







前面写了一篇关于textrank的资料,几乎只是资料整理,方便大家查看,花了两天时间从头到尾去把textrank拉通了一遍,最后看了一篇代码(链接1),这个仓库里面的实现很接地气(能让人看懂,但是我去看仓库里面的提问到2021年几乎没有回答,owner应该是没有进行维护了,讲他们重新实现了该算法在genism里面),才发现里面的知识不只是算法公式这些理论,你要是想通过代码实现是另外一回事,下方我会贴图给大家看看真正开发原创代码的人数学功底在那(手机截图),有调text4rank包的讲的比较清楚(链接2),也有大概讲的不错思路清晰但到关键地方就说不清楚的从理论出发到最关键的地方但感觉又差点什么的(链接3),所以自己重推来一遍,textrank的实现方式有很多中,有基于(图+pagerank算法)去实现的,有基于(textrank最初的公式实现的),你要知道这个提取关键词,关键句的技术在深层网络技术没出来前可是抽取式的主流,不要妄想通过调用一下包或者调几个参数就能弄明白textrank算法,我觉得到目前我也没完全整明白(一些小细节比如图的实现,在一些处理上用到了稀疏矩阵等),不过这里能带大家入门了。
首先,要讲textrank,你得知道pagerank。请参考我之前整理的资料,基本能整明白了。
然后,咱们来看一张图,这是网上流传的textrank通常的流程图。
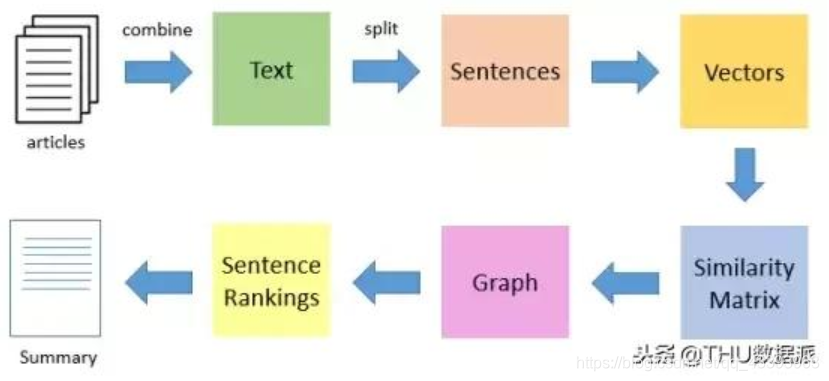
首先我想说的是,确实通过embedding(glove or word2vec)这样的技术后,去计算SimilarityMatrix可能确实会有不错方方面面的性能提升(准确率,算法效率,时间复杂度,空间复杂度等等),但我还没研究过来。首先咱们一步一步研究一下仓库一的核心代码Summarize.py:
rom math import log10
from .pagerank_weighted import pagerank_weighted_scipy as _pagerank
from .preprocessing.textcleaner import clean_text_by_sentences as _clean_text_by_sentences
from .commons import build_graph as _build_graph
from .commons import remove_unreachable_nodes as _remove_unreachable_nodes
def _set_graph_edge_weights(graph):
for sentence_1 in graph.nodes():
for sentence_2 in graph.nodes():
edge = (sentence_1, sentence_2)
if sentence_1 != sentence_2 and not graph.has_edge(edge):
similarity = _get_similarity(sentence_1, sentence_2)
if similarity != 0:
graph.add_edge(edge, similarity)
# Handles the case in which all similarities are zero.
# The resultant summary will consist of random sentences.
if all(graph.edge_weight(edge) == 0 for edge in graph.edges()):
_create_valid_graph(graph)
def _create_valid_graph(graph):
nodes = graph.nodes()
for i in range(len(nodes)):
for j in range(len(nodes)):
if i == j:
continue
edge = (nodes[i], nodes[j])
if graph.has_edge(edge):
graph.del_edge(edge)
graph.add_edge(edge, 1)
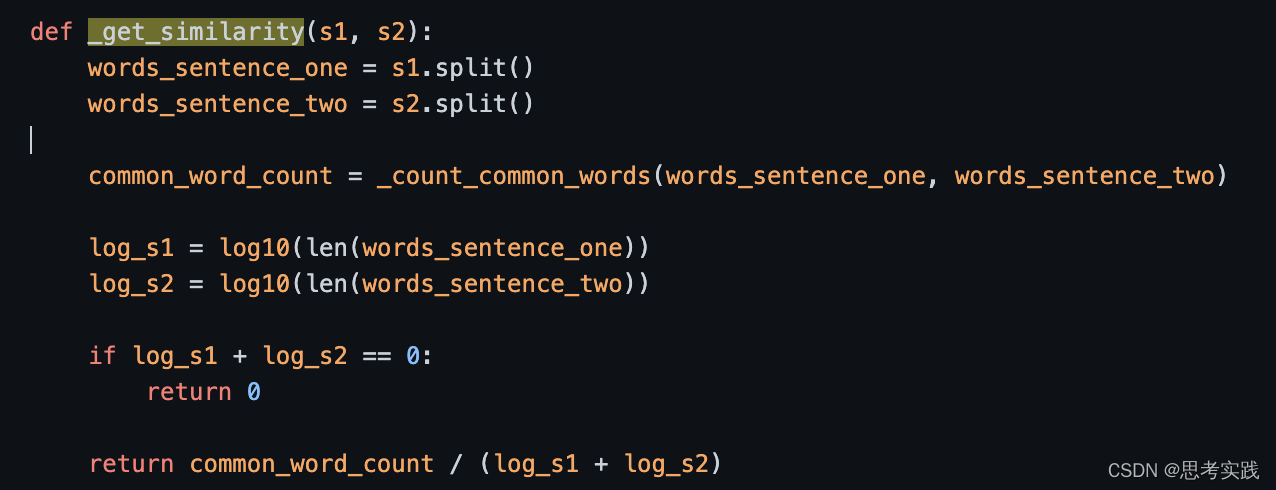
def _get_similarity(s1, s2):
words_sentence_one = s1.split()
words_sentence_two = s2.split()
common_word_count = _count_common_words(words_sentence_one, words_sentence_two)
log_s1 = log10(len(words_sentence_one))
log_s2 = log10(len(words_sentence_two))
if log_s1 + log_s2 == 0:
return 0
return common_word_count / (log_s1 + log_s2)
def _count_common_words(words_sentence_one, words_sentence_two):
return len(set(words_sentence_one) & set(words_sentence_two))
def _format_results(extracted_sentences, split, score):
if score:
return [(sentence.text, sentence.score) for sentence in extracted_sentences]
if split:
return [sentence.text for sentence in extracted_sentences]
return "\n".join([sentence.text for sentence in extracted_sentences])
def _add_scores_to_sentences(sentences, scores):
for sentence in sentences:
# Adds the score to the object if it has one.
if sentence.token in scores:
sentence.score = scores[sentence.token]
else:
sentence.score = 0
def _get_sentences_with_word_count(sentences, words):
""" Given a list of sentences, returns a list of sentences with a
total word count similar to the word count provided.
"""
word_count = 0
selected_sentences = []
# Loops until the word count is reached.
for sentence in sentences:
words_in_sentence = len(sentence.text.split())
# Checks if the inclusion of the sentence gives a better approximation
# to the word parameter.
if abs(words - word_count - words_in_sentence) > abs(words - word_count):
return selected_sentences
selected_sentences.append(sentence)
word_count += words_in_sentence
return selected_sentences
def _extract_most_important_sentences(sentences, ratio, words):
sentences.sort(key=lambda s: s.score, reverse=True)
# If no "words" option is selected, the number of sentences is
# reduced by the provided ratio.
if words is None:
length = len(sentences) * ratio
return sentences[:int(length)]
# Else, the ratio is ignored.
else:
return _get_sentences_with_word_count(sentences, words)
def summarize(text, ratio=0.2, words=None, language="english", split=False, scores=False, additional_stopwords=None):
if not isinstance(text, str):
raise ValueError("Text parameter must be a Unicode object (str)!")
# Gets a list of processed sentences.
sentences = _clean_text_by_sentences(text, language, additional_stopwords)
# Creates the graph and calculates the similarity coefficient for every pair of nodes.
graph = _build_graph([sentence.token for sentence in sentences])
_set_graph_edge_weights(graph)
# Remove all nodes with all edges weights equal to zero.
_remove_unreachable_nodes(graph)
# PageRank cannot be run in an empty graph.
if len(graph.nodes()) == 0:
return [] if split else ""
# Ranks the tokens using the PageRank algorithm. Returns dict of sentence -> score
pagerank_scores = _pagerank(graph)
# Adds the summa scores to the sentence objects.
_add_scores_to_sentences(sentences, pagerank_scores)
# Extracts the most important sentences with the selected criterion.
extracted_sentences = _extract_most_important_sentences(sentences, ratio, words)
# Sorts the extracted sentences by apparition order in the original text.
extracted_sentences.sort(key=lambda s: s.index)
return _format_results(extracted_sentences, split, scores)
def get_graph(text, language="english"):
sentences = _clean_text_by_sentences(text, language)
graph = _build_graph([sentence.token for sentence in sentences])
_set_graph_edge_weights(graph)
return graph咱们还是由表及里,深入浅出,首先分析一下summarize这个函数,text就是你的文本信息变了参数,比如咱放一个

