







文章目录
补充知识
贝叶斯
- 贝叶斯公式: 先假设一个事件发生的概率, 再用新得到的信息修正它
- P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) P(A|B)=P(A)\frac{P(B|A)}{P(B)} P(A∣B)=P(A)P(B)P(B∣A)
- 后验概率 = 先验概率 x 调整因子(可能性函数)
- 全概率公式
- P ( B ) = P ( B ∣ A ) P ( A ) + P ( B ∣ A ′ ) P ( A ′ ) P(B)=P(B|A)P(A) + P(B|A')P(A') P(B)=P(B∣A)P(A)+P(B∣A′)P(A′)
似然函数&最大似然估计
详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解
一文搞懂极大似然估计
- 似然函数:
- P ( x ∣ θ ) P(x|\theta) P(x∣θ): x x x:某具体数据, θ \theta θ:某模型参数
- θ \theta θ确定 x x x变量: 概率函数, 描述对不同样本点 x x x, 其出现概率是多少
- x x x确定 θ \theta θ变量: 似然函数, 描述对不通模型参数, 出现 x x x样本的的概率是多少
- 最大似然估计: 在什么样的状态下, 最可能产生现在观测到的数据
- 似然: 在现在的位姿下, 可能产生怎样的观测数据
- 利用已知样本结果信息, 反推最有可能导致这些样本结果出现的模型参数值
- 条件: 所有采样都是独立同步分布的
齐次矩阵
正定矩阵
- 当 X X X不是零向量, 有 f = X ′ A X > 0 f=X'AX>0 f=X′AX>0, 这样的二次型称正定的, 对称矩阵 A A A称正定矩阵
奇异矩阵
- 矩阵可表示变换, 逆矩阵可表示其逆变换
- 非奇异矩阵: 行列式≠0
- 奇异矩阵: 行列式=0, 没有逆矩阵
6.1.状态估计问题
6.1.1.最大后验估计
- 经典SLAM模型=运动方程+观测方程
-
{
x
k
=
f
(
x
k
−
1
,
u
k
)
+
w
k
z
k
,
j
=
h
(
y
j
,
x
k
)
+
v
k
,
j
\left\{\begin{array}{l}\boldsymbol{x}_{k}=f\left(\boldsymbol{x}_{k-1}, \boldsymbol{u}_{k}\right)+\boldsymbol{w}_{k} \\\boldsymbol{z}_{k, j}=h\left(\boldsymbol{y}_{j}, \boldsymbol{x}_{k}\right)+\boldsymbol{v}_{k, j}\end{array}\right.
{xk=f(xk−1,uk)+wkzk,j=h(yj,xk)+vk,j
- x 1 . . . x K x_1 ... x_K x1...xK 各时刻的位置
- y 1 . . . y N y_1 ... y_N y1...yN 路标点
- u k u_k uk 运动传感器的读数/输入
- w k w_k wk 噪声
-
{
x
k
=
f
(
x
k
−
1
,
u
k
)
+
w
k
z
k
,
j
=
h
(
y
j
,
x
k
)
+
v
k
,
j
\left\{\begin{array}{l}\boldsymbol{x}_{k}=f\left(\boldsymbol{x}_{k-1}, \boldsymbol{u}_{k}\right)+\boldsymbol{w}_{k} \\\boldsymbol{z}_{k, j}=h\left(\boldsymbol{y}_{j}, \boldsymbol{x}_{k}\right)+\boldsymbol{v}_{k, j}\end{array}\right.
