






Apollo决策规划算法学习系列目录
第一章 Apollo决策规划算法基本概念
第二章 Apollo决策规划之路径规划算法
第三章 Apollo决策规划之速度规划算法
前言
本文为第三章,主要讲解 Apollo决策规划算法中的速度规划算法,EM planner的速度规划算法同样是是通过动态规划和二次规划实现的,下面来细讲速度规划算法。
一、ST图与迭代优化
1.1 ST图
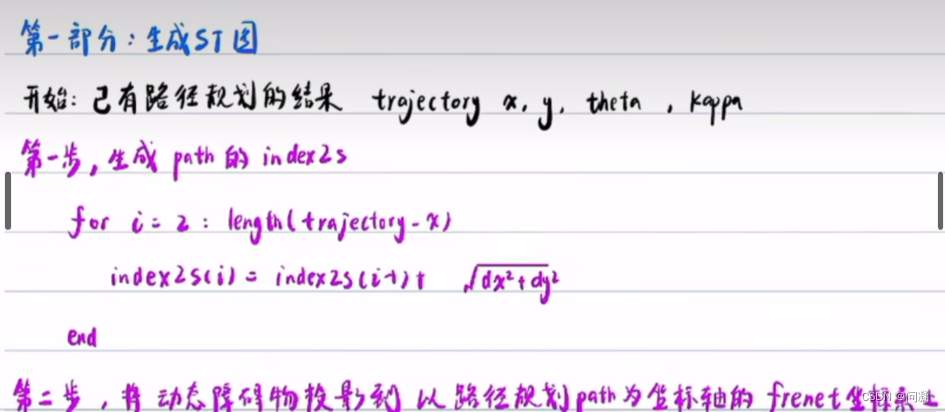
1)回顾上一讲说过的路径规划算法,生成参考线后建立Frenet坐标系,把障碍物投影到Frenet坐标系中,动态规划(路径决策)、二次