






题目:通过生成模拟释放无限数据以实现机器人自动化学习
关键词:生成模拟、无限数据
摘要
我们推出 RoboGen,这是一种生成机器人代理,可以通过生成模拟自动大规模学习各种机器人技能。 RoboGen 利用基础模型和生成模型的最新进展。我们不直接使用或调整这些模型来产生策略或低级动作,而是提倡一种生成方案,该方案使用这些模型自动生成多样化的任务、场景和训练监督,从而在最少的人类监督下扩大机器人技能的学习。
我们的方法为机器人代理提供了一个自我引导的提议(propose)-生成(generate)-学习(learning)循环.
1、代理首先提出要开发的感兴趣的任务和技能,然后通过使用适当的空间配置填充相关对象和资产来生成相应的模拟环境。
2、代理将propose的高级任务分解为子任务,选择最佳学习方法(强化学习、运动规划或轨迹优化),生成所需的训练监督,然后学习策略以获得提议的技能。
我们的工作试图提取大型模型中嵌入的广泛且通用的知识,并将其转移到机器人领域。我们的完全生成pipeline可以重复查询,产生与不同任务和环境相关的无穷无尽的技能演示。
介绍
这项工作的动机是机器人研究中一个长期存在且具有挑战性的目标:赋予机器人多种技能,使它们能够在各种非工厂环境中操作并为人类执行广泛的任务。近年来,在教机器人各种复杂技能方面取得了令人瞩目的进展:从可变形物体和流体操纵到动态和灵巧技能,如物体投掷、手部重新定向、踢足球甚至机器人跑酷。然而,这些技能仍然各自为政,视野相对较短,并且需要人为设计的任务描述和训练监督。值得注意的是,由于现实世界数据收集的成本高昂且费力,许多这些技能都是在具有适当领域随机化的模拟中进行训练,然后部署到现实世界中。
事实上,模拟环境已经成为多样化机器人技能学习背后的关键驱动力。与现实世界中的探索和数据收集相比,模拟中的技能学习具有以下几个优点:1)模拟环境提供了特权低级状态的访问和无限的探索机会; 2) 仿真支持大规模并行计算,能够显着加快数据收集速度,而无需依赖对机器人硬件和人力的大量投资; 3)模拟探索允许机器人开发闭环策略和错误恢复能力,而现实世界的演示通常只提供专家轨迹。然而,模拟中的机器人学习也存在其自身的局限性:虽然在模拟环境中探索和练习具有成本效益,但构建这些环境需要大量的劳动力,需要繁琐的步骤,包括设计任务、选择相关且语义上有意义的资产、生成合理的场景布局和配置,以及制定训练监督,例如奖励或损失函数。创建这些组件并为我们日常生活中遇到的无数任务构建个性化模拟设置的繁重任务是一项巨大的挑战,即使在模拟世界中,这也极大地限制了机器人技能学习的可扩展性。
想解决的两个问题:1、机器人的技能各自孤立,且需要人为设计的任务描述和训练监督;(2)在模拟器上进行训练,虽然模拟器有很多优势,但也在一定程度上限制了机器人技能学习的可扩展性。
有鉴于此,我们提出了一种称为生成模拟的范例,将模拟机器人技能学习、基础大模型和生成模型的最新进展结合起来。利用最先进的基础模型的生成能力,生成模拟旨在为模拟中各种机器人技能学习所需的所有阶段生成信息:从高级任务和技能建议,到任务相关的场景描述,资产选择和生成、策略学习选择和训练监督。得益于最新基础模型中编码的全面知识,以这种方式生成的场景和任务数据有可能与现实世界场景的分布非常相似。此外,这些模型还可以进一步提供分解的低级子任务,这些子任务可以通过特定领域的策略学习方法无缝处理,从而产生各种技能和场景的闭环演示。