{xk=f(xk−1,uk)+wkzk,j=h(yj,xk)+vk,j
- 状态估计问题: 假设
x
k
x_k
xk处对路标
y
j
y_j
yj进行了一次观测, 对应到图像上像素位置
z
k
,
j
z_{k,j}
zk,j, 则观测方程
-
s
z
k
,
j
=
K
(
R
k
y
j
+
t
k
)
sz_{k,j}=K(R_ky_j+t_k)
szk,j=K(Rkyj+tk)
- K K K: 相机内参
- s s s: 像素点的距离
- 假设两个噪声项 w k , v k , j w_k,v_{k,j} wk,vk,j满足零均值的高斯分布
- 通过带噪声的数据 z z z和 u u u推断位姿 x x x和地图 y y y (状态估计问题)
- 增量方法: 持有一个当前时刻的估计状态, 用新的数据更新它
- 只关心当前状态, 不考虑
- 批量方法: 聚集数据, 一起处理
- SfM, 不实时
- 滑动窗口估计法: 固定一些历史轨迹, 仅对当前时刻附近一些轨迹进行优化
-
s
z
k
,
j
=
K
(
R
k
y
j
+
t
k
)
sz_{k,j}=K(R_ky_j+t_k)
szk,j=K(Rkyj+tk)
- 批量方法
- 概率学角度: 已知输入数据 u u u和观测数据 z z z条件下, 求状态 x x x, y y y的条件概率分布 P ( x , y ∣ z , u ) P(x,y|z,u) P(x,y∣z,u)
- 问题变为求解最大似然估计
- ( x , y ) ∗ M L E = arg max P ( z , u ∣ x , y ) (\boldsymbol{x}, \boldsymbol{y})^{*}{ }_{\mathrm{MLE}}=\arg \max P(\boldsymbol{z}, \boldsymbol{u} \mid \boldsymbol{x}, \boldsymbol{y}) (x,y)∗MLE=argmaxP(z,u∣x,y)
- 似然: 在现在的位姿下, 可能产生怎样的观测数据
- 最大似然估计: 在什么样的状态下, 最可能产生现在观测到的数据
6.1.2.最小二乘
- 最小化负对数求一个高斯分布的最大似然
-
(
x
k
,
y
j
)
∗
=
arg
max
N
(
h
(
y
j
,
x
k
)
,
Q
k
,
j
)
=
arg
min
(
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
T
Q
k
,
j
−
1
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
)
\begin{aligned}\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)^{*} &=\arg \max \mathcal{N}\left(h\left(\boldsymbol{y}_{j}, \boldsymbol{x}_{k}\right), \boldsymbol{Q}_{k, j}\right) \\&=\arg \min \left(\left(\boldsymbol{z}_{k, j}-h\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)\right)^{\mathrm{T}} \boldsymbol{Q}_{k, j}^{-1}\left(\boldsymbol{z}_{k, j}-h\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)\right)\right)\end{aligned}
(xk,yj)∗=argmaxN(h(yj,xk),Qk,j)=argmin((zk,j−h(xk,yj))TQk,j−1(zk,j−h(xk,yj)))
- 等价于最小化噪声项的一个二次型: 马哈拉诺比斯距离(马氏距离)
- 由 Q k , j − 1 Q_{k,j}^{-1} Qk,j−1(信息矩阵)加权后的欧氏距离(高斯分布协方差矩阵的逆)
-
(
x
k
,
y
j
)
∗
=
arg
max
N
(
h
(
y
j
,
x
k
)
,
Q
k
,
j
)
=
arg
min
(
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
T
Q
k
,
j
−
1
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
)
\begin{aligned}\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)^{*} &=\arg \max \mathcal{N}\left(h\left(\boldsymbol{y}_{j}, \boldsymbol{x}_{k}\right), \boldsymbol{Q}_{k, j}\right) \\&=\arg \min \left(\left(\boldsymbol{z}_{k, j}-h\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)\right)^{\mathrm{T}} \boldsymbol{Q}_{k, j}^{-1}\left(\boldsymbol{z}_{k, j}-h\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)\right)\right)\end{aligned}
