







文章介绍了一种称为VMRNN(Vision Mamba RNN)的新模型,该模型通过整合Vision Mamba模块与长短期记忆网络(LSTM),以应对时空预测挑战,特别是在处理视频序列预测等任务时,能够有效地建模长依赖关系并保持计算效率。文章强调了传统的卷积神经网络(CNNs)和视觉变换器(ViTs)在处理此类任务时的局限性,如感受野受限及计算需求高,并展示了VMRNN在网络规模较小的情况下,在多种时空预测任务中取得了有竞争力的结果。
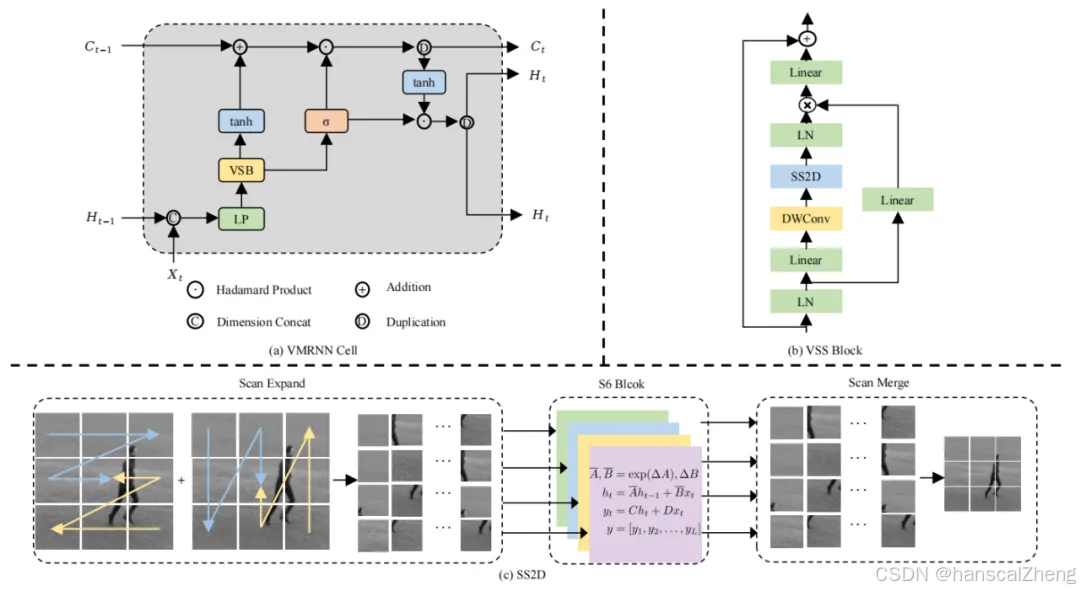
1 VMRNN的架构
一个基于VMRNN Cell的基本模型(VMRNN-B)和一个更深层的模型(VMRNN-D)。在每个时间步骤中,图像被分割为非重叠的补丁,并通过展平和初步线性转换进入后续处理阶段。
- 1.VMRNN-B模型:
处理流程:VMRNN层接收嵌入后的图像patch以及前一时刻的状态信息(隐藏状态Ht-1和细胞状态Ct-1),进而生成当前的隐藏状态Ht和细胞状态Ct。
多用途隐藏状态:Ht被复制用于两个目的,一是送入重构层,二是与Ct一起为下一时间步的VMRNN层提供输入。
- 2.VMRNN-D模型:
深度扩展:相比VMRNN-B,VMRNN-D包含更多的VMRNN单元,并引入了Patch Merging和Patch Expanding层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