本文的RoboGen结合模拟机器人技能学习、基础大模型和生成模型,想达到目标:1、生成机器人技能学习过程中所需要的信息:任务和技能的生成、为相关的任务配备虚拟环境;2、将高级任务分解成低级子任务,策略选择学习、生成训练监督。
我们提出的范式的一个明显优势在于从当代基础模型中提取知识模式的战略设计。这些模型在各种模式中展示了令人印象深刻的能力,产生了能够使用一系列工具并解决虚拟领域中的各种任务的自主智能体。然而,由于缺乏与动力学、驱动和物理交互相关的训练数据,这些模型尚未完全理解机器人有效执行物理动作并与周围环境交互的必要条件——从辨别稳定运动所需的精确关节扭矩,到灵巧操作任务所需的高频手指运动命令,如擀面团。与最近使用这些基础模型(例如大型语言模型(LLM))直接生成策略或低级操作的努力相比,我们主张采用一种方案来提取完全属于这些模型的功能和模式的信息——对象语义、对象可供性、常识知识来识别有价值的学习任务。我们利用这些知识来构建环境游乐场,然后借助基于物理的模拟的额外帮助,让机器人加深对物理交互的理解并获得各种技能。(也就是说只利用大模型的知识去构建一个环境,供机器人完成各种任务,而不是利用大模型的知识让它生条某个策略)

我们首先在最近的一份白皮书(Xian 等人,2023a)中描述了这样的范式,将其描绘为为通用机器人学习生成多样化数据的有效途径。在本文中,我们提出了 RoboGen,这是该范式的全面实现。 RoboGen 是一种生成式机器人代理,可以自行提出学习技能,在模拟中生成场景组件和配置,用自然语言描述标记任务,并为后续技能学习设计适当的训练监督。我们的实验表明,RoboGen 可以提供连续的多样化技能演示,涵盖的任务包括刚性和铰接式物体操作、可变形物体操作以及腿式运动技能(见图 1)。 RoboGen 生成的任务和技能的多样性超过了以前人类创建的机器人技能学习数据集,除了几个提示设计和上下文示例之外,只需最少的人类参与。我们的工作试图提取大型模型中嵌入的广泛且通用的知识,并将其转移到机器人领域。当无休止地查询时,我们的系统有潜力为机器人学习释放无限量的多样化演示数据,从而向通用机器人系统的全自动大规模机器人技能训练迈出了一步。
相关工作
Robotic skill learning in simulations
过去已经开发了各种基于物理的模拟平台来加速机器人研究,其中包括刚体模拟器、可变形物体模拟器以及支持多材料及其与机器人耦合的环境。此类仿真平台已在机器人社区中广泛用于学习各种技能,包括桌面操纵、可变形物体操纵、物体切割、流体操纵,高动态以及高动态和复杂的技能,例如-手部重新定位、物体投掷、杂技飞行、腿式机器人和软体机器人的运动。
Scaling up simulation environments
除了构建物理引擎和模拟器之外,大量先前的工作旨在构建大规模模拟基准,为可扩展的技能学习和标准化基准测试提供平台。值得注意的是,大多数这些先前的模拟基准或技能学习环境都是通过人工标记手动构建的。另一系列工作尝试使用程序生成来扩展任务和环境,并使用任务和运动规划(TAMP)生成演示。这些方法主要建立在手动定义的规则和规划域之上,限制了生成的环境和技能的多样性,相对简单的拾放和对象堆叠任务。与这些工作相反,我们提取了LLM等基础模型中嵌入的常识知识,并用它们来生成有意义的任务、相关场景和技能培训监督,从而产生更加多样化和合理的技能。