(xk,yj)∗=argmaxN(h(yj,xk),Qk,j)=argmin((zk,j−h(xk,yj))TQk,j−1(zk,j−h(xk,yj)))
- 最小二乘问题: 最小化所有时刻估计值与真实读数之间马氏距离<=>求最大似然估计
- min J ( x , y ) = ∑ k e u , k T R k − 1 e u , k + ∑ k ∑ j e z , k , j T Q k , j − 1 e z , k , j \min J(\boldsymbol{x}, \boldsymbol{y})=\sum_{k} \boldsymbol{e}_{\boldsymbol{u}, k}^{\mathrm{T}} \boldsymbol{R}_{k}^{-1} \boldsymbol{e}_{\boldsymbol{u}, k}+\sum_{k} \sum_{j} \boldsymbol{e}_{\boldsymbol{z}, k, j}^{\mathrm{T}} \boldsymbol{Q}_{k, j}^{-1} \boldsymbol{e}_{\boldsymbol{z}, k, j} minJ(x,y)=∑keu,kTRk−1eu,k+∑k∑jez,k,jTQk,j−1ez,k,j
- 各次输入和观测数据与模型之间的误差 e u , k = x k − f ( x k − 1 , u k ) e z , j , k = z k , j − h ( x k , y j ) \begin{aligned}{e}_{\boldsymbol{u}, k} &=\boldsymbol{x}_{k}-f\left(\boldsymbol{x}_{k-1}, \boldsymbol{u}_{k}\right) \\{e}_{\boldsymbol{z}, j, k} &=\boldsymbol{z}_{k, j}-h\left(\boldsymbol{x}_{k}, \boldsymbol{y}_{j}\right)\end{aligned} eu,kez,j,k=xk−f(xk−1,uk)=zk,j−h(xk,yj)
- 由于噪声存在, 估计的轨迹与地图带入SLAM运动, 观测方程时, 不全成立, 需对估计值进行微调使整体误差下降到极小值: 非线性优化
6.1.3.批量状态估计
- 考虑一个简单离散时间系统
x k = x k − 1 + u k + w k , w k ∼ N ( 0 , Q k ) z k = x k + n k , n k ∼ N ( 0 , R k ) \begin{array}{ll}\boldsymbol{x}_{k}=\boldsymbol{x}_{k-1}+\boldsymbol{u}_{k}+\boldsymbol{w}_{k}, & \boldsymbol{w}_{k} \sim \mathcal{N}\left(0, \boldsymbol{Q}_{k}\right) \\\boldsymbol{z}_{k}=\boldsymbol{x}_{k}+\boldsymbol{n}_{k}, & \boldsymbol{n}_{k} \sim \mathcal{N}\left(0, \boldsymbol{R}_{k}\right)\end{array} xk=xk−1+uk+wk,zk=xk+nk,wk∼N(0,Qk)nk∼N(0,Rk)- 运动方程: u k u_k uk输入, w k w_k wk噪声
- 观测方程: z k z_k zk对汽车未知策略, x 0 x_0 x0已知
- 最大似然估计
x map ∗ = arg max P ( x ∣ u , z ) = arg max P ( u , z ∣ x ) = ∏ k = 1 3 P ( u k ∣ x k − 1 , x k ) ∏ k = 1 3 P ( z k ∣ x k ) \begin{aligned}\boldsymbol{x}_{\text {map }}^{*} &=\arg \max P(\boldsymbol{x} \mid \boldsymbol{u}, \boldsymbol{z})=\arg \max P(\boldsymbol{u}, \boldsymbol{z} \mid \boldsymbol{x}) \\&=\prod_{k=1}^{3} P\left(\boldsymbol{u}_{k} \mid \boldsymbol{x}_{k-1}, \boldsymbol{x}_{k}\right) \prod_{k=1}^{3} P\left(\boldsymbol{z}_{k} \mid \boldsymbol{x}_{k}\right)\end{aligned} xmap ∗=argmaxP(x∣u,z)=argmaxP(u,z∣x)=k=1∏3P(uk∣xk−1,xk)k=1∏3P(zk∣xk)- 令批量状态变量为
