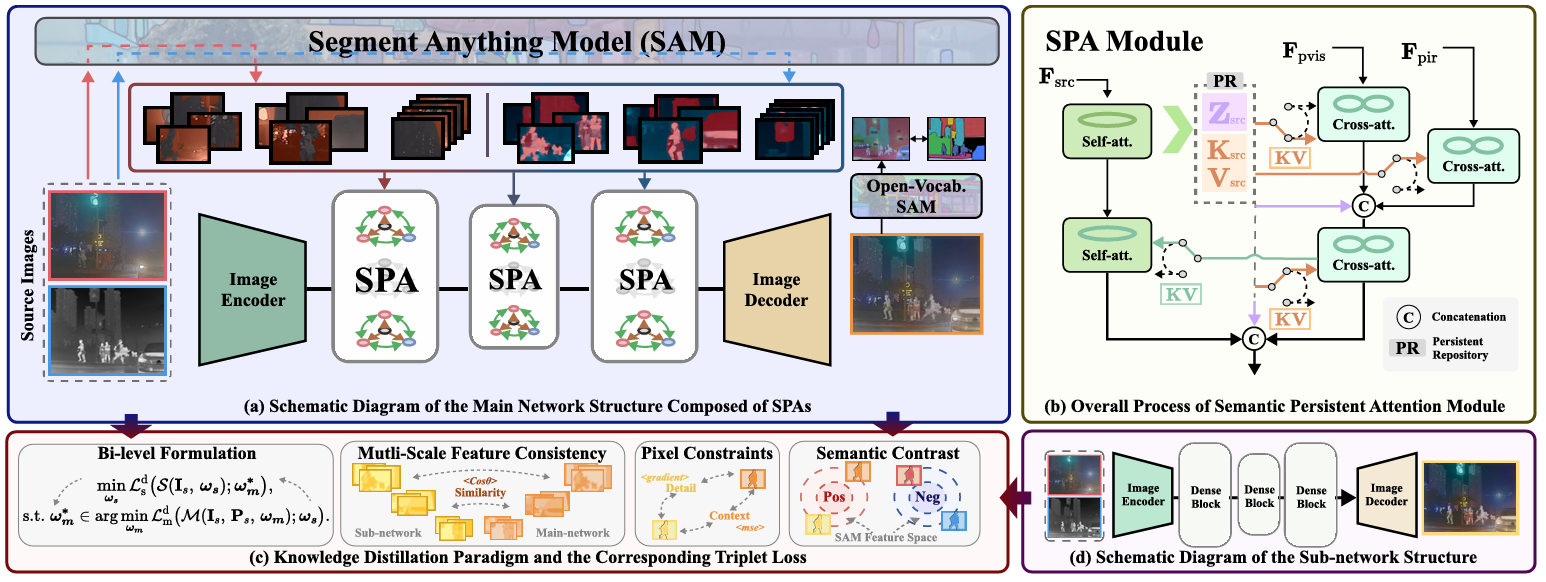
创新点:
-
提出了一种新的多模态图像融合框架SAGE,利用SAM的语义先验知识,提升融合图像的质量和下游任务的适应性。
-
设计了SPA模块,通过持久存储库保留源图像信息,同时从 SAM 中提取高级语义先验。
-
引入了双层优化驱动的蒸馏机制,将SAM的知识转移到轻量级子网络中,减少推理阶段的计算复杂度,同时保持高效的部署能力。
RoboFusion: Towards robust multi-modal 3D object detection via SAM
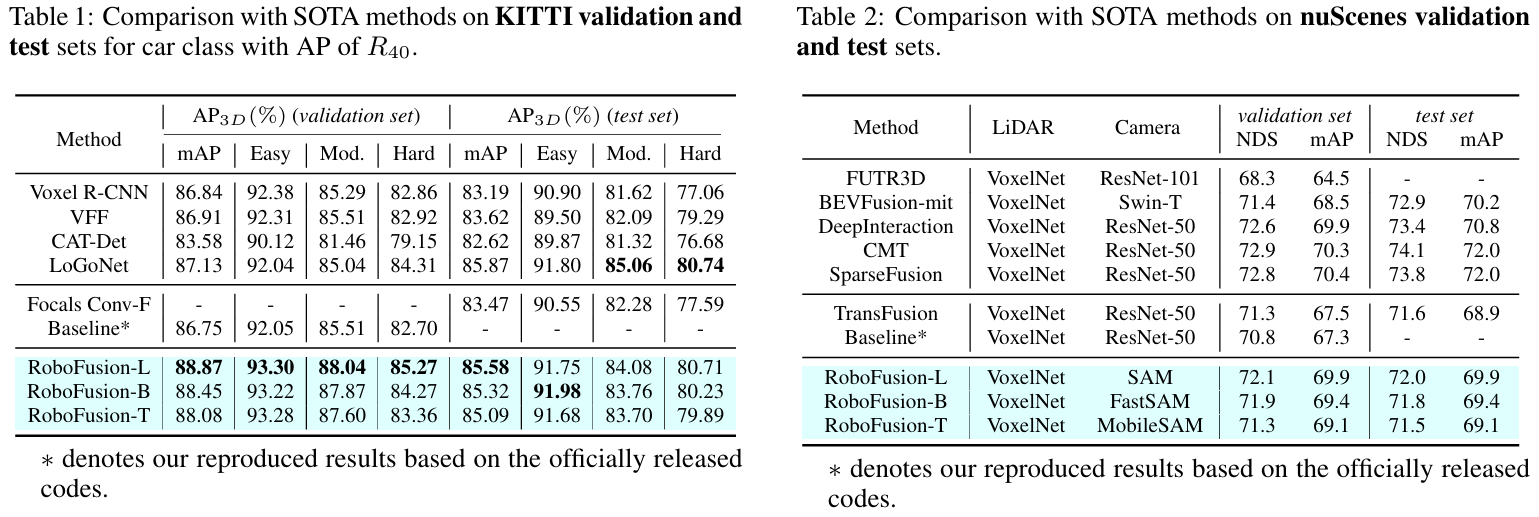