Foundation and generative models for robotics
随着图像、语言和其他模态领域的基础和生成模型的快速发展,一系列活跃的工作研究进行机器人研究,具体方法例如:代码生成、数据增强、促进技能执行的视觉想象力、子任务规划、所学技能的概念概括、输出低级控制动作和目标规范。与我们的方法更相关的是最近使用 LLM 进行奖励生成的方法(Yu 等人,2023b)以及子任务和轨迹生成(Ha 等人,2023)。与它们相反,我们提出的系统旨在建立一个完全自动化的pipeline,可以自行提出新任务、生成环境并产生不同的技能。
Generative Simulation
我们在最近的一份白皮书中首次提出了生成模拟的想法。我们通过使用图像生成模型和LLM为 Franka 手臂生成资产、任务描述和分解来实现生成模拟的概念验证。在本文中,我们扩展了这一研究方向,以支持更广泛的机器人类型和更多样化的任务,并具有逼真的视觉效果,并由更先进的渲染和物理引擎提供支持。
RoboGen
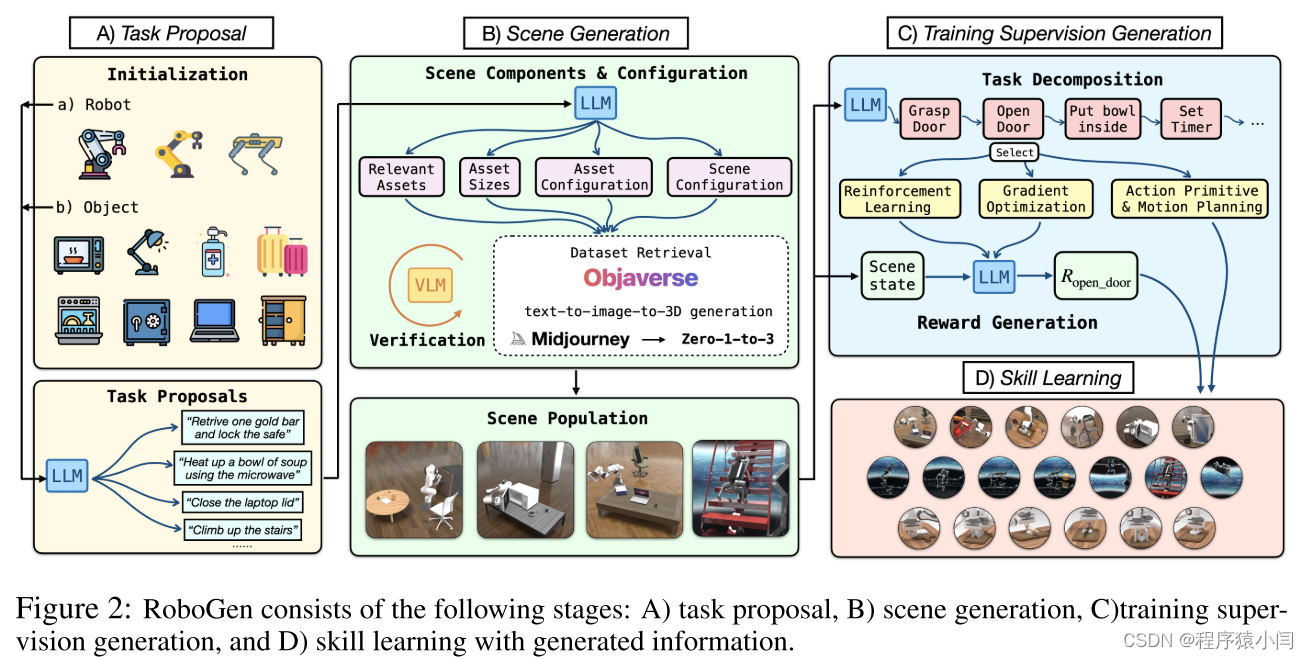 RoboGen 是一个自动化pipeline,利用最新基础模型的嵌入式常识和生成功能来自动生成任务、场景和训练监督,从而实现大规模的多样化机器人技能学习。我们在图 2 中展示了整个流程,由几个完整的阶段组成:任务提议、场景生成、训练监督生成和技能学习。我们将在下面详细介绍它们中的每一个。
RoboGen 是一个自动化pipeline,利用最新基础模型的嵌入式常识和生成功能来自动生成任务、场景和训练监督,从而实现大规模的多样化机器人技能学习。我们在图 2 中展示了整个流程,由几个完整的阶段组成:任务提议、场景生成、训练监督生成和技能学习。我们将在下面详细介绍它们中的每一个。
Task Proposal
RoboGen 首先生成有意义的、多样化的、高水平的任务供机器人学习。我们没有直接向 LLM 查询任务建议,而是使用特定的机器人类型和从池中随机采样的对象来初始化系统。然后将提供的机器人和采样对象信息用作 LLM 的输入以执行任务建议。这样的采样过程确保了生成任务的多样性:例如,四足机器人等腿式机器人能够获得多种运动技能,而机械臂操纵器在配对时有可能执行多种操纵任务与不同的采样对象。此初始化步骤充当播种阶段,为LLM可以进行调节并随后进行推理和推断以生成各种任务提供基础,同时考虑到机器人和物体的可供性。除了基于对象的初始化之外,另一种选择是采用基于示例的初始化,其中我们使用提供的机器人和从列表 11 个预定义任务中采样的几个示例任务来初始化查询。
我们使用 GPT-4 作为 LLM 在当前pipeline中进行查询,但一旦有更好的模型可用,该后端就可以升级。接下来,我们将在机械臂(例如 Franka)的背景下解释 RoboGen 的详细信息,以及使用基于对象的初始化生成的与对象操作相关的任务。在这种情况下,用于初始化的对象是从预定义列表PartNetMobility 和 RLBench 中采样的,包括家庭场景中常见的铰接式和非铰接式对象,例如烤箱、微波炉、饮水机、笔记本电脑、洗碗机等。