x = [ x 0 , x 1 , x 2 , x 3 ] T , z = [ z 1 , z 2 , z 3 ] T , u = [ u 1 , u 2 , u 3 ] T x=[x_0,x_1,x_2,x_3]^T, z=[z_1,z_2,z_3]^T, u=[u_1,u_2,u_3]^T x=[x0,x1,x2,x3]T,z=[z1,z2,z3]T,u=[u1,u2,u3]T - 对于每一项 P ( u k ∣ x k − 1 , x k ) = N ( x k − x k − 1 , Q k ) P ( z k ∣ x k ) = N ( x k , R k ) \begin{aligned}P(u_k|x_{k-1},x_k)&=\mathcal{N}(x_k-x_{k-1},Q_k)\\P\left(\boldsymbol{z}_{k} \mid \boldsymbol{x}_{k}\right)&=\mathcal{N}\left(\boldsymbol{x}_{k}, \boldsymbol{R}_{k}\right)\end{aligned} P(uk∣xk−1,xk)P(zk∣xk)=N(xk−xk−1,Qk)=N(xk,Rk)
- 构建误差变量
e u , k = x k − x k − 1 − u k , e z , k = z k − x k e_{u,k}=x_k-x_{k-1}-u_k, e_{z,k}=z_k-x_k eu,k=xk−xk−1−uk,ez,k=zk−xk
- 令批量状态变量为
- 最小二乘目标函数
min ∑ k = 1 3 e u , k T Q k − 1 e u , k + ∑ k = 1 3 e z , k T R k − 1 e z , k \min \sum_{k=1}^{3} \boldsymbol{e}_{\boldsymbol{u}, k}^{\mathrm{T}} \boldsymbol{Q}_{k}^{-1} \boldsymbol{e}_{\boldsymbol{u}, k}+\sum_{k=1}^{3} \boldsymbol{e}_{\boldsymbol{z}, k}^{\mathrm{T}} \boldsymbol{R}_{k}^{-1} \boldsymbol{e}_{\boldsymbol{z}, k} mink=1∑3eu,kTQk−1eu,k+k=1∑3ez,kTRk−1ez,k- 定义向量 y = [ u , z ] T y=[u,z]^T y=[u,z]T, 可写出矩阵H使得 y − H x = e ∼ N ( 0 , Σ ) y-Hx=e\sim\mathcal{N}(0,\Sigma) y−Hx=e∼N(0,Σ)
- 问题变为 x m a p ∗ = arg min e T Σ − 1 e x_{map}^*=\arg\min e^T \Sigma^{-1}e xmap∗=argmineTΣ−1e
- 该问题唯一解 $ \boldsymbol{x}_{\text {map }}{*}=\left(\boldsymbol{H}{\mathrm{T}} \boldsymbol{\Sigma}^{-1} \boldsymbol{H}\right)^{-1} \boldsymbol{H}^{\mathrm{T}} \boldsymbol{\Sigma}^{-1} \boldsymbol{y}$
6.2.非线性最小二乘
- 对最小二乘问题
min x F ( x ) = 1 2 ∣ ∣ f ( x ) ∣ ∣ 2 2 \min_{\boldsymbol{x}}F(\boldsymbol{x})=\frac{1}{2}||f(\boldsymbol{x})||_2^2 xminF(x)=21∣∣f(x)∣∣22- 求导函数, 令导数=0, 求解x最优值
- 对形式复杂的导函数, 迭代法: 求解导函数为零的问题变为不断寻找下降增量
Δ
x
k
\Delta x_k
Δxk的问题
- 给定初始值 x 0 x_0 x0
- 对第 k k k次迭代, 寻找增量 Δ x k \Delta x_k Δxk使 ∣ ∣ f ( x k + Δ x k ) ∣ ∣ 2 2 ||f(x_k+\Delta x_k)||_2^2 ∣∣f(xk+Δxk)∣∣22最小
- Δ x k \Delta x_k Δxk足够小则停止
- 否则令 x k + 1 = x k + Δ x k x_{k+1}=x_k+\Delta x_k xk+1=xk+Δxk, ->第二步
6.2.1.一阶&二阶梯度法
- 第
k
k
k次迭代, 泰勒展开
-
F
(
x
k
+
Δ
x
k
)
≈
F
(
x
k
)
+
J
(
x
k
)
T
Δ
x
k
+
1
2
Δ
x
k
T
H
(
x
k
)
Δ
x
k
F\left(\boldsymbol{x}_{k}+\Delta \boldsymbol{x}_{k}\right) \approx F\left(\boldsymbol{x}_{k}\right)+\boldsymbol{J}\left(\boldsymbol{x}_{k}\right)^{\mathrm{T}} \Delta \boldsymbol{x}_{k}+\frac{1}{2} \Delta \boldsymbol{x}_{k}^{\mathrm{T}} \boldsymbol{H}\left(\boldsymbol{x}_{k}\right) \Delta \boldsymbol{x}_{k}
F(xk+Δxk)≈F(xk)+J(xk)TΔxk+21ΔxkTH(xk)Δxk
