






本文发表于ICCV2023,提出了一种单目自监督深度估计方法。
摘要:

动机:
在本文中,发现自监督单目深度估计在特征表示中具有方向敏感性和环境依赖性。而目前的方法较少的考虑了环境信息。
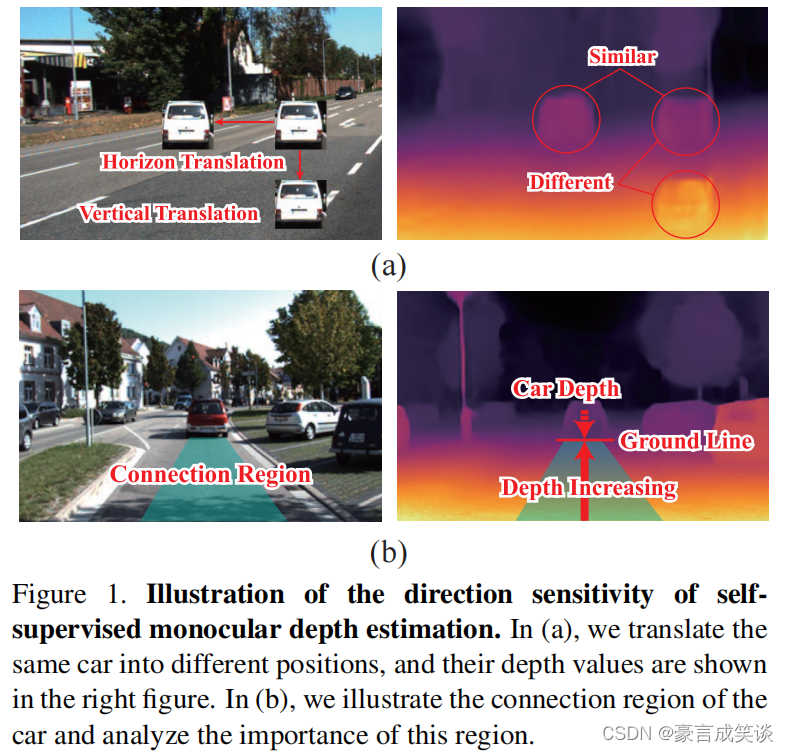
如图所示,作者将一张汽车的照片,分别放在一张图的不同位置,其深度值在右图中可视化。这里的深度值就是如果这里有一辆车,其实际的深度值。
从可视化结果中,我们发现,即使是相同的像素,这些处于不同位置的对象也拥有不同的深度值。这表明,深度预测依赖于物体的环境。进一步观察到,水平平移的物体与原始物体的深度差异很小,但垂直平移的物体的深度变化很大。基于这些观察结果,我们推断出来自不同方向的信息在深度估计中起着不同的作用。沿着视图线的信息对深度变化的贡献更大,而来自水平线的信息保持了对象之间的深度一致性。因此,从每个方向上提取的特征可以显示出不同的偏好。
之前的工作表明,增加输入分辨率将有助于详细的信息提取,而一个小的分辨率有助于全局信息编码。
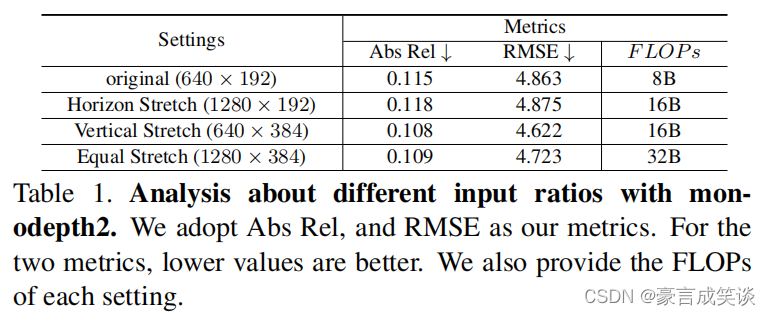
作者这里就做了一个实验,分别在不同方向上拉伸图片,然后用之前的方法(monodepth2)去估计深度,发现:
在水平方向拉伸图片,深度估计的结果变差;而在垂直方向上拉伸图片,结果会变好,结合前面的结论,较小的分辨率更有助于提取全局信息,因此得出:水平方向上提取全局信息更加重要,而垂直方向的详细信息对深度估计的性能更加重要。
作者推断出,连接区域的信息是深度估计的重要线索。如图1(b)所示,地线是汽车[深度估计的关键参考,而地线的深度很大程度上依赖于它与相机之间的区域,本文称为连接区域。
然后作者提到了传统卷积的局限性(传统的卷积网络通常对每个方向都有相同的接受域,并对其信息进行类似的编码。这将导致降低提取各种类型的特征的效率。此外,卷积运算同样地将来自接受域的信息聚集到中心位置。这种聚合策略不能有效地利用在连接区域中编码的关键信息。)实际上我认为提到的这些局限性可以通过修改卷积核和步长的参数来解决,而文章中并没有提到。
接下来看本文是如何解决这些问题的。
方法
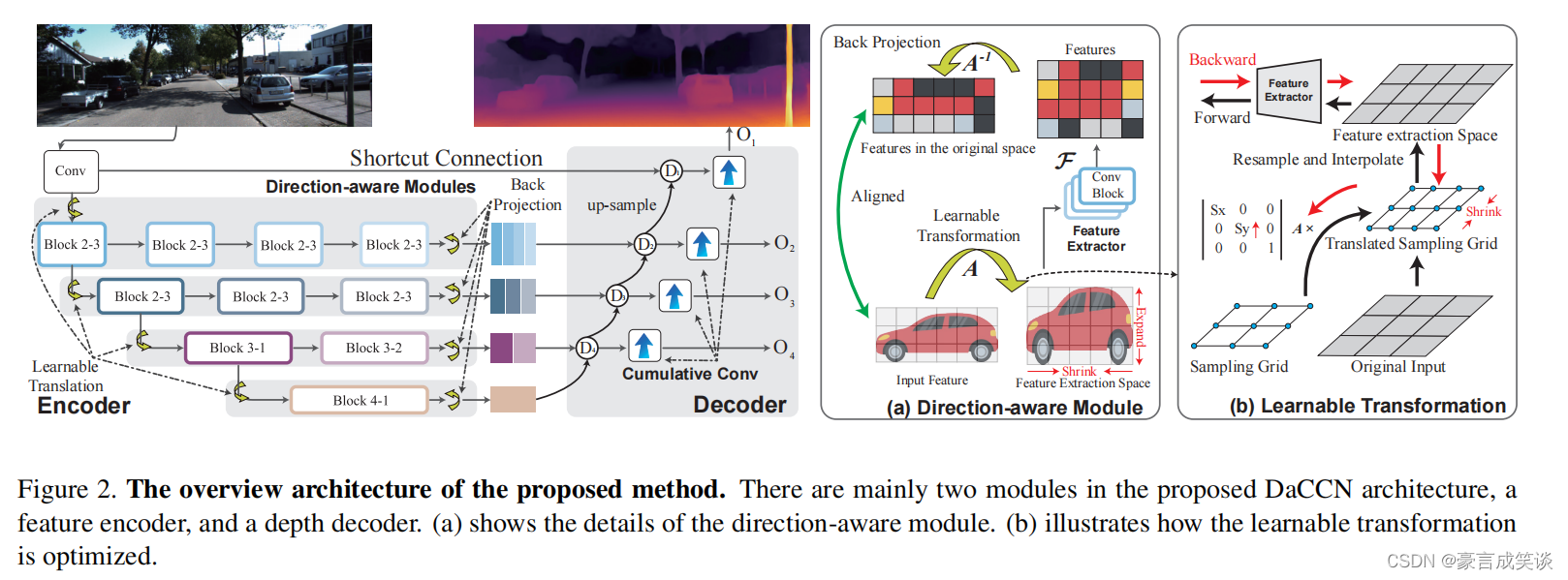
看网络结构图可以看出,这是一个类似UNet的结构,特别的是编码之前有个可学习的变换,对应的在解码端需要进行一个反向的变换。另外作者提出了cumulative卷积。方向感知模块和cumulative卷积是本文主要改进点。
方向感知特征提取
如图2所示,方向感知模块分为三个部分,仿射变换A,特征提取卷积,和逆变换A-1,这里变换矩阵A是一个可学习的参数。
这里,作者还比较了其和可变形卷积,可变形的卷积通过预测卷积核的偏移量来学习从不同的位置提取特征。它的设计是为了有效地从不同形状的物体中提取特征,但在此过程中不能调整样本密度。相比之下,方向感知模块可以改变每个方向的样本密度,更适合于提取不同类型的特征。采样密度定义为从输入图像的单位面积中提取的特征向量的数量。
采样密度决定了提取特征的详细程度。
累积卷积
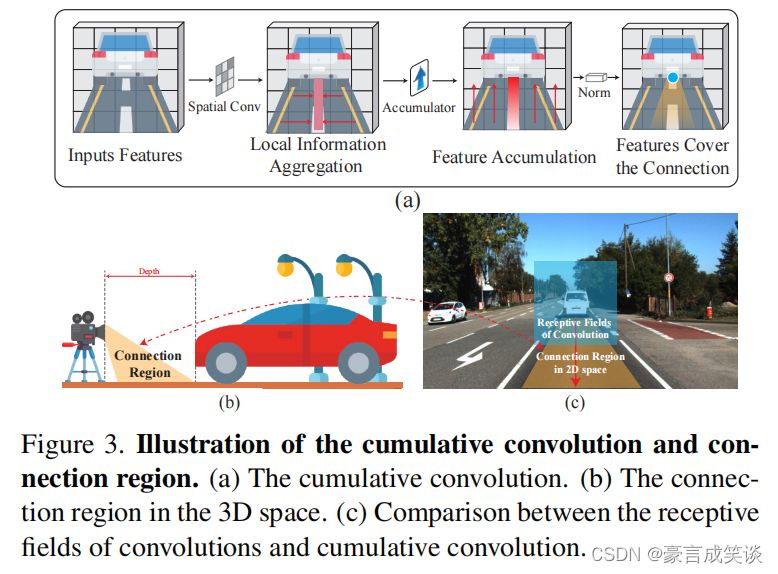
出发点:更好的特征提取的单目深度估计应该充分利用来自连接区域的信息。连接区域是指相机和物体之间的区域,该区域的深度较小,并且通常位于物体的底部。一般的卷积则只能感受(c)中蓝色方块中的信息,这一般是不够的。
如图3所示,其实现方法也比较简单,就是从底部求和然后平均。
这一部分的先验是比较强的,如果将图片旋转,或者拍摄的角度发生变化,这里的假设都不再正确。
损失函数
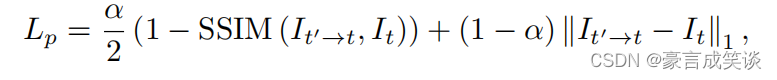

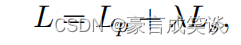
比较简单,重投影的颜色损失和深度梯度损失。
实验
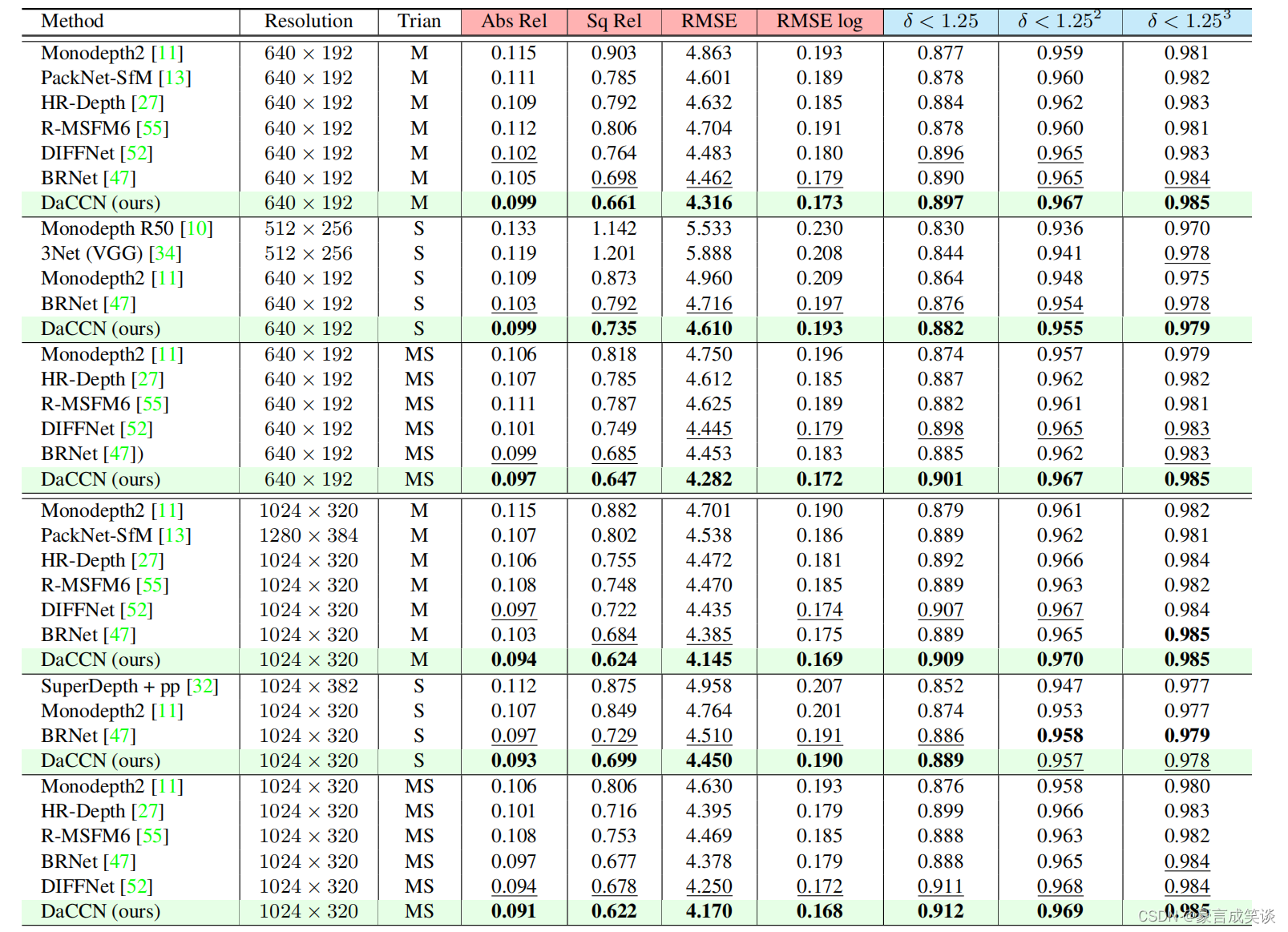

方向感知的模块的贡献更大
















 8751
8751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