像 GPT-4 这样的LLM接受过广泛的互联网规模数据集的培训,对这些对象的可供性、如何与它们交互以及它们可以与哪些有意义的任务相关联的知识有着丰富的理解。为了生成涉及机器人对采样的铰接对象进行交互和操作的任务,我们构建了一个查询(针对随机采样对象的这种方法而言),其中包括铰接对象所属的大类、从 URDF 文件派生的铰接树以及PartNetMobility数据集提供有关以下内容的注释的语义文件:对象的链接,例如哪个链接对应于采样微波炉中的门。铰接对象的类别告知此类对象可以执行哪些一般类型的任务,而铰接树和语义文件则告知 GPT-4 对象可以如何精确地铰接,以及每个关节和链接的语义含义。该查询要求 GPT-4 返回可以使用采样对象执行的许多任务,其中每个任务由任务名称、任务的简短描述以及任务所需的任何其他对象组成所提供的铰接物体,以及机器人需要与铰接物体的哪些关节/连杆交互才能完成任务。此外,我们在 GPT-4 的查询中包含一个示例输入输出对,以执行上下文学习,以提高其响应的质量(这个输入输出对是给GPT4便于理解的一个例子)。
举一个具体的例子,假设一个采样的铰接物体是微波炉,其中关节 0 是连接其门的旋转关节,关节 1 是控制计时器旋钮的另一个旋转关节,GPT-4 将返回一个名为“加热一碗汤”的任务,任务描述为“机器人手臂将一碗汤放入微波炉内,关上门并设置微波炉定时器,选择适当的加热持续时间”,生成的任务所需的其他对象,例如“一碗汤”,以及与任务相关的关节和链接,包括关节 0(用于打开微波炉门)、关节 1(用于设置定时器)、链接 0(门)和链接 1(定时器旋钮)。有关详细的提示和示例响应,请参阅附录 B。请注意,对于我们对非铰接对象进行采样或使用基于示例的初始化的情况,采样的对象和示例仅作为任务建议的提示提供,并且生成的任务不会与它们绑定。对于铰接物体,由于 PartNetMobility 是唯一高质量的铰接物体数据集,并且已经涵盖了各种铰接资产,因此我们将根据采样资产生成任务。对于运动和软体操作任务,我们仅使用基于示例的初始化,并诉诸 GPT-4 来填充其他所需的对象。通过重复查询不同的采样对象和示例,我们可以生成各种操作和运动任务,并在需要时考虑相关对象的可供性。
场景生成
给定一个提议的任务,我们继续生成相应的模拟场景,以学习完成该任务的技能。如图 2 所示,根据任务描述生成场景组件和配置,并检索或生成对象资产以随后填充模拟场景。具体来说,场景组件和配置由以下元素组成:查询要填充到场景中的相关资产、其物理参数(例如大小)、配置(例如初始关节角度)以及资产的整体空间配置。
获取相关资产的查询
除了上一步任务提议中生成的任务所需的必要对象资产之外,为了增加生成场景的复杂性和多样性,同时类似于真实场景的对象分布,我们查询 GPT-4 以返回对与任务语义相关的对象的许多附加查询。请参阅图 1,了解 GPT-4 针对任务返回的其他对象的示例,例如,对于任务“打开存储,将玩具放入其中并关闭它”,生成的场景还涉及客厅垫子、桌面灯、一本书和一张办公椅。
也就是说这部分生成一些除了任务提议中所必要的物体之外的物体查询,构建一个场景。
检索或生成资产
