







项目地址:agentica-project/deepscaler: Democratizing Reinforcement Learning for LLMs
数据集:agentica-org/DeepScaleR-Preview-Dataset · Datasets at Hugging Face
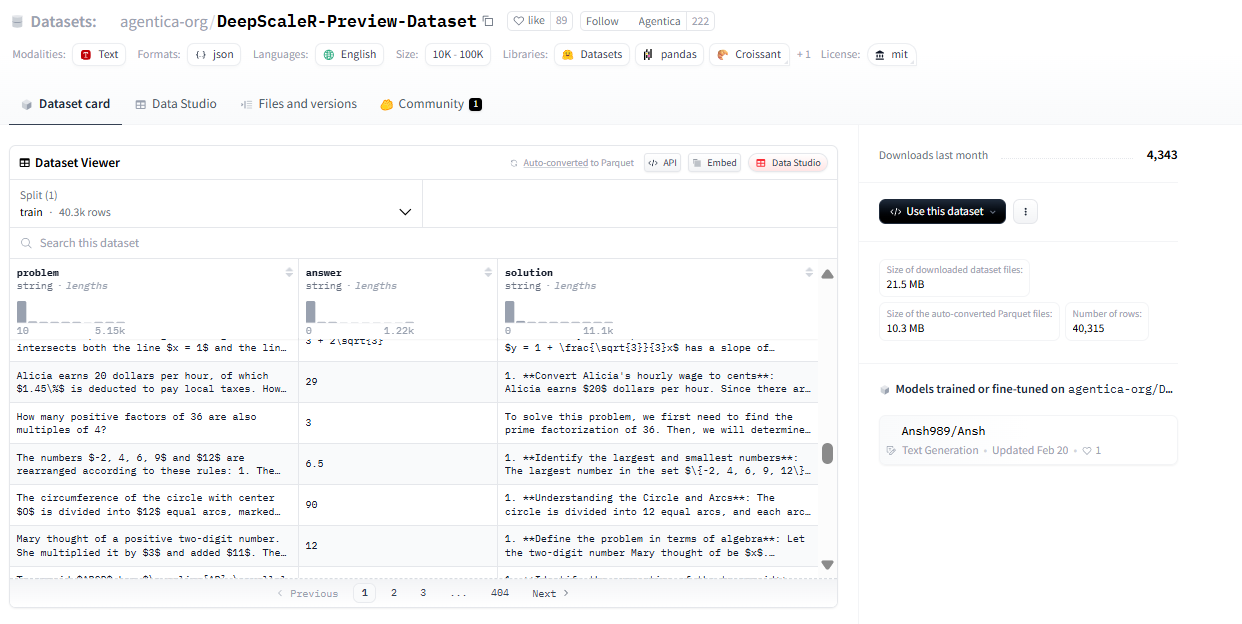
训练集大约40.3k条
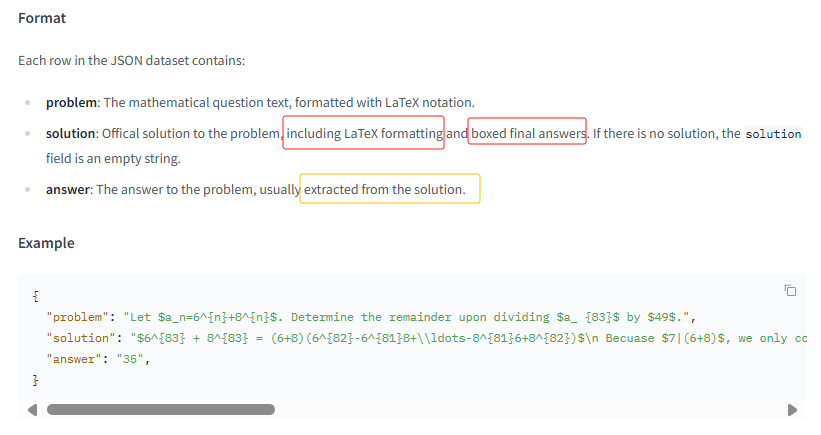
Problem || Answers || Solutions # DeepScaleR用的ORM而非PRM,通过final result来奖励
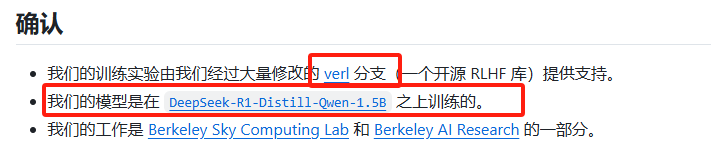
看来训练推理框架都脱离不开Verl


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