- J ( x k ) J(x_k) J(xk): F ( x ) F(x) F(x)关于 x x x的一阶导数, 梯度, 雅可比矩阵
- H ( x k ) H(x_k) H(xk): F ( x ) F(x) F(x)关于 x x x的二阶导数, 海塞矩阵
- 一阶梯度法
- 保留一节梯度, 取增量为反向梯度 Δ x ∗ = − J ( x k ) \Delta x^*=-J(x_k) Δx∗=−J(xk) , 可保证函数下降
- 二阶梯度法(牛顿法)
Δ x ∗ = arg min ( F ( x ) + J ( x ) T Δ x + 1 2 Δ x T H Δ x ) \Delta \boldsymbol{x}^{*}=\arg \min \left(F(\boldsymbol{x})+\boldsymbol{J}(\boldsymbol{x})^{\mathrm{T}} \Delta \boldsymbol{x}+\frac{1}{2} \Delta \boldsymbol{x}^{\mathrm{T}} \boldsymbol{H} \Delta \boldsymbol{x}\right) Δx∗=argmin(F(x)+J(x)TΔx+21ΔxTHΔx)- 对右侧求 Δ x \Delta x Δx导得 J + H Δ x = 0 ⇒ H Δ x = − J \boldsymbol{J}+\boldsymbol{H}\Delta \boldsymbol{x}=\boldsymbol{0}\Rightarrow \boldsymbol{H}\Delta \boldsymbol{x}=-\boldsymbol{J} J+HΔx=0⇒HΔx=−J
-
F
(
x
k
+
Δ
x
k
)
≈
F
(
x
k
)
+
J
(
x
k
)
T
Δ
x
k
+
1
2
Δ
x
k
T
H
(
x
k
)
Δ
x
k
F\left(\boldsymbol{x}_{k}+\Delta \boldsymbol{x}_{k}\right) \approx F\left(\boldsymbol{x}_{k}\right)+\boldsymbol{J}\left(\boldsymbol{x}_{k}\right)^{\mathrm{T}} \Delta \boldsymbol{x}_{k}+\frac{1}{2} \Delta \boldsymbol{x}_{k}^{\mathrm{T}} \boldsymbol{H}\left(\boldsymbol{x}_{k}\right) \Delta \boldsymbol{x}_{k}
F(xk+Δxk)≈F(xk)+J(xk)TΔxk+21ΔxkTH(xk)Δxk
6.2.2.高斯牛顿法
- 高斯牛顿法
- 给定初始值 x 0 x_0 x0
- 对第 k k k次迭代, 求当前雅可比矩阵 J ( x k ) J(x_k) J(xk)和误差 f ( x k ) f(x_k) f(xk)
- 求解增量方程: H Δ x k = g \boldsymbol{H}\Delta\boldsymbol{x}_k=\boldsymbol{g} HΔxk=g
- 若 Δ x k \Delta\boldsymbol{x}_k Δxk足够小, 停止; 否则令 x k + 1 = x k + Δ x k \boldsymbol{x}_{k+1}=\boldsymbol{x}_k+\Delta\boldsymbol{x}_k xk+1=xk+Δxk
- 只能在展开点附近有较好的近似效果
6.2.3.列文伯格-马夸尔特方法
- 列文伯格-马夸尔特方法(阻尼牛顿法)
- 给
Δ
x
\Delta\boldsymbol{x}
Δx加信赖区域
-
ρ
=
f
(
x
+
Δ
x
)
−
f
(
x
)
J
(
x
)
T
Δ
x
\rho=\frac{f(\boldsymbol{x}+\Delta\boldsymbol{x})-f(\boldsymbol{x})}{\boldsymbol{J}(\boldsymbol{x})^T\Delta\boldsymbol{x}}
ρ=J(x)TΔxf(x+Δx)−f(x)
- 分子: 实际函数下降值
- 分母: 近似模型下降值
- 接近1: 好近似
- 太小: 实际减小值远小于近似减小值, 近似较差, 缩小范围
- 太大: 实际下降比预计大, 放大近似范围
-
ρ
=
f
(
x
+
Δ
x
)
−
f
(
x
)
J
(
x
)
T
Δ
x
\rho=\frac{f(\boldsymbol{x}+\Delta\boldsymbol{x})-f(\boldsymbol{x})}{\boldsymbol{J}(\boldsymbol{x})^T\Delta\boldsymbol{x}}
ρ=J(x)TΔxf(x+Δx)−f(x)
- 给定初始值 x 0 \boldsymbol{x}_0 x0, 初始优化半径 μ \mu μ
- 对第
k
k
k次迭代, 在高斯牛顿法基础上加上信赖区域
min Δ x k 1 2 ∣ ∣ f ( x k ) + J ( x k T Δ x k ∣ ∣ 2 , s s . t . ∣ ∣ D Δ x k ∣ ∣ 2 ≤ μ \min_{\Delta x_k}\frac{1}{2}||f(\boldsymbol{x}_k)+\boldsymbol{J}(\boldsymbol{x}_k^T\Delta\boldsymbol{x}_k||^2, ~~s{\rm s.t.}~~ ||\boldsymbol{D}\Delta\boldsymbol{x}_k||^2\leq\mu Δxkmin21∣∣f(xk)+J(xkTΔxk∣∣2, ss.t. ∣∣DΔxk∣∣2≤μ