生成的相关对象查询(即它们的语言描述)将用于在现有数据库中搜索或用作文本到图像的输入,然后图像到 3D 网格生成模型来生成资源的 3D 纹理网格(文本——》图像——》3D物体)。具体来说,我们使用 Objaverse,一个包含超过 800k 对象资源(3d 网格、纹理图片等)的大型数据集作为检索的主要数据库。对于 Objaverse 中的每个对象,我们通过结合默认注释和更简洁的注释版本来获取它的语言描述列表。给定我们要检索的资产的语言描述,我们使用 Sentence-Bert 来获取描述的嵌入,并从 Objaverse 中检索语言嵌入与目标资产的语言嵌入最相似的 k 个对象。由于对象注释中的噪声,即使语言嵌入空间中的相似性得分很高,实际资产与预期目标之间也可能存在显着差异。为了解决这个问题,我们进一步利用视觉语言模型(VLM)来验证检索到的资产并过滤掉不需要的资产。
具体来说,我们将检索到的对象的图像输入到 VLM 模型,并要求 VLM 为其添加标题。标题、所需资产的描述、任务的描述一起反馈到 GPT-4,以验证检索到的资产是否适合在建议的任务中使用。由于 Objaverse 的资产种类繁多,对于现有的预训练模型来说本质上是一个挑战,为了提高我们系统的鲁棒性,我们同时使用 Bard 和 BLIP-2 ,来交叉验证检索到的资产的有效性,并采用仅当 GPT-4 认为两者的字幕适合该任务时才使用资产。
我们在pipeline中使用 k = 10,如果所有资产都被拒绝,我们将采用文本到图像,然后是图像到网格生成模型,从语言描述生成所需的资产。我们使用 Midjourney作为我们的文本到图像生成模型,并使用 Zero-1-to-3 作为我们的图像到网格生成模型。对于软体操纵任务,为了获得被操纵的软体更加一致和可控的目标形状,我们要求 GPT-4 提出所需的目标形状,并且仅使用这种text-to-image-to-mesh pipeline而不是数据库检索。
资产的大小
来自 Objaverse 或 PartNetMobility 的资产通常没有物理上合理的大小。考虑到这一点,我们查询 GPT-4 来生成资产的大小,以便:1)大小应与真实世界的对象大小匹配; 2)物体之间的相对尺寸为解决任务提供了一个合理的解决方案,例如,对于“将书放入抽屉”的任务,抽屉的尺寸应该大于书。
初始资产配置
对于某些任务,应该使用有效状态来初始化铰接对象,以便机器人学习技能。例如,对于“关闭窗口”的任务,应该将窗口初始化为打开状态;同样,对于开门任务,门应该首先关闭。再次,我们查询 GPT-4 来设置这些铰接对象的初始配置,以关节角度指定。为了让 GPT-4 能够推理任务和关节对象,查询脚本包含任务描述、关节树和关节对象的语义描述。
场景配置
场景配置指定场景中每个资产的位置和相关姿势对于生成合理的环境和允许有效的技能学习至关重要。例如,对于“从保险箱中取出文件”的任务,需要在保险箱内对文件进行初始化;对于“将刀从案板上移开”的任务,需要首先将刀放在案板上。 RoboGen 以任务描述为输入查询 GPT-4 生成这种特殊的空间关系,并指示 GPT-4 以无碰撞的方式放置对象。
训练监督生成
为了获得解决所提出的任务的技能,需要对技能学习进行监督。为了促进学习过程,RoboGen 首先查询 GPT-4 来规划和分解生成的任务(可以是长范围的)为较短范围的子任务。我们的关键假设是,当任务被分解为足够短的子任务时,每个子任务都可以通过现有的算法(例如强化学习、运动规划或轨迹优化)可靠地解决。
