










学习MSCKF笔记——前端、图像金字塔光流、Two Point Ransac
学习MSCKF笔记——前端、图像金字塔光流、Two Point Ransac
前段时间开始工作了,刚开始有点忙得缓不过来,调整了两三个月后总算有时间了,可以继续学点自己感兴趣的东西,写写博客。之前研究过一段时间VINS-Mono,那是一个后端优化框架的VIO,而MSCKF是基于滤波的框架,对于嵌入式平台会更加友好,因此想花点时间再学习下。目前我仅仅看了一遍paper,过了一遍代码,以及学习了几位前辈优秀的博客:
一步步深入了解S-MSCKF
MSCKF那些事(一)MSCKF算法简介
还有深蓝学院吴博的课程,我的这篇博客主要是我自己学习过程中的笔记,参考内容主要如上。
我学习的代码是msckf_vio,代码写得非常简介明了,读代码可以比较容易地总结出前端算法的流程图如下:
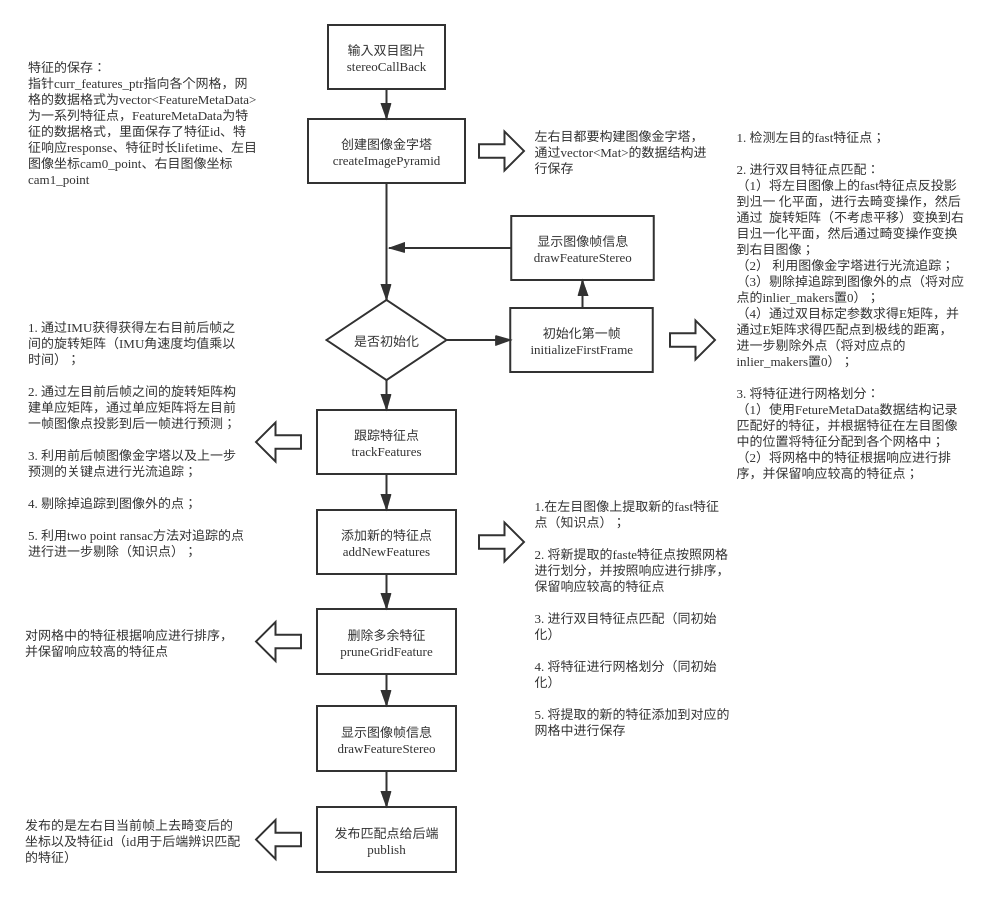
这里我主要对代码中的几个细节进行简单分析,包括图像金字塔光流、Two Point Ransac算法、新Fast特征点提取
1. 图像金字塔光流
光流法我们再熟悉不过了,MSCKF为了节省计算量,在图像输入时就对图像进行了金字塔操作,那么金字塔光流是如何实现的,收益是怎样的,下面先对金字塔光流进行推导。金字塔光流的参考论文为Pyramidal Implementation of the Lucas Kanade Feature Tracker Description of the algorithm.