μ \mu μ:信赖区域半径, D \boldsymbol{D} D系数矩阵 - 计算
ρ
\rho
ρ
ρ = f ( x + Δ x ) − f ( x ) J ( x ) T Δ x \rho=\frac{f(\boldsymbol{x}+\Delta\boldsymbol{x})-f(\boldsymbol{x})}{\boldsymbol{J}(\boldsymbol{x})^T\Delta\boldsymbol{x}} ρ=J(x)TΔxf(x+Δx)−f(x) - 若 ρ > 3 4 \rho>\frac{3}{4} ρ>43: 设 μ = 2 μ \mu=2\mu μ=2μ ; 若 ρ < 1 4 \rho<\frac{1}{4} ρ<41: 设 μ = 0.5 μ \mu=0.5\mu μ=0.5μ
- 若 ρ \rho ρ>某与之, 近似可行, 令 x k + 1 = x k + Δ x k \boldsymbol{x}_{k+1}=\boldsymbol{x}_k+\Delta\boldsymbol{x}_k xk+1=xk+Δxk
- 判断算法是否收敛, 收敛结束, 不收敛->2.
- 给
Δ
x
\Delta\boldsymbol{x}
Δx加信赖区域
通常当问题性质较好时, 用高斯牛顿法; 问题接近病态, 用列-马法
图优化理论
- 图优化: 把优化问题表现成图的一种方式
- 图: 图论的图
- 顶点: 优化变量
- 边: 误差项
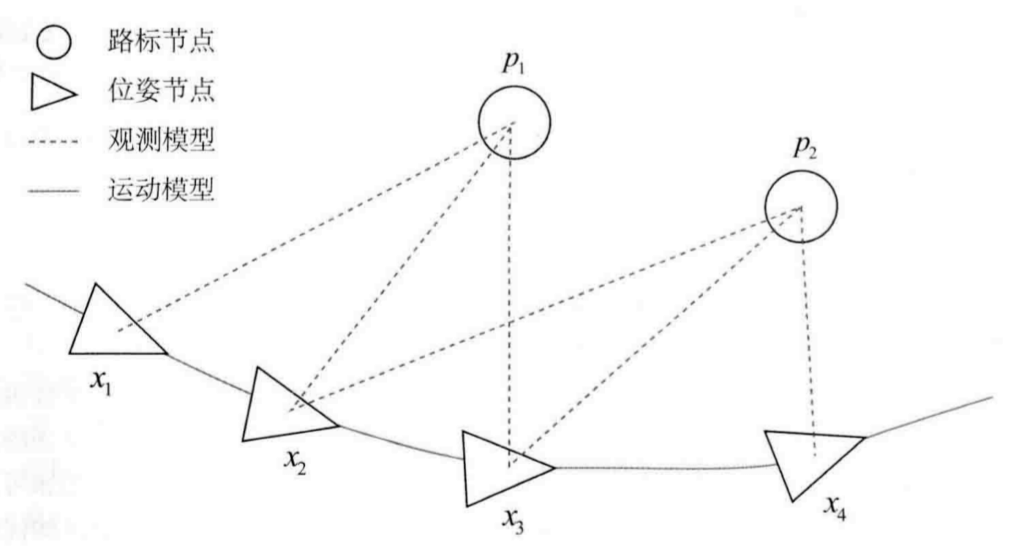
- 曲线拟合
- 只有一个顶点
- 边都是一元边: 只连接一个顶点
- 优化步骤
- 定义顶点与边的类型
- 构建图
- 选择优化算法
- 调用g2o优化, 返回结果
- C++类继承
- 虚函数
实现
ref
- Ceres库安装踩坑(SLAM十四讲)
- undefined reference to `ceres::Problem::Problem()
- CMakeLists.txt添加
main.cpp
- CMakeLists.txt添加
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <eigen3/Eigen/Core>
#include <eigen3/Eigen/Dense>
#include <ceres/ceres.h>
#include <g2o/core/g2o_core_api.h>
#include <g2o/core/base_vertex.h>
#include <g2o/core/base_unary_edge.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
#include <g2o/core/optimization_algorithm_gauss_newton.h>
#include <g2o/core/optimization_algorithm_dogleg.h>
#include <g2o/solvers/dense/linear_solver_dense.h>
#include <cmath>
// #include <chrono>
using namespace std;
using namespace Eigen;
int GaussNewton();
int CeresCurveFit();
int main(int argc, char **argv) {
// GaussNewton();
CeresCurveFit();
return 0;
}
int GaussNewton()
{
double ar = 1.0, br = 2.0, cr = 1.0; // 真实参数值
double ae = 2.0, be = -1.0, ce = 5.0; // 估计参数值
int N = 100; // 数据点
double w_sigma = 1.0; // 噪声Sigma值
double inv_sigma = 1.0 / w_sigma;
cv::RNG rng; // OpenCV随机数生成器
vector<double> x_data, y_data;
for(int i=0; i<N; i++)
{
double x = i/100.0;
x_data.push_back(x);
y_data.push_back(exp(ar*x*x + br*x + cr) + rng.gaussian(w_sigma*w_sigma));
}
// Gauss-Newton Iteration
int iterations = 100;
double Cost = 0, LastCost = 0;
for(int iter = 0; iter<iterations; iter++)
{
Matrix3d H = Matrix3d::Zero();
Vector3d b = Vector3d::Zero();
Cost = 0;