分解后,RoboGen 随后查询 GPT-4 以选择合适的算法来解决每个子任务。 RoboGen 中集成了三种不同类型的学习算法:强化学习和进化策略、基于梯度的轨迹优化、具有运动规划的动作原语。每一种都适合不同的任务,例如,基于梯度的轨迹优化更适合学习涉及软体的细粒度操作任务,例如将面团塑造成目标形状;与运动规划相结合的动作基元在解决任务时更加可靠,例如通过无碰撞路径接近目标对象;强化学习和进化策略更适合接触丰富且涉及与其他场景组件持续交互的任务,例如腿运动,或者当所需的动作不能通过离散的末端执行器姿势简单地参数化时,例如转动烤箱的旋钮。
我们提供示例,让 GPT-4 根据生成的子任务在线选择使用哪种学习算法。我们考虑的动作原语包括抓取、接近和释放目标对象。由于平行爪式夹具在抓取不同尺寸的物体时可能会受到限制,因此我们考虑使用配备吸盘的机器人操纵器来简化物体抓取。抓取和接近基元的实现如下:我们首先随机采样目标对象或链接上的一个点,计算与采样点法线对齐的夹具姿势,然后使用运动规划来找到一条无碰撞路径达到目标夹具姿势。达到姿势后,我们继续沿着法线方向移动,直到与目标物体接触。
对于使用 RL 或轨迹优化来学习的子任务,我们提示 GPT-4 用一些上下文示例编写相应的奖励函数。对于对象操作和运动任务,奖励函数基于低级模拟状态,GPT-4 可以通过提供的 API 调用列表进行查询。此外,我们要求 GPT-4 为学习算法建议动作空间,例如末端执行器的增量平移,或末端执行器移动到的目标位置。 Delta 翻译更适合涉及局部运动的任务,例如,在抓住门后打开门;对于涉及将物体转移到不同位置的任务,直接指定目标作为动作空间可以使学习更容易。对于软体操纵任务,奖励具有固定形式,指定为软体当前形状和目标形状之间的推土机距离。
技能学习
一旦我们获得了所提出的任务所需的所有信息,包括场景组件和配置、任务分解以及分解的子任务的训练监督,我们就能够为机器人构建模拟场景,以学习完成任务所需的技能任务。
如上所述,我们结合使用多种技术进行技能学习,包括强化学习、进化策略、基于梯度的轨迹优化以及带有运动规划的动作原语,因为每种技术都适合不同类型的任务。对于对象操作任务,我们使用 SAC 作为学习技能的 RL 算法。观察空间是任务中物体和机器人的低层状态。强化学习策略的动作空间包括机器人末端执行器的增量平移或目标位置(由 GPT-4 确定)及其增量旋转。我们使用开放运动规划库(OMPL)(Sucan 等人,2012)中实现的 BIT* 作为动作基元的底层运动规划算法。对于涉及多个子任务的长视野任务,我们采用顺序学习每个子任务的简单方案:对于每个子任务,我们运行 RL N = 8 次,并使用具有最高奖励的最终状态作为初始状态状态为下一个子任务。对于运动任务,交叉熵方法(CEM)用于技能学习,我们发现它比 RL 更稳定、更高效。 CEM中采用地面真值模拟器作为动态模型,需要优化的动作是机器人的关节角度值。对于软体操纵任务,我们与 Adam 一起运行基于梯度的轨迹优化来学习技能,其中梯度由我们使用的完全可微模拟器提供。
实验
RoboGen 是一个自动化pipeline,可以无限查询,并为不同的任务生成连续的技能演示流。在我们的实验中,我们旨在回答以下问题:
• 任务多样性:RoboGen 机器人技能学习提出的任务有多多样化?