规划求出规划的路径,把Frenet坐标系转换为笛卡尔坐标系,现在我们就已经有了笛卡尔坐标系下的规划的路径了;
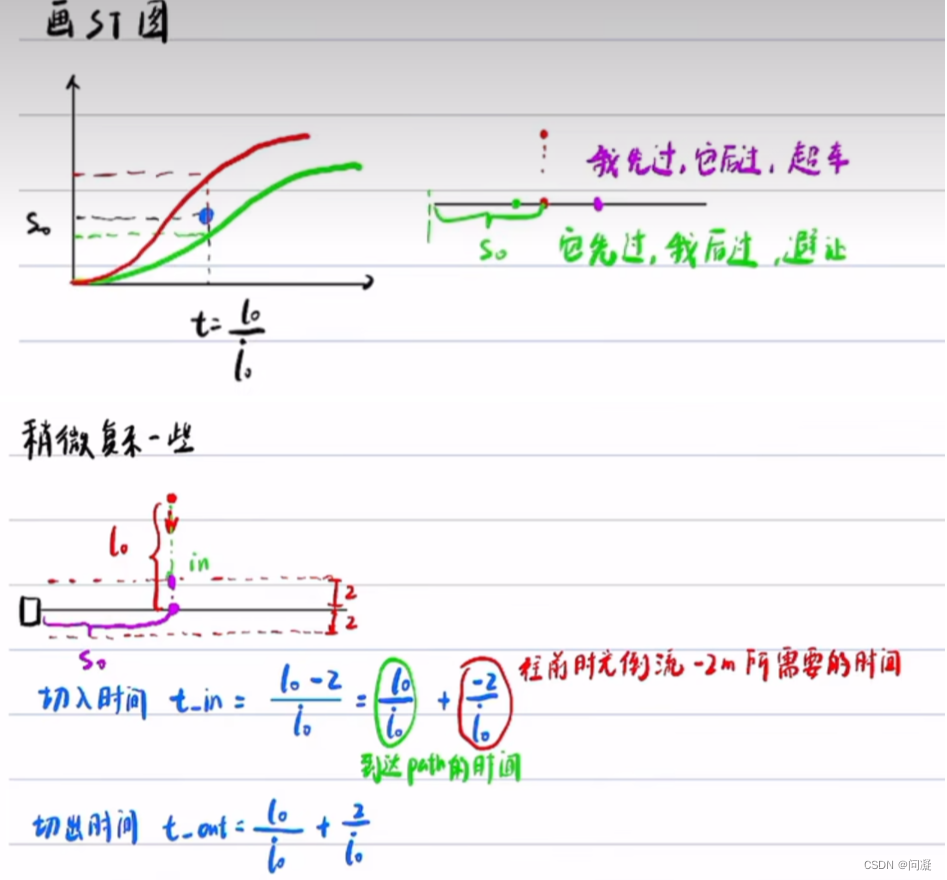
2)接下来进行速度规划,将笛卡尔坐标系的路径为坐标轴,建立Frenet坐标系,将动态障碍物投影到Frenet坐标系下,生成ST图,接下来就是动态规划算法进行速度决策,是减速避让动态障碍物还是加速超过它,然后二次规划算法规划出一条可行的带有速度信息的路径,下面用图解的方式看一看ST图怎么得到的;
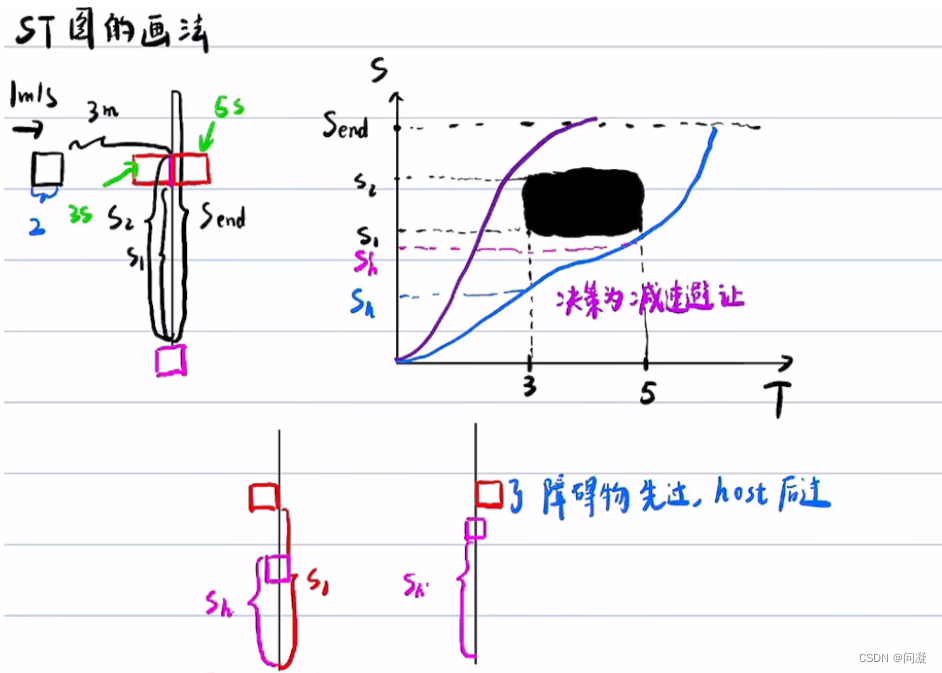
1.2 SL图与ST图迭代优化