我们知道光流法最基本的原理如下:
I
(
x
+
Δ
x
,
y
+
Δ
y
,
t
+
Δ
t
)
−
I
(
x
,
y
,
t
)
=
∂
I
∂
x
Δ
x
+
∂
I
∂
y
Δ
y
+
∂
I
∂
t
Δ
t
I(x+\Delta x, y+\Delta y, t+\Delta t) - I(x, y, t)=\frac{\partial I}{\partial x} \Delta x+\frac{\partial I}{\partial y} \Delta y+\frac{\partial I}{\partial t} \Delta t
I(x+Δx,y+Δy,t+Δt)−I(x,y,t)=∂x∂IΔx+∂y∂IΔy+∂t∂IΔt当
Δ
t
\Delta t
Δt足够小时,有
−
∂
I
∂
t
=
∂
I
∂
x
d
x
d
t
+
∂
I
∂
y
d
y
d
t
=
∂
I
∂
x
u
+
∂
I
∂
y
v
-\frac{\partial I}{\partial t}=\frac{\partial I}{\partial x} \frac{d x}{d t}+\frac{\partial I}{\partial y} \frac{d y}{d t}=\frac{\partial I}{\partial x} u+\frac{\partial I}{\partial y} v
−∂t∂I=∂x∂Idtdx+∂y∂Idtdy=∂x∂Iu+∂y∂Iv即
−
I
t
=
[
I
x
I
y
]
[
u
v
]
-I_{t}=\left[\begin{array}{ll} I_{x} & I_{y} \end{array}\right]\left[\begin{array}{l} u \\ v \end{array}\right]
−It=[IxIy][uv]其中
I
x
,
I
y
I_x,I_y
Ix,Iy为像素梯度,
u
,
v
u, v
u,v为像素运动速度,是我们要求的未知量。一个约束方程无法求解二元方程,因此就诞生Lucas-Kanade光流,假定邻域像素具备运动一致性,取邻域像素进计算求解:
{
I
1
x
u
+
I
1
y
v
=
−
I
1
t
I
2
x
u
+
I
2
y
v
=
−
I
2
t
⋯
I
n
x
u
+
I
n
y
v
=
−
I
n
\left\{\begin{array}{l} I_{1 x} u+I_{1 y} v=-I_{1 t} \\ I_{2 x} u+I_{2 y} v=-I_{2 t} \\ \cdots \\ I_{n x} u+I_{n y} v=-I_{n} \end{array}\right.