• 场景有效性:RoboGen 是否生成与建议的任务描述相匹配的有效模拟环境?
• 训练监督有效性:RoboGen 是否为任务生成正确的任务分解和训练监督,从而诱导预期的机器人技能?
• 技能学习:在RoboGen 中集成不同的学习算法是否可以提高学习技能的成功率?
• 系统:结合所有自动化阶段,整个系统能否产生多样化且有意义的机器人技能?
实验设置
我们提出的系统是通用的,并且与特定的模拟平台无关。然而,由于我们考虑了从刚性动力学到软体模拟的广泛任务类别,并且还考虑了技能学习方法,例如基于梯度的轨迹优化,这需要可微分的模拟平台,因此我们使用 Genesis 来部署 RoboGen(一个模拟平台)用于使用多种材料和完全可微分的机器人学习。对于技能学习,我们使用 SAC 作为 RL 算法。策略和 Q 网络都是大小为 [256, 256, 256] 的多层感知器 (MLP),以 3e − 4 的学习率进行训练。对于每个子任务,我们使用 1M 环境步骤进行训练。我们使用 BIT* 作为运动规划算法,使用 Adam 用于软体操纵任务的基于梯度的轨迹优化。
评估指标和baseline
任务多样性
生成的任务的多样性可以从许多方面来衡量,例如任务的语义、生成的模拟环境的场景配置、检索到的对象资产的外观和几何形状以及执行任务所需的机器人动作。对于任务的语义意义,我们通过计算生成的任务描述的 Self-BLEU 和嵌入相似度来进行定量评估,其中较低的分数表明更好的多样性。我们与既定基准进行比较,包括 RLBench、Maniskill2、Meta-World 和 Behaviour-100。对于对象资产和机器人动作,我们使用生成的模拟环境和所学机器人技能的可视化来定性评估 RoboGen。
场景有效性
为了验证检索到的对象是否符合任务要求,我们计算模拟场景中检索到的对象的渲染图像与对象的文本描述之间的 BLIP-2 分数。我们与我们系统的两次消融进行比较。 A)无对象验证:我们不使用VLM来验证检索到的对象,而只是基于文本匹配来检索对象。 B) 无大小验证:我们不使用 GPT-4 输出的对象大小;相反,我们使用 Objaverse 或 PartNetMobility 中提供的默认资源大小。
总结
我们引入了 RoboGen,这是一种生成代理,可以通过生成模拟自动大规模地提出和学习各种机器人技能。 RoboGen 利用基础模型的最新进展,在模拟中自动生成不同的任务、场景和训练监督,为模拟中可扩展的机器人技能学习迈出了基础一步,同时部署后只需要最少的人工监督。我们的系统是一个完全生成的pipeline,可以无限查询,产生大量与不同任务和环境相关的技能演示。 RoboGen 与后端基础模型无关,并且可以使用可用的最新模型不断升级。
我们当前的系统仍然存在一些局限性:1)对所学技能的大规模验证(即所得技能是否真的通过文本描述解决了相应的任务)仍然是当前pipeline中的一个挑战。未来可以通过使用更好的多模式基础模型来解决这个问题。Ma还探索了使用环境反馈对生成的监督(奖励函数)进行迭代细化,我们希望将来将其整合到我们的范式中。 2)当涉及到现实世界的部署时,我们的范例本质上受到模拟与真实差距的限制。然而,随着物理精确模拟的最新和快速发展,以及域随机化和逼真的感官信号渲染等技术,我们预计模拟与真实的差距在未来将进一步缩小。 3)我们的系统假设,通过正确的奖励函数,现有的策略学习算法足以学习所提出的技能。对于我们在本文中测试的策略学习算法(具有 SAC 的 RL 和 delta 末端执行器姿势的动作空间,以及基于梯度的轨迹优化),我们观察到它们仍然不够鲁棒,并且通常需要多次运行才能产生成功某些生成任务的技能演示。我们将更强大的策略学习算法集成到 RoboGen 中,例如那些具有更好动作参数化的算法,作为未来的工作。

















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