1)来看SL图与ST图如何迭代优化,首先是利用上一帧规划的轨迹加上预测的障碍物的轨迹,上一帧规划的轨迹也就是SL图,利用SL图与预测的障碍物轨迹在ST图中得到障碍物的位置,然后在没有和它碰撞的地方规划出一条带有速度的路径避免与障碍物相撞,到下一个周期再利用这一帧的轨迹与预测在ST图中得到障碍物的位置,再进行速度规划,如此反复迭代;下面是图解的方式;
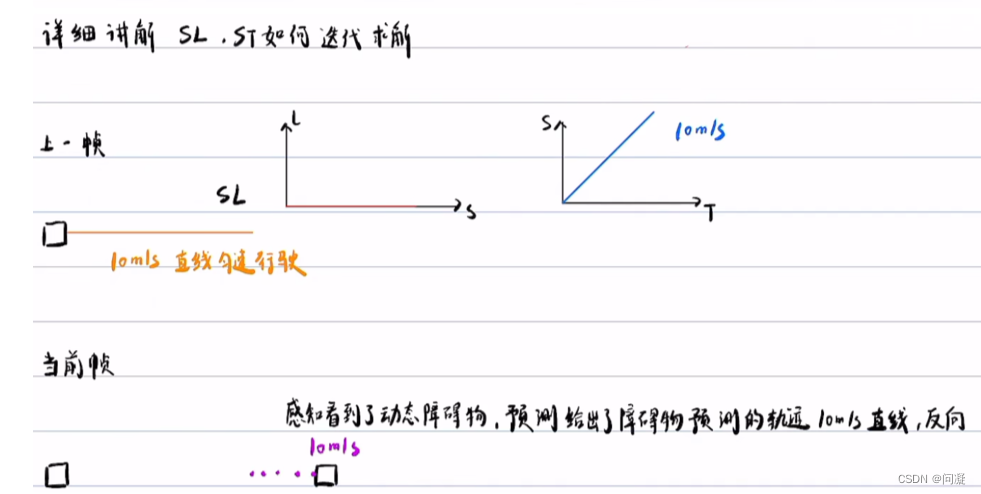
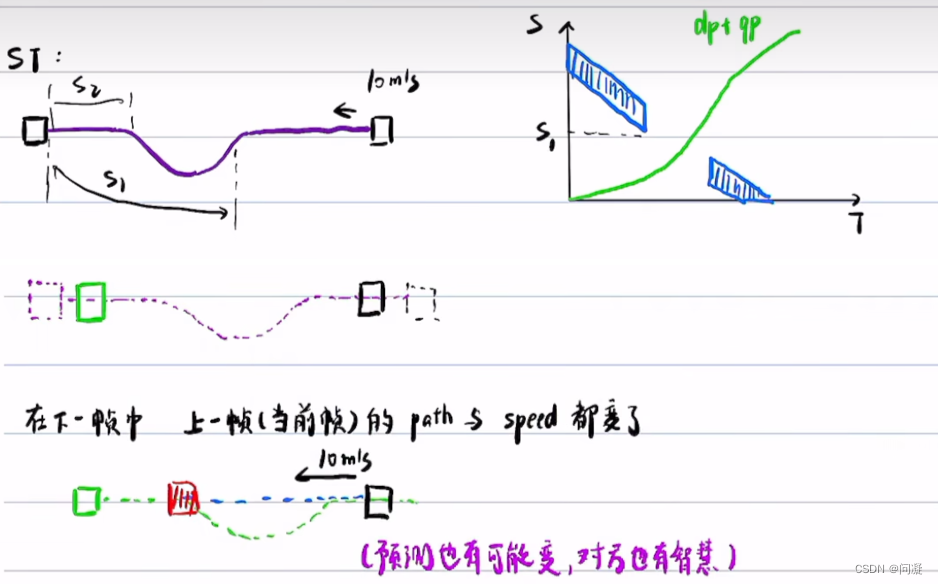
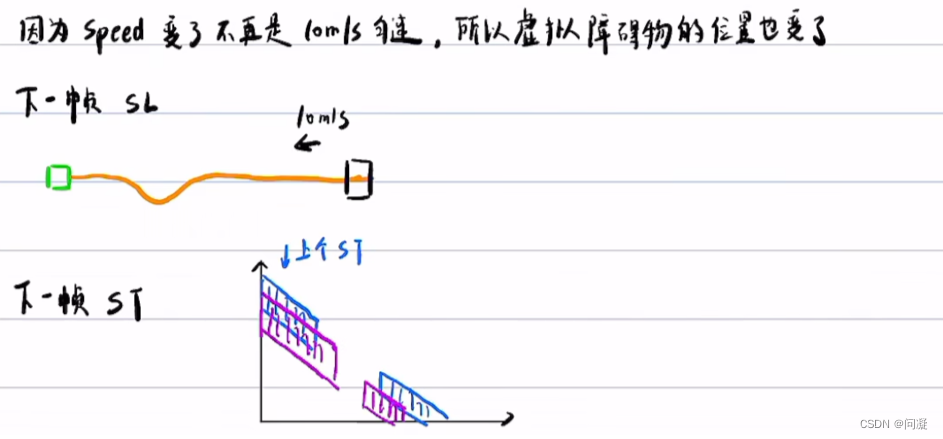