⎩⎪⎪⎨⎪⎪⎧I1xu+I1yv=−I1tI2xu+I2yv=−I2t⋯Inxu+Inyv=−In令
A
=
[
[
I
x
,
I
y
]
1
⋮
[
I
x
,
I
y
]
k
]
,
b
=
[
I
t
1
⋮
I
t
k
]
\boldsymbol{A}=\left[\begin{array}{c} {\left[{I}_{x}, {I}_{y}\right]_{1}} \\ \vdots \\ {\left[{I}_{x}, {I}_{y}\right]_{k}} \end{array}\right], \boldsymbol{b}=\left[\begin{array}{c} {I}_{t 1} \\ \vdots \\ {I}_{t k} \end{array}\right]
A=⎣⎢⎡[Ix,Iy]1⋮[Ix,Iy]k⎦⎥⎤,b=⎣⎢⎡It1⋮Itk⎦⎥⎤于是有
[
u
v
]
∗
=
−
(
A
T
A
)
−
1
A
T
b
\left[\begin{array}{c} u \\ v \end{array}\right]^{*}=-\left(\boldsymbol{A}^{T} \boldsymbol{A}\right)^{-1} \boldsymbol{A}^{T} \boldsymbol{b}
[uv]∗=−(ATA)−1ATb由于Lucas-Kanada光流取的是邻域像素,如果像素运动过快超出邻域就无法满足以上假设了,因此就诞生了金字塔光流法:使用低分辨率的图片来估计高分辨率图片像素的运动趋势。
首先是构建高斯金字塔,所谓高斯金字塔就是通过高斯下采样构建的,如下图所示:

高斯下采样可以理解为先进行高斯模糊,再进行下采样的操作,通过高斯下采样图像尺寸为原尺寸的一半,原始图片在最底层(第0层),分辨率最低的图片在最顶层(第
L
m
L_m
Lm层)。我们假设第
L
L
L层的光流的估计的某个像素的位移为
g
L
g^L
gL(估计值),那么第
L
−
1
L-1
L−1层的光流估计的该像素的位移为:
g
L
−
1
=
2
(
g
L
+
d
L
)
g^{L-1} = 2 (g^{L}+d^{L})
gL−1=2(gL+dL)其中
d
L
d^L
dL为根据第
L
−
1
L-1
L−1层图像求得的修正量(修正值),具体的推到过程如下所示:
我们首先定义第
L
L
L层像素邻域范围内的匹配误差和如下:
ϵ
L
(
d
L
)
=
ϵ
L
(
d
x
L
,
d
y
L
)
=
∑
x
=
u
x
L
−
ω
x
u
x
L
+
ω
x
∑
y
=
u
y
L
−
ω
y
u
v
L
+
ω
y
(
I
L
(
x
,
y
)
−
J
L
(
x
+
g
x
L
+
d
x
L
,
y
+
g
y
L
+
d
y
L
)
)
2
\epsilon^{L}\left({d}^{L}\right)=\epsilon^{L}\left(d_{x}^{L}, d_{y}^{L}\right)=\sum_{x=u_{x}^{L}-\omega_{x}}^{u_{x}^{L}+\omega_{x}} \sum_{y=u_{y}^{L}-\omega_{y}}^{u_{v}^{L}+\omega_{y}}\left(I^{L}(x, y)-J^{L}\left(x+g_{x}^{L}+d_{x}^{L}, y+g_{y}^{L}+d_{y}^{L}\right)\right)^{2}
ϵL(dL)=ϵL(dxL,dyL)=x=uxL−ωx∑uxL+ωxy=uyL−ωy∑uvL+ωy(IL(x,y)−JL(x+gxL+dxL,y+gyL+dyL))2其中,
I
I
I和
J
J
J是前后两帧不同的图像,
g
x
L
,
g
y
L
g^L_x,g^L_y
gxL,gyL是由上一层光流的估计值(
g
x
L
=
2
(
d
x
L
+
1
+
d
x
L
+
1
)
,
g
y
L
=
2
(
g
x
L
+
1
+
d
y
L
+
1
)
g^L_x=2(d^{L+1}_x+d^{L+1}_x),g^L_y= 2(g^{L+1}_x+d^{L+1}_y)
gxL=2(dxL+1+dxL+1),gyL=2(gxL+1+dyL+1)),
d
x
L
,
d
y
L
d^L_x,d^L_y
dxL,dyL为当前层我们要求的的修正值。且我们假设最顶层(第
L
m
L_m
Lm层)的光流估计的估计值为
g
L
m
=
[
0
0
]
T
{g}^{L_{m}}=\left[\begin{array}{ll} 0 & 0 \end{array}\right]^{T}
gLm=[00]T接下来为了推到的方便,我们对上面的匹配误差和损失函数进行重写,令
∀
(
x
,
y
)
∈
[
p
x
−
ω
x
−
1
,
p
x
+
ω
x
+
1
]
×
[
p
y
−
ω
y
−
1
,
p
y
+
ω
y
+
1
]
,
A
(
x
,
y
)
≐
I
L
(
x
,
y
)
\forall(x, y) \in\left[p_{x}-\omega_{x}-1, p_{x}+\omega_{x}+1\right] \times\left[p_{y}-\omega_{y}-1, p_{y}+\omega_{y}+1\right], A(x, y) \doteq I^{L}(x, y)
∀(x,y)∈[px−ωx−1,px+ωx+1]×[py−ωy−1,py+ωy+1],A(x,y)≐IL(x,y)
∀
(
x
,
y
)
∈
[
p
x
−
ω
x
,
p
x
+
ω
x
]
×
[
p
y
−
ω
y
,
p
y
+
ω
y
]
,
B
(
x
,
y
)
≐
J
L
(
x
+
g
x
L
,
y
+
g
y
L
)
\forall(x, y) \in\left[p_{x}-\omega_{x}, p_{x}+\omega_{x}\right] \times\left[p_{y}-\omega_{y}, p_{y}+\omega_{y}\right], B(x, y) \doteq J^{L}\left(x+g_{x}^{L}, y+g_{y}^{L}\right)
∀(x,y)∈[px−ωx,px+ωx]×[py−ωy,py+ωy],B(x,y)≐JL(x+gxL,y+gyL)
ν
‾
=
[
ν
x
,
ν
y
]
T
=
d
L
\overline{{\nu}}=\left[\nu_{x}, \nu_{y}\right]^{T}=\mathrm{d}^{L}
ν=[νx,νy]T=dL那么我们要求的损失函数可以写为:
ε
(
ν
ˉ
)
=
ε
(
ν
x
,
ν
y
)
=
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
(
A
(
x
,
y
)
−
B
(
x
+
ν
x
,
y
+
ν
y
)
)
2
\varepsilon(\bar{\nu})=\varepsilon\left(\nu_{x}, \nu_{y}\right)=\sum_{x=p_{x}-\omega_{x}}^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left(A(x, y)-B\left(x+\nu_{x}, y+\nu_{y}\right)\right)^{2}
ε(νˉ)=ε(νx,νy)=x=px−ωx∑px+ωxy=py−ωy∑py+ωy(A(x,y)−B(x+νx,y+νy))2为了最小化损失函数,我们对损失函数进行求导:
∂
ε
(
ν
ˉ
)
∂
ν
ˉ
=
−
2
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
(
A
(
x
,
y
)
−
B
(
x
+
ν
x
,
y
+
ν
y
)
)
⋅
[
∂
B
∂
x
∂
B
∂
y
]
\frac{\partial \varepsilon(\bar{\nu})}{\partial \bar{\nu}}=-2 \sum_{x=p_{x}-\omega_{x}}^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left(A(x, y)-B\left(x+\nu_{x}, y+\nu_{y}\right)\right) \cdot\left[\begin{array}{cc} \frac{\partial B}{\partial x} & \frac{\partial B}{\partial y} \end{array}\right]
∂νˉ∂ε(νˉ)=−2x=px−ωx∑px+ωxy=py−ωy∑py+ωy(A(x,y)−B(x+νx,y+νy))⋅[∂x∂B∂y∂B]然后我们对
B
(
x
+
ν
x
,
y
+
ν
y
)
B\left(x+\nu_{x}, y+\nu_{y}\right)
B(x+νx,y+νy)进行泰勒展开,有:
∂
ε
(
ν
ˉ
)
∂
ν
ˉ
≈
−
2
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
(
A
(
x
,
y
)
−
B
(
x
,
y
)
−
[
∂
B
∂
x
∂
B
∂
y
]
ν
ˉ
)
⋅
[
∂
B
∂
x
∂
B
∂
y
]