for(int i=0; i<N; i++)
{
double xi = x_data[i], yi = y_data[i]; // 数据点1
double error = yi - exp(ae*xi*xi + be*xi + ce);
Vector3d J; // 雅可比矩阵
J[0] = -xi*xi * exp(ae*xi*xi + be*xi + ce);
J[1] = -xi * exp(ae*xi*xi + be*xi + ce);
J[2] = -exp(ae*xi*xi + be*xi + ce);
H += inv_sigma*inv_sigma*J*J.transpose();
b += -inv_sigma*inv_sigma*error*J;
Cost += error*error;
}
Vector3d dx = H.ldlt().solve(b);
if(iter > 0 && Cost >= LastCost)
{
cout << "Cost:" << Cost << " >= LastCost " << LastCost << endl;
break;
}
ae += dx[0];
be += dx[1];
ce += dx[2];
LastCost = Cost;
cout << "iteration" << iter << "times" << endl;
}
cout << "estimate abc = " << ae << ", " << be << ", " << ce << ", " << endl;
}
struct CURVE_FITTING_COST
{
CURVE_FITTING_COST(double x, double y) : _x(x), _y(y) {}
template<typename T>
bool operator()(const T *const abc, T *residual) const {
residual[0] = T(_y) - ceres::exp(abc[0]*T(_x)*T(_x) + abc[1]*T(_x) + abc[2]);
return true;
}
const double _x, _y;
};
int CeresCurveFit()
{
double ar = 1.0, br = 2.0, cr = 1.0; // 真实参数值
double ae = 2.0, be = -1.0, ce = 5.0; // 估计参数值
int N = 100; // 数据点
double w_sigma = 1.0; // 噪声Sigma值
double inv_sigma = 1.0 / w_sigma;
cv::RNG rng; // OpenCV随机数生成器
vector<double> x_data, y_data;
for(int i=0; i<N; i++)
{
double x = i/100.0;
x_data.push_back(x);
y_data.push_back(exp(ar*x*x + br*x + cr) + rng.gaussian(w_sigma*w_sigma));
}
double abc[3] = {ae, be, ce};
ceres::Problem problem;
for(int i=0; i<N; i++)
{
problem.AddResidualBlock(
new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3>(
new CURVE_FITTING_COST(x_data[i], y_data[i])
),
nullptr,
abc
);
}
ceres::Solver::Options options;
options.linear_solver_type = ceres::DENSE_NORMAL_CHOLESKY;
options.minimizer_progress_to_stdout = true;
ceres::Solver::Summary summary;
ceres::Solve(options, &problem, &summary);
cout << summary.BriefReport() << endl;
for(auto a:abc)cout << a << " ";
}
class CurveFittingVertex : public g2o::BaseVertex<3, Eigen::Vector3d>{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
virtual void setToOriginImpl()override{
_estimate << 0,0,0;
}
virtual void oplusImpl(const double *update)override{
_estimate += Eigen::Vector3d(update);
}
virtual bool read(istream &in){}
virtual bool write(ostream &out)const{}
};
class CurveFittingEdge : public g2o::BaseUnaryEdge<1, double, CurveFittingVertