







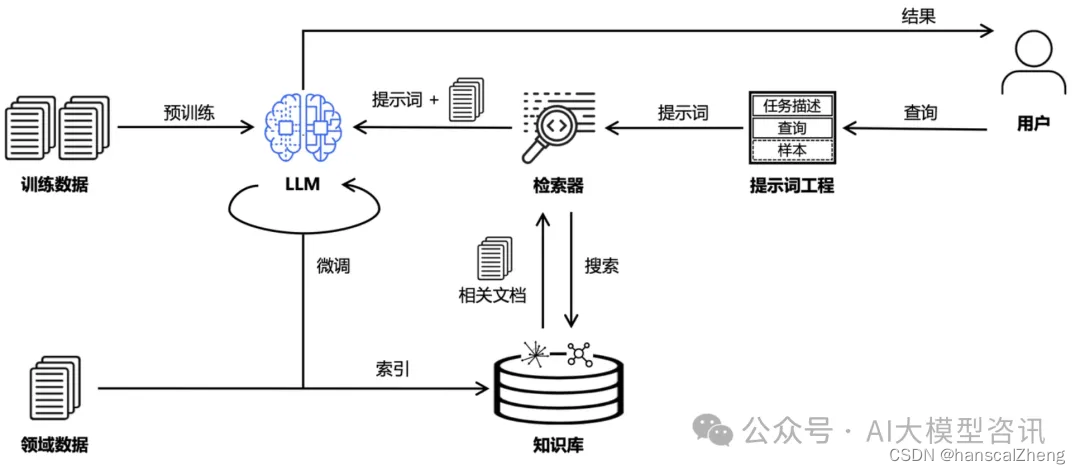
检索增强生成RAG(Retrieval Augmented Generation)技术旨在把信息检索与大模型结合,以缓解大模型推理“幻觉”的问题。RAG的目标是通过知识库增强内容生成的质量,通常做法是将检索出来的文档作为提示词的上下文,一并提供给大模型让其生成更可靠的答案。更进一步地,RAG的整体链路还可以与提示词工程(Prompt Engineering)、模型微调(Fine Tuning)、知识图谱(Knowledge Graph)等技术结合,构成更广义的RAG问答链路。近来关于RAG的研究如火如荼,支持RAG的开源框架也层出不穷,并孕育了大量专业领域的AI工程应用。
1 传统RAG的7个问题
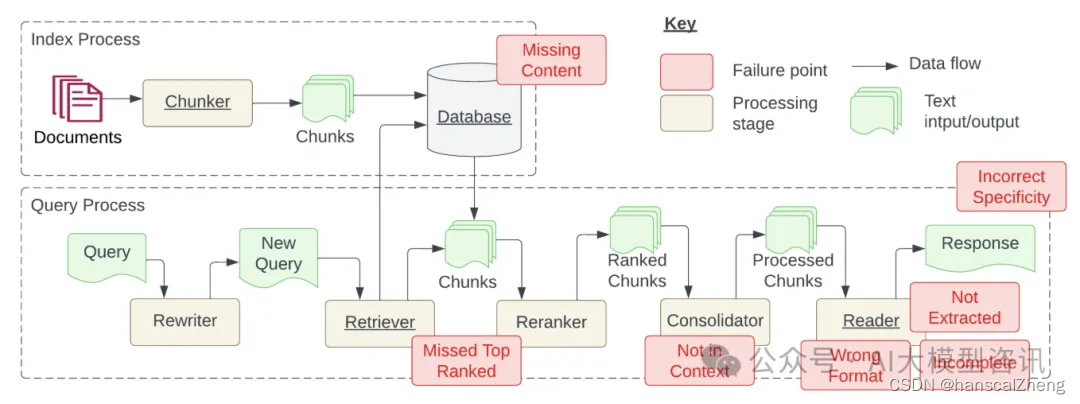
传统RAG希望通过知识库的关联知识增强大模型问答的上下文以提升生成内容质量,但也存在以下的几个问题:
-
知识库内容缺失:现有的文档其实回答不了用户的问题,系统有时被误导,给出的回应其实是“胡说八道”,理想情况系统应该回应类似“抱歉,我不知道”。
-
TopK截断有用文档:和用户查询相关的文档因为相似度不足被TopK截断,本质上是相似度不能精确度量文档相关性。
-
上下文整合丢失:从数据库中检索到包含答案的文档,因为重排序/过滤规则等策略,导致有用的文档没有被整合到上下文中。
-
有用信息未识别:受到LLM能力限制,有价值的文档内容没有被正确识别,这通常发生在上下文中存在过多的噪音或矛盾信息时。
-
提示词格式问题:提示词给定的指令格式出现问题,导致大模型/微调模型不能识别用户的真正意图。
-
准确性不足:LLM没能充分利用或者过度利用了上下文的信息,比如给学生找老师首要考虑的是教育资源的信息,而不是具体确定是哪个老师。另外,当用户的提问过于笼统时,也会出现准确性不足的问题。
-
答案不完整:仅基于上下文提供的内容生成答案,会导致回答的内容不够完整。比如问“文档A、B和C的主流观点是什么?”,更好的方法是分别提问并总结。
2 解决方案
总的来看,这些问题都可以通过一定的技术来解决或缓解:
问题1-3:属于知识库工程层面的问题,可以通过完善知识库、增强知识确定性、优化上下文整合策略解决。
问题4-6:属于大模型自身能力的问题,依赖大模型的训练和迭代。
问题7:属于RAG架构问题,更有前景的思路是使用Agent引入规划能力。
3 结语
传统的RAG技术逐渐开始与提示词工程(Prompt Engineering)、模型微调(Fine Tuning)、知识图谱(Knowledge Graph)和智能体(Agent)等技术结合,构成更广义的RAG问答链路框架。
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!


















 4289
4289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