\frac{\partial \varepsilon(\bar{\nu})}{\partial \bar{\nu}} \approx-2 \sum_{x=p_{x}-\omega_{x} }^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left(A(x, y)-B(x, y)-\left[\begin{array}{cc} \frac{\partial B}{\partial x} & \frac{\partial B}{\partial y} \end{array}\right] \bar{\nu}\right) \cdot\left[\begin{array}{cc} \frac{\partial B}{\partial x} & \frac{\partial B}{\partial y} \end{array}\right]
∂νˉ∂ε(νˉ)≈−2x=px−ωx∑px+ωxy=py−ωy∑py+ωy(A(x,y)−B(x,y)−[∂x∂B∂y∂B]νˉ)⋅[∂x∂B∂y∂B]接下来,我们令:
δ
I
(
x
,
y
)
≐
A
(
x
,
y
)
−
B
(
x
,
y
)
\delta I(x, y) \doteq A(x, y)-B(x, y)
δI(x,y)≐A(x,y)−B(x,y)
∇
I
=
[
I
x
I
y
]
≐
[
∂
B
∂
x
∂
B
∂
y
]
T
\nabla I=\left[\begin{array}{l} I_{x} \\ I_{y} \end{array}\right] \doteq\left[\begin{array}{cc} \frac{\partial B}{\partial x} & \frac{\partial B}{\partial y} \end{array}\right]^{T}
∇I=[IxIy]≐[∂x∂B∂y∂B]T其中
I
x
(
x
,
y
)
=
∂
A
(
x
,
y
)
∂
x
=
A
(
x
+
1
,
y
)
−
A
(
x
−
1
,
y
)
2
I_{x}(x, y)=\frac{\partial A(x, y)}{\partial x}=\frac{A(x+1, y)-A(x-1, y)}{2}
Ix(x,y)=∂x∂A(x,y)=2A(x+1,y)−A(x−1,y)
I
y
(
x
,
y
)
=
∂
A
(
x
,
y
)
∂
y
=
A
(
x
,
y
+
1
)
−
A
(
x
,
y
−
1
)
2
I_{y}(x, y)=\frac{\partial A(x, y)}{\partial y}=\frac{A(x, y+1)-A(x, y-1)}{2}
Iy(x,y)=∂y∂A(x,y)=2A(x,y+1)−A(x,y−1)
因此有
1
2
∂
ε
(
ν
ˉ
)
∂
ν
ˉ
≈
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
(
∇
I
T
ν
ˉ
−
δ
I
)
∇
I
T
\frac{1}{2} \frac{\partial \varepsilon(\bar{\nu})}{\partial \bar{\nu}} \approx \sum_{x=p_{x}-\omega_{x}}^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left(\nabla I^{T} \bar{\nu}-\delta I\right) \nabla I^{T}
21∂νˉ∂ε(νˉ)≈x=px−ωx∑px+ωxy=py−ωy∑py+ωy(∇ITνˉ−δI)∇IT将具体参数代入得:
1
2
[
∂
ε
(
ν
ˉ
)
∂
ν
ˉ
]
T
≈
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
(
[
I
x
2
I
x
I
y
I
x
I
y
I
y
2
]
ν
ˉ
−
[
δ
I
I
x
δ
I
I
y
]
)
\frac{1}{2}\left[\frac{\partial \varepsilon(\bar{\nu})}{\partial \bar{\nu}}\right]^{T} \approx \sum_{x=p_{x}-\omega_{x}}^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left(\left[\begin{array}{cc} I_{x}^{2} & I_{x} I_{y} \\ I_{x} I_{y} & I_{y}^{2} \end{array}\right] \bar{\nu}-\left[\begin{array}{c} \delta I I_{x} \\ \delta I I_{y} \end{array}\right]\right)
21[∂νˉ∂ε(νˉ)]T≈x=px−ωx∑px+ωxy=py−ωy∑py+ωy([Ix2IxIyIxIyIy2]νˉ−[δIIxδIIy])令
G
≐