方法:论文提出了一种名为RoboFusion的鲁棒多模态 3D 目标检测框架,通过将视觉基础模型与多模态图像融合相结合,利用SAM的强大泛化能力以及深度引导的小波注意力和自适应融合技术,有效减少噪声和恶劣天气条件下的干扰,从而显著提升自动驾驶场景中目标检测的鲁棒性和泛化能力。
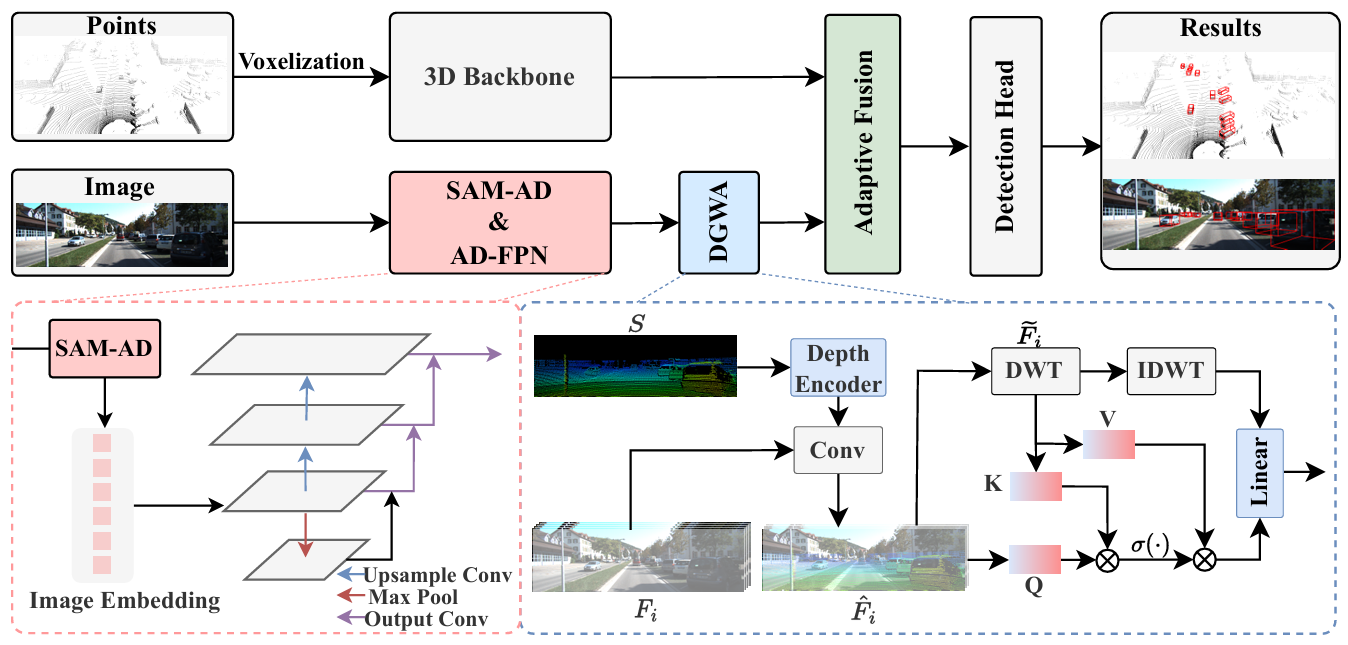
创新点:
-
提出了 SAM-AD 和 AD-FPN,将 SAM 预训练适应自动驾驶场景,并通过特征上采样与多模态 3D 目标检测对齐。
-
设计了深度引导的小波注意力模块,利用小波分解对深度引导图像特征进行去噪,减少噪声干扰。
-
引入自适应融合模块,通过自注意力机制动态调整点云和图像特征的权重,增强特征鲁棒性。
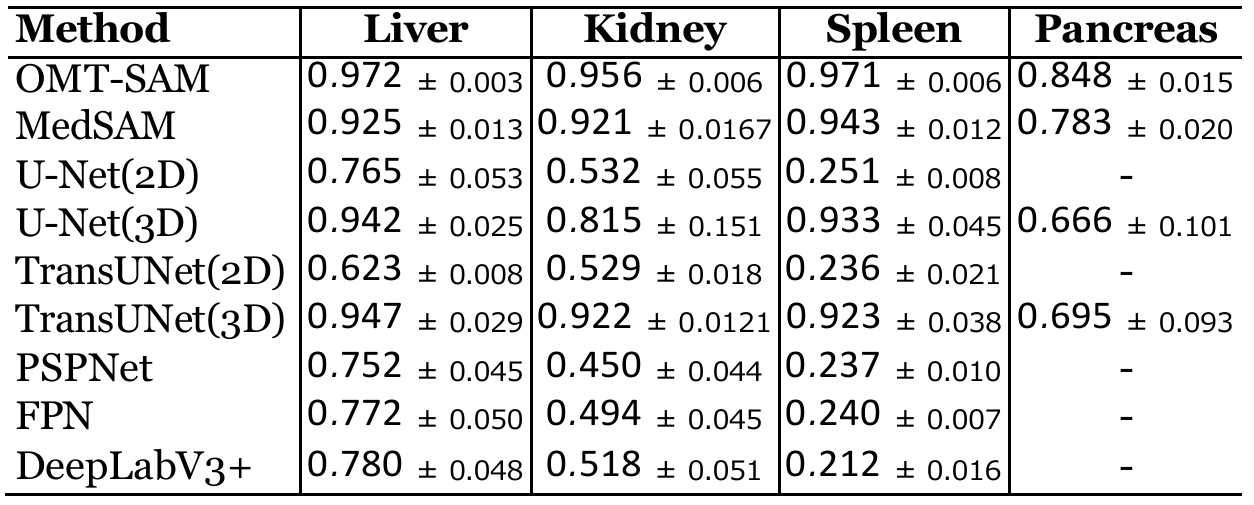
Organ-aware Multi-scale Medical Image Segmentation Using Text Prompt Engineering
方法:论文提出了一种基于SAM的医学图像分割模型OMT-SAM,通过结合CLIP模型实现图像与文本提示的融合,并利用多尺度特征提取来提升分割精度,尤其在复杂器官的边界识别上表现出色。
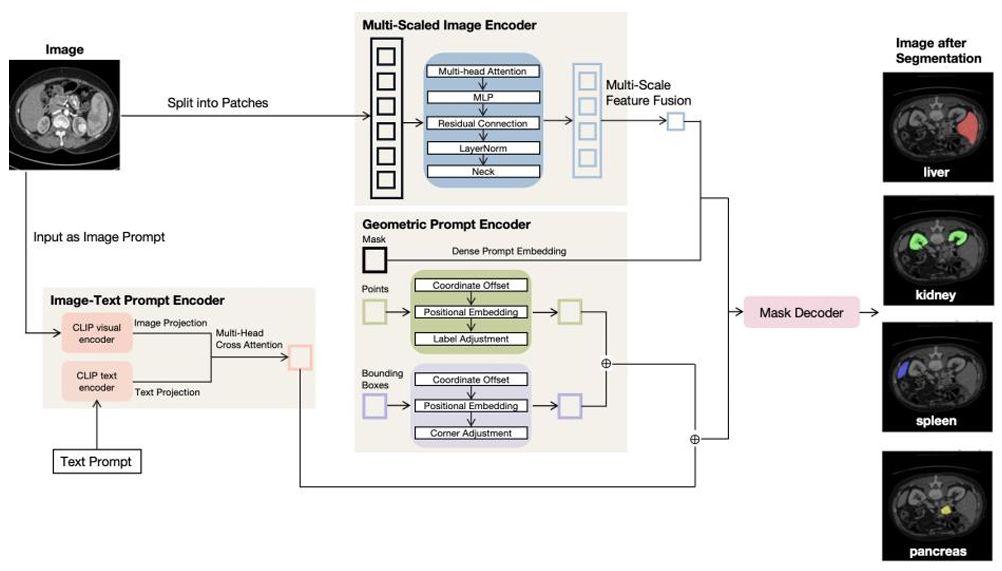
创新点:
-
引入CLIP模型作为图像-文本提示编码器,融合文本描述与医学图像特征,通过交叉注意力生成图像-文本嵌入,提升对复杂解剖结构的理解。
-
提出多尺度视觉特征提取方法,从MedSAM中提取不同粒度特征,细致捕捉器官边界和细节,提高分割精度。
-
在FLARE 2021数据集上表现优异,尤其在复杂器官分割中超越现有模型。
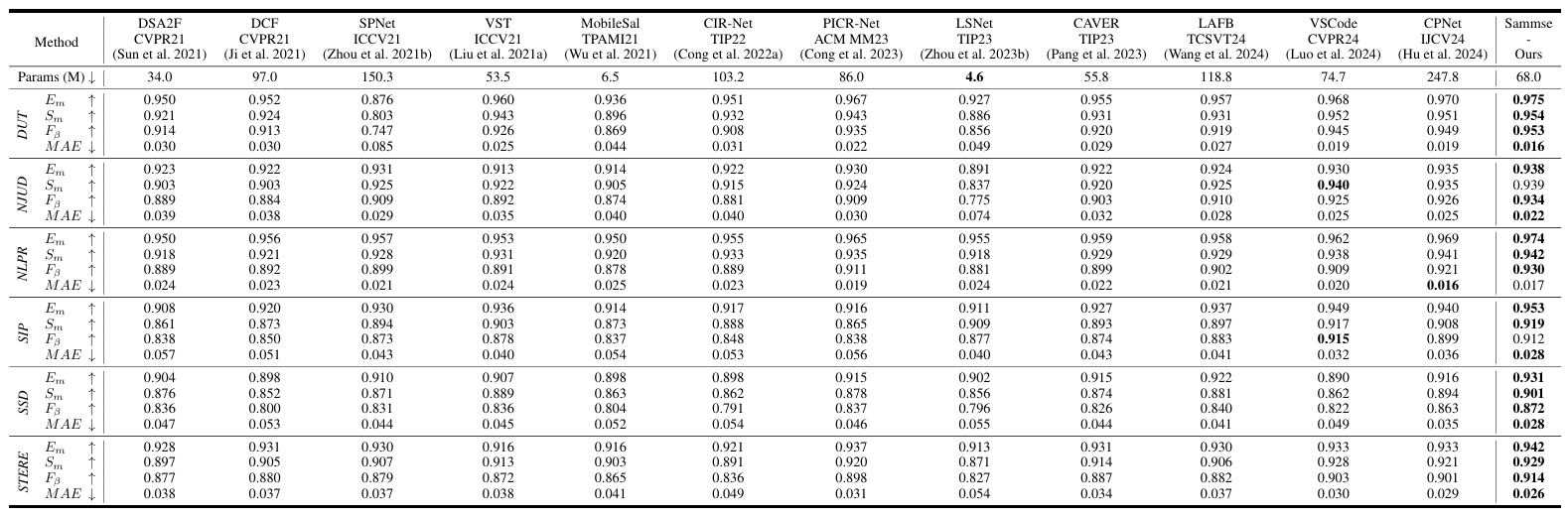
Adapting Segment Anything Model to Multi-modal Salient Object Detection with Semantic Feature Fusion Guidance