打印结果
The design of the Olympic medals will be unveiled tonight in a live ceremony from Trafalgar Square.Over at the brand new Aquatics Centre, Britain's star diver Tom Daley is going to perform an official launch dive into the Olympic pool.With this building, the organisers have attempted to give London a landmark to rival Beijing's Water Cube from 2008.It was designed by the prestigious architect Zaha Hadid and has a wave-like roof that is 160 metres long.Today's special events are designed to arouse interest in the Olympics around the world and to encourage British fans too.Many failed to get Olympic tickets in the recent sales process.
首先清理text里面的一些东西比如不要停用词什么的,标点符号什么的。
# Gets a list of processed sentences.
sentences = _clean_text_by_sentences(text, language, additional_stopwords)
这一部分token的理解我还get不到,主要讲算法,这里的处理我就不深入了。


然后构建图给图的边赋予权重,正好应了textrank的图是有权无向边,然后通过计算每个节点(橘子)之间的相似度来赋予边的权重,下方图片中给出了相似度的计算。
# Creates the graph and calculates the similarity coefficient for every pair of nodes.
graph = _build_graph([sentence.token for sentence in sentences])
_set_graph_edge_weights(graph)

然后再使用pagerank(graph)去计算每个节点的pagerank值(这里计算出来的pagerank值也就是我们的textrank值,属于精彩部分,请待我娓娓道来),
它这里用到的是pagerank_weighted_scipy()函数,至于为什么用到这个函数,请看下面的评论与分析,论文就不带大家解读了,放在链接里,供大家下载,欢迎指教。
最后这部分代码也是理解起来不需要什么数学功底的,更多是逻辑分析的就不一一介绍了。
# Adds the summa scores to the sentence objects.
_add_scores_to_sentences(sentences, pagerank_scores)# Extracts the most important sentences with the selected criterion.
extracted_sentences = _extract_most_important_sentences(sentences, ratio, words)# Sorts the extracted sentences by apparition order in the original text.
extracted_sentences.sort(key=lambda s: s.index)return _format_results(extracted_sentences, split, scores)
分享一些链接1大家一些精彩的提问与repo_owner精彩的回答,同时这也是我的疑惑也被解决了。
第一个问题是这个仓库实现的textrank相对其他仓库比较慢,但没有说清楚基于什么标准,可能就是物理时间上的慢吧。

第二个问题,提问者也很有礼貌,也是同样我的问题,我们看第一张图里面上有sentence转化为vector这个步骤的,但这个仓库没有用这样的方法(genism用到了),owner也回答了,论文链接在这儿给出textrank paper,还有“Variations of the Similarity”,说实话,还没来得及去看。


问题3也是我的疑惑,summarize.py里面有两个函数,一个是pagerank_weighted()函数,一个是pagerank_weighted_scipy()函数,我看pagerank_weighted()这个函数的时候,首先是很高兴的因为这个函数实现的算法就是网上烂大街的公式,如下所示,但是在该包调用高级接口实现摘要的时候,summarize函数使用的确实pagerank_weighted_scipy()函数,接下来看他俩的对话就很精彩了(如图所示)。

def pagerank_weighted(graph, initial_value=None, damping=0.85):
"""Calculates PageRank for an undirected graph"""
if initial_value == None: initial_value = 1.0 / len(graph.nodes())
scores = dict.fromkeys(graph.nodes(), initial_value)
iteration_quantity = 0
for iteration_number in range(100):
iteration_quantity += 1
convergence_achieved = 0
for i in graph.nodes():
rank = 1 - damping
for j in graph.neighbors(i):
neighbors_sum = sum(graph.edge_weight((j, k)) for k in graph.neighbors(j))
rank += damping * scores[j] * graph.edge_weight((j, i)) / neighbors_sum
if abs(scores[i] - rank) <= CONVERGENCE_THRESHOLD:
convergence_achieved += 1
scores[i] = rank
if convergence_achieved == len(graph.nodes()):
break
return scoresdef pagerank_weighted_scipy(graph, damping=0.85):
adjacency_matrix = build_adjacency_matrix(graph)
probability_matrix = build_probability_matrix(graph)
# Suppress deprecation warnings from numpy.
# See https://github.com/summanlp/textrank/issues/57
import warnings
with warnings.catch_warnings():
from numpy import VisibleDeprecationWarning
warnings.filterwarnings("ignore", category=VisibleDeprecationWarning)
warnings.filterwarnings("ignore", category=PendingDeprecationWarning)
pagerank_matrix = damping * adjacency_matrix.todense() + (1 - damping) * probability_matrix
vals, vecs = eig(pagerank_matrix, left=True, right=False)
return process_results(graph, vecs)
参考资料:
GitHub - summanlp/textrank: TextRank implementation for Python 3.
TextRank算法的基本原理及textrank4zh使用实例_wotui1842的博客-CSDN博客_textrank算法
TextRank算法详细讲解与代码实现(完整) - 方格田 - 博客园
问题2两篇关于链接1仓库实现的论文基础
https://aclanthology.org/W04-3252.pdf
https://arxiv.org/pdf/1602.03606.pdf
问题2链接
summa vs gensim · Issue #78 · summanlp/textrank · GitHub
问题3关于马尔可夫矩阵与特征向量在算法里面的应用与证明
这俩不是一个链接虽然名字一样,一个是马尔可夫链关于特征值是1的理论证明,一个是基于该理论应用在pagerank里面的理论的证明,这都是standford学校的资料证明,确实也说明了名校的底蕴是摆在这儿了。
The Markov transform matrix is a stochastic matrix. The Perron–Frobenius theorem ensures that every irreducible stochastic matrix has a stationary vector, and that the largest absolute value of an eigenvalue is always 1.You can find explanations of the proof in the two previous links or just google more simplified explanations.Thank you for your interest!
这是节选的owner的一段回答让我感受很深,就比如你要通过很多次迭代计算的值一个数学理论就能让你一步完成,好比1+···+50的等差数列求和用求和公式就能完成。
问题3链接
Why did not you use iterative method here? · Issue #77 · summanlp/textrank · GitHub















 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