总结来说就是当前帧SL图->当前帧ST图->改变当前帧的速度规划->当前帧的轨迹改变->下一帧用当前的轨迹+下一帧的预测->下一帧SL图->下一帧ST图->改变下一帧的速度规划->下一帧的轨迹改变。

1.3 ST图与SL图迭代优化改进
1)上面说了ST图与SL图迭代优化,其中说到了下一帧预测障碍物的位置,但这都是以匀速运动模型或者匀加速运动模型来预测的,真实情况往往比较复杂,预测也不准确, 在Apollo1.5中EM planner引入了SL、ST解耦规划,先决策后规划,但是在Apollo3.5中,大幅修改了EM planner变成了Publicroad planner,最重要的是取消了SL、ST图的迭代机制,SL图只管静态障碍物,ST图只管动态障碍物,下面说一说SL图与ST图迭代机制的缺点以及为什么取消迭代机制;
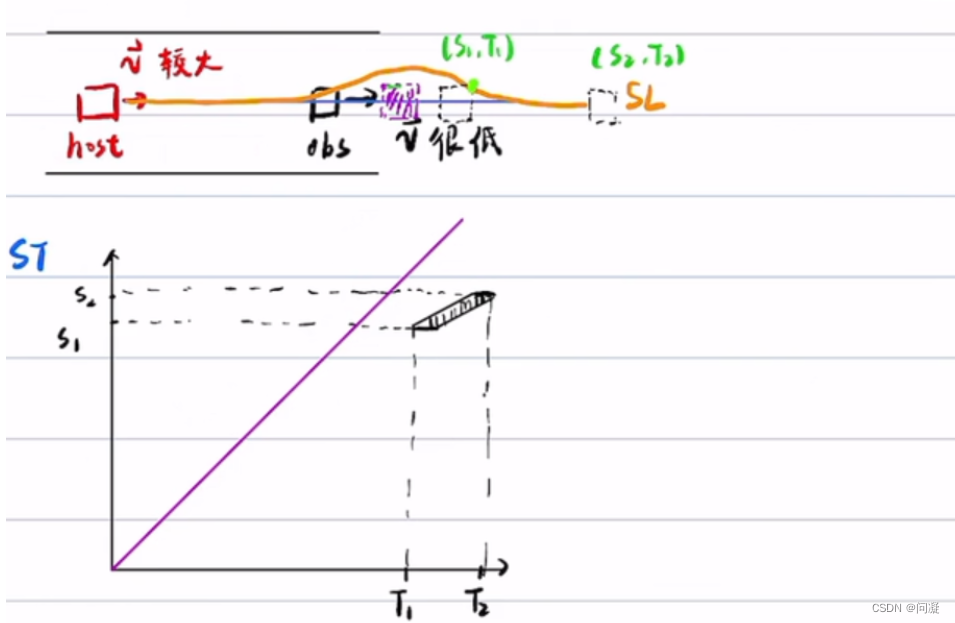
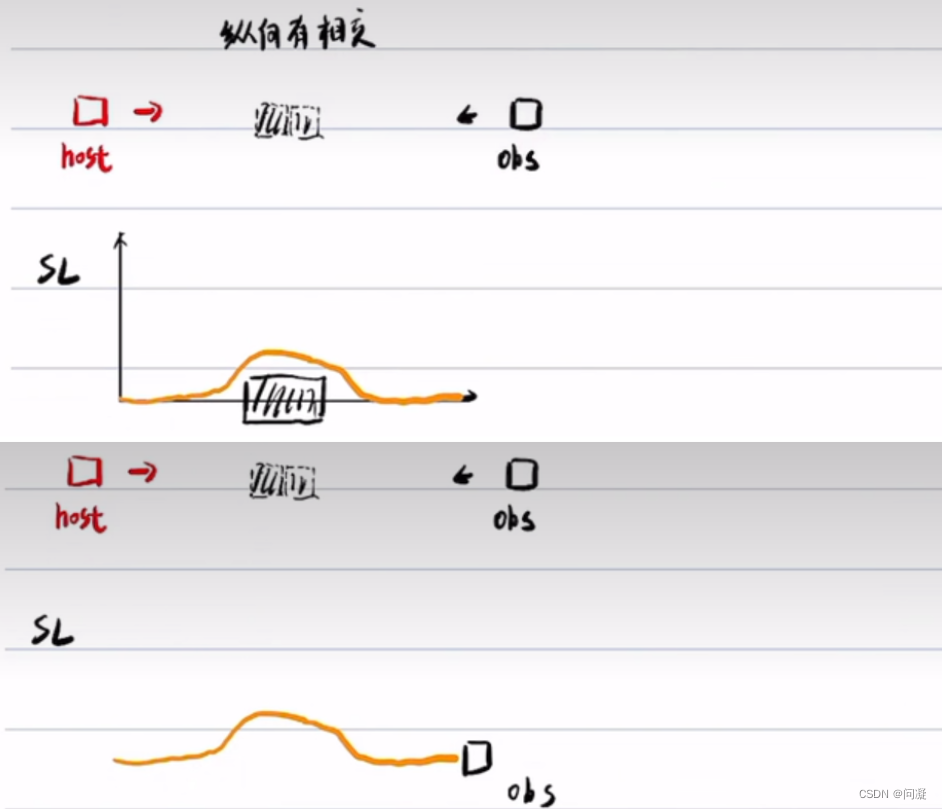
2)主要原因是减轻ST图对SL图的干扰,因为车辆的纵向变化能力高于横向变化能力,导致障碍物车的速度变化剧烈程度远高于路径,预测不准确,预测不准确 导致ST图剧烈变化,速度规划的结果就剧烈变化,ST图就会影响SL图,导致SL规划不稳定,朝令夕改;但是有两种场景ST与需要影响SL图:
一种是当前车道前方有很慢的车辆而且自身车辆速度较大,这时候就必须借道绕行;另一种情况是当前车道对向行驶来的车辆,也必须借道绕行;
二、速度规划算法实践详解




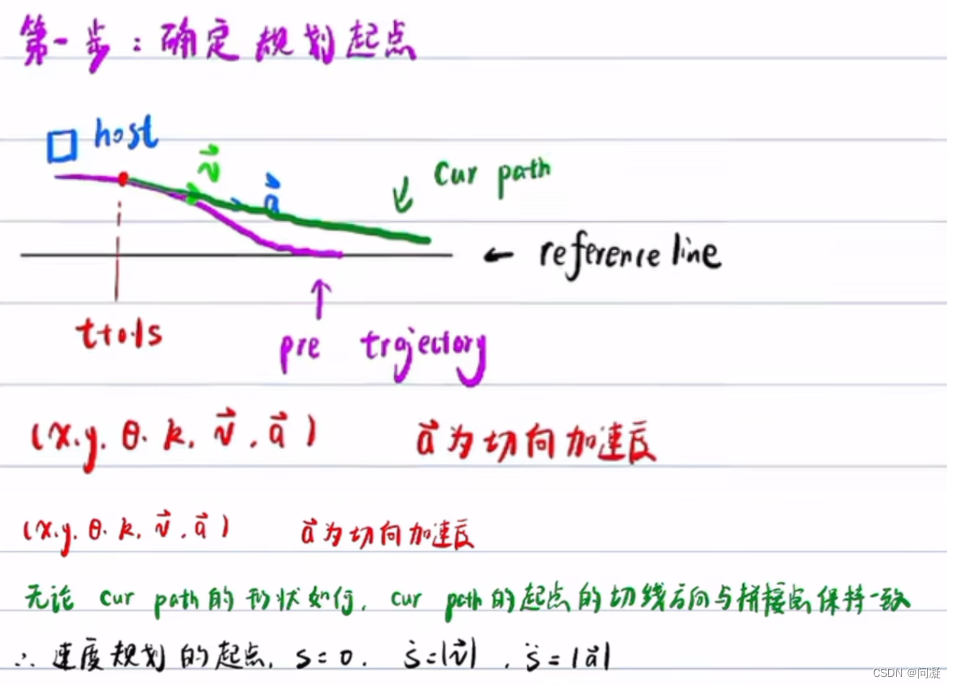
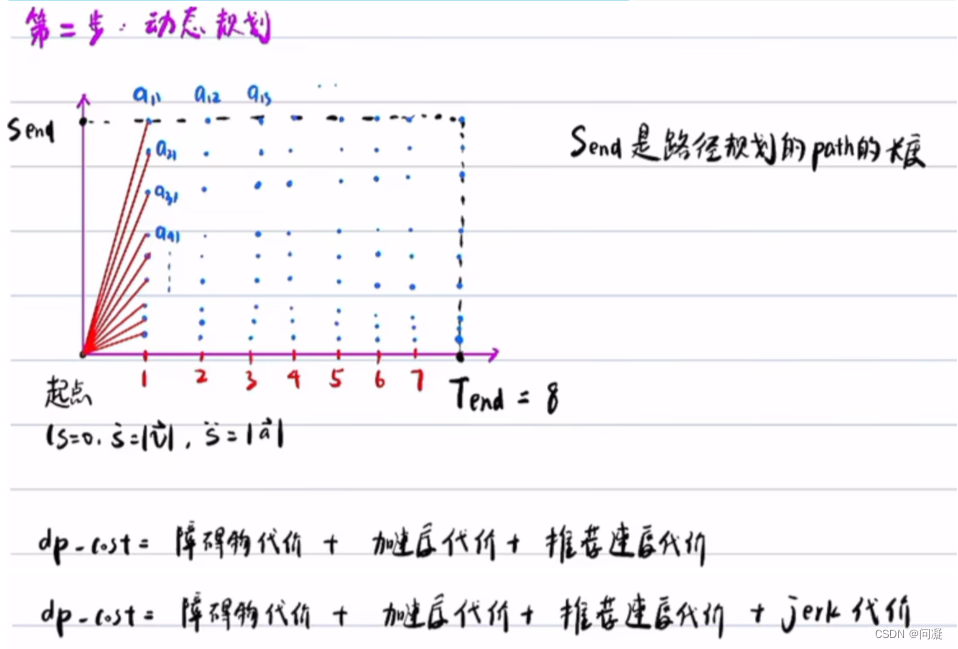


总结
以上就是今天要讲的内容,本文介绍了Apollo决策规划算法中的速度规划算法,速度规划算法同样是通过动态规划和二次规划实现的。
















 6315
6315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