方法:论文提出了一种基于SAM的多模态显著目标检测框架Sammese,通过融合多模态图像的语义特征,增强SAM对显著目标的检测能力,显著提升了多模态数据下的检测性能。
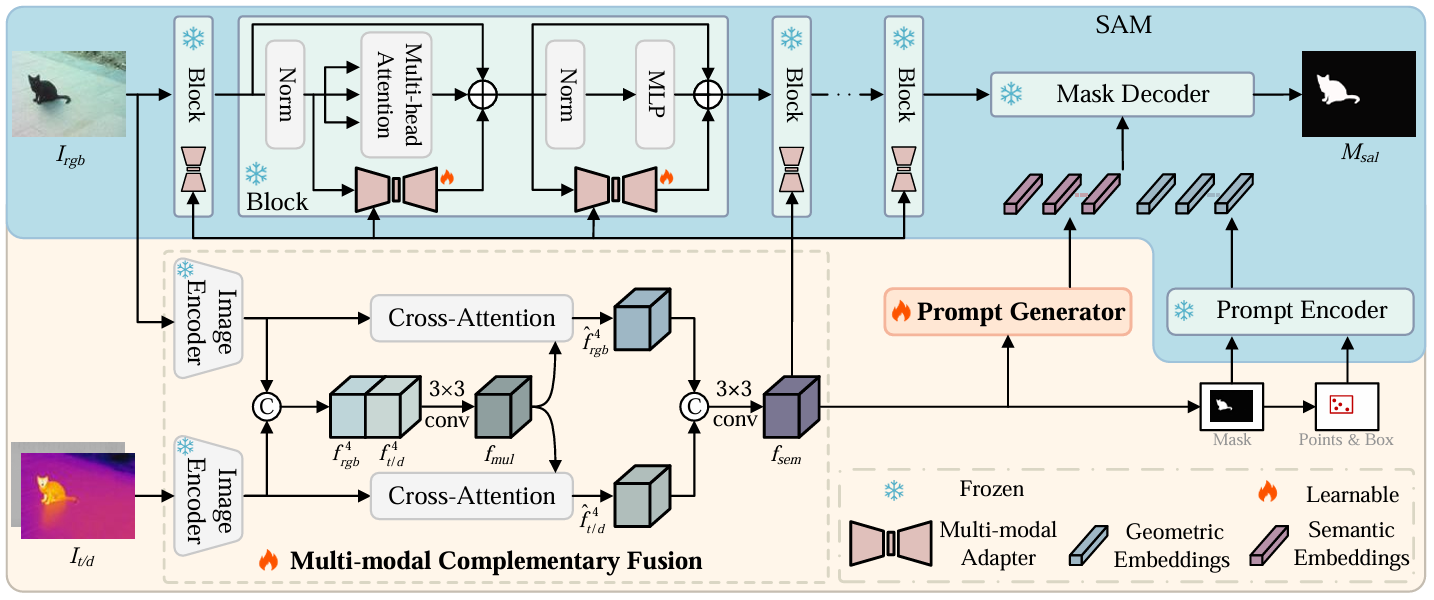
创新点:
-
多模态融合模块整合可见光与热成像/深度图像的语义特征,增强模型输入信息。
-
多模态适配器嵌入SAM图像编码器,使其适应多模态数据,提升复杂场景处理能力。
-
提出语义-几何提示生成策略,自动生成提示嵌入,提高显著目标检测精度。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