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
[
I
x
2
I
x
I
y
I
x
I
y
I
y
2
]
G \doteq \sum_{x=p_{x}-\omega_{x}}^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left[\begin{array}{cc} I_{x}^{2} & I_{x} I_{y} \\ I_{x} I_{y} & I_{y}^{2} \end{array}\right]
G≐x=px−ωx∑px+ωxy=py−ωy∑py+ωy[Ix2IxIyIxIyIy2]
b
ˉ
≐
∑
x
=
p
x
−
ω
x
p
x
+
ω
x
∑
y
=
p
y
−
ω
y
p
y
+
ω
y
[
δ
I
I
x
δ
I
I
y
]
\bar{b} \doteq \sum_{x=p_{x}-\omega_{x}}^{p_{x}+\omega_{x}} \sum_{y=p_{y}-\omega_{y}}^{p_{y}+\omega_{y}}\left[\begin{array}{c} \delta I I_{x} \\ \delta I I_{y} \end{array}\right]
bˉ≐x=px−ωx∑px+ωxy=py−ωy∑py+ωy[δIIxδIIy]
则有
1
2
[
∂
ε
(
ν
ˉ
)
∂
ν
ˉ
]
T
≈
G
ν
ˉ
−
b
ˉ
\frac{1}{2}\left[\frac{\partial \varepsilon(\bar{\nu})}{\partial \bar{\nu}}\right]^{T} \approx G \bar{\nu}-\bar{b}
21[∂νˉ∂ε(νˉ)]T≈Gνˉ−bˉ那我们最终要求的
ν
ˉ
\bar{\nu}
νˉ为:
ν
ˉ
=
G
−
1
b
ˉ
\bar{\nu}=G^{-1} \bar{b}
νˉ=G−1bˉ这实际上就是求出了第
L
L
L层图像的修正量
d
L
d^L
dL,结合估计值
g
L
g^L
gL就可以求出来下一层的估计值
g
L
−
1
g^{L-1}
gL−1,直到求导最底层,也就是我们原始图片的估计值。
2. Two Point Ransac算法
Two Point Ransac算是是原文作者提出来的一个新算法,算法的目的时在前后帧跟踪特征点时是筛选出前后帧匹配的outliers,在执行Two Point Ransac之前,先对当前帧追踪到的特征点进行双目匹配,去除掉一部分不满足双目极限约束的特征点。可以看到,虽然用的是双目相机,但是只对左目使用了光流法进行特征追踪,因此接下来的Two Point Ransac是对左右目共同使用的。
Two Point Ransc的流程是先通过IMU角速度均值乘以时间获得的前后帧旋转矩阵
R
R
R,然后通过旋转矩阵
R
R
R将上一帧的特征点投影到当前帧,这时上一帧的特征点和当前帧匹配的特征点之间就差一个平移
t
t
t,用公式描述如下:
首先前后两帧之间的匹配点满足极线约束:
p
2
T
⋅
[
t
]
x
⋅
R
⋅
p
1
=
0
p_{2}^{T} \cdot[t]_{x} \cdot R \cdot p_{1}=0
p2T⋅[t]x⋅R⋅p1=0,通过旋转矩阵
R
R
R将前一帧特征点投影到当前帧之后坐标分别为:
R
⋅
p
1
=
[
x
1
y
1
1
]
T
,
p
2
=
[
x
2
y
2
1
]
T
R \cdot p_{1}=\left[\begin{array}{lll} x 1 & y 1 & 1 \end{array}\right]^{T}, p_{2}=\left[\begin{array}{lll} x 2 & y 2 & 1 \end{array}\right]^{T}
R⋅p1=[x1y11]T,p2=[x2y21]T,那么满足
[
x
2
y
2
1
]
⋅
[
0
−
t
z
t
y
t
z
0
−
t
x
−
t
y
t
x
0
]
⋅
[
x
1
y
1
1
]
=
0
\left[\begin{array}{ccc} x_{2} & y_{2} & 1 \end{array}\right] \cdot\left[\begin{array}{ccc} 0 & -t_{z} & t_{y} \\ t_{z} & 0 & -t_{x} \\ -t_{y} & t_{x} & 0 \end{array}\right] \cdot\left[\begin{array}{c} x_{1} \\ y_{1} \\ 1 \end{array}\right]=0
[x2y21]⋅⎣⎡0tz−ty−tz0txty−tx0⎦⎤⋅⎣⎡x1y11⎦⎤=0对其进行展开后
[
y
1
−
y
2
−
(
x
1
−
x
2
)
x
1
y
2
−
x
2
y
2
]
⋅
[
t
x
t
y
t
z
]
=
0
\left[\begin{array}{lll} y_{1}-y_{2} & -\left(x_{1}-x_{2}\right) & x_{1} y_{2}-x_{2} y_{2} \end{array}\right] \cdot\left[\begin{array}{l} t_{x} \\ t_{y} \\ t_{z} \end{array}\right]=0
[y1−y2−(x1−x2)x1y2−x2y2]⋅⎣⎡txtytz⎦⎤=0由于误差的存在,并不是所有匹配的特征点都会满足上面的等式,我们考虑两个点的情况有:
[
y
1
−
y
2
−
(
x
1
−
x
2
)
x
1
y
2
−
x
2
y
2
y
3
−
y
4
−
(
x
3
−
x
4
)
x
3
y
4
−
x
4
y
3
]
⋅
[
t
x
t
y
t
z
]
=
[
A
x
A
y
A
z
]
T
⋅
[
t
x
t
y
t
z
]
≈
[
0
0
]
\left[\begin{array}{ccc} y_{1}-y_{2} & -\left(x_{1}-x_{2}\right) & x_{1} y_{2}-x_{2} y_{2} \\ y_{3}-y_{4} & -\left(x_{3}-x_{4}\right) & x_{3} y_{4}-x_{4} y_{3} \end{array}\right] \cdot\left[\begin{array}{c} t_{x} \\ t_{y} \\ t_{z} \end{array}\right]=\left[\begin{array}{c} A_{x} \\ A_{y} \\ A_{z} \end{array}\right]^{T} \cdot\left[\begin{array}{c} t_{x} \\ t_{y} \\ t_{z} \end{array}\right] \approx\left[\begin{array}{l} 0 \\ 0 \end{array}\right]
[y1−y2y3−y4−(x1−x2)−(x3−x4)x1y2−x2y2x3y4−x4y3]⋅⎣⎡txtytz⎦⎤=⎣⎡AxAyAz⎦⎤T⋅⎣⎡txtytz⎦⎤≈[00]平移向量有三个变量,两个点是无法求解的,因此将上面的式子拆解成如下三个式子:
[
A
x
A
y
]
T
⋅
[
t
x
t
y
]
≈
A
z
⋅
t
z
[
A
x
A
z
]
T
⋅
[
t
x
t
z
]
≈
A
y
⋅
t
y
[
A
y
A
z
]
T
⋅
[
t
y
t
z
]
≈
A
x
⋅
t
x
\begin{array}{l} {\left[\begin{array}{c} A_{x} \\ A_{y} \end{array}\right]^{T} \cdot\left[\begin{array}{l} t_{x} \\ t_{y} \end{array}\right] \approx A_{z} \cdot t_{z}} \\ {\left[\begin{array}{c} A_{x} \\ A_{z} \end{array}\right]^{T} \cdot\left[\begin{array}{c} t_{x} \\ t_{z} \end{array}\right] \approx A_{y} \cdot t_{y}} \\ {\left[\begin{array}{c} A_{y} \\ A_{z} \end{array}\right]^{T} \cdot\left[\begin{array}{c} t_{y} \\ t_{z} \end{array}\right] \approx A_{x} \cdot t_{x}} \end{array}
[AxAy]T⋅[txty]≈Az⋅tz[AxAz]T⋅[txtz]≈Ay⋅ty[AyAz]T⋅[tytz]≈Ax⋅tx并添加尺度约束
{
if
t
x
<
t
y
&
&
t
x
<
t
z
,
then
t
x
=
1
[
−
(
x
−
x
′
)
,
(
x
y
′
−
x
′
y
)
]
[
t
y
t
z
]
=
−
(
y
−
y
′
)
{
if
t
y
<
t
x
&
&
t
y
<
t
z
,
then
t
y
=
1
[
(
y
−
y
′
)
,
(
x
y
′
−
x
′
y
)
]
[
t
x
t
z
]
=
(
x
−
x
′
)
{
if
t
z
<
t
x
&
&
t
z
<
t
y
,
then
t
z
=
1
[
(
y
−
y
′
)
,
−
(
x
−
x
′
)
]
[
t
x
t
y
]
=
−
(
x
y
′
−
x
′
y
)
\begin{aligned} &\left\{\begin{array}{l} \text { if } t_{x}<t_{y} \& \& t_{x}<t_{z}, \text { then } t_{x}=1 \\ {\left[-\left(x-x^{\prime}\right),\left(x y^{\prime}-x^{\prime} y\right)\right]\left[\begin{array}{c} t_{y} \\ t_{z} \end{array}\right]=-\left(y-y^{\prime}\right)} \end{array}\right.\\ &\left\{\begin{array}{l} \text { if } t_{y}<t_{x} \& \& t_{y}<t_{z}, \quad \text { then } t_{y}=1 \\ {\left[\left(y-y^{\prime}\right),\left(x y^{\prime}-x^{\prime} y\right)\right]\left[\begin{array}{c} t_{x} \\ t_{z} \end{array}\right]=\left(x-x^{\prime}\right)} \end{array}\right.\\ &\left\{\begin{array}{l} \text { if } t_{z}<t_{x} \& \& t_{z}<t_{y}, \quad \text { then } t_{z}=1 \\ {\left[\left(y-y^{\prime}\right),-\left(x-x^{\prime}\right)\right]\left[\begin{array}{c} t_{x} \\ t_{y} \end{array}\right]=-\left(x y^{\prime}-x^{\prime} y\right)} \end{array}\right. \end{aligned}
⎩⎨⎧ if tx<ty&&tx<tz, then tx=1[−(x−x′),(xy′−x′y)][tytz]=−(y−y′)⎩⎨⎧ if ty<tx&&ty<tz, then ty=1[(y−y′),(xy′−x′y)][txtz]=(x−x′)⎩⎨⎧ if tz<tx&&tz<ty, then tz=1[(y−y′),−(x−x′)][txty]=−(xy′−x′y)
根据上面三个中的任意一个,我们就可以求出平移向量
t
t
t,根据求解平移向量
t
t
t我们求得各对匹配的特征点之间的误差,根据误差大小设定阈值就可以判断哪些特征点是outliers,哪些点是inliers,接下来我们整理下完整的RANSAC算法的流程:
(1)先从前后帧所有匹配点中随机选取两对匹配点进行上面的计算,获得平移向量
t
t
t;
(2)通过平移向量
t
t
t计算其他所有匹配点的误差,根据误差判定哪些是inlers,哪些是outliers;
(3)根据所有的inlers重新求得平移向量
t
t
t;
(4)根据新的平移向量
t
t
t计算所有匹配点的误差,若误差和小于之前RANSAC采样获得的最小误差,则将inliers和误差记录下来
(5)最终输出误差最小的inlers组合。
最后补一句,RANSC的迭代次数由用户需求的成功率和inlers比例确定,计算公式如下:
M
=
log
(
1
−
p
s
)
log
(
1
−
p
K
)
M=\frac{\log \left(1-p_{s}\right)}{\log \left(1-p^{K}\right)}
M=log(1−pK)log(1−ps)其中
p
s
p_s
ps为RANSC成功率,
p
p
p为inlers比例
3. 新特征点提取
新特征点提取过程中,为了保证提取的有效性,MSCKF采用了两种手段:
(1)在提取特征点是使用的Mask操作,这个操作在VINS-Mone中也使用了,不过VINS-Mono中使用的圆形,MSCKF中使用的是方形,这个可以参考我之前写过的博客:VINS-Mono关键知识点总结——前端详解,加不加Mask提取的特征点的效果会有很大差别的。
(2)就是将特征点分配到网格中进行管理,并根据响应进行排序,删除掉响应低的特征点,这样做可以提高特征点的有效性。
以上就是我学习前端时的一些关注点,因为也是在学习,难免会有理解不对的地方,如果有问题欢迎指出欢迎交流~下个礼拜写后端
此外,对其他SLAM算法感兴趣的同学可以看考我的博客SLAM算法总结——经典SLAM算法框架总结

















 2656
2656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









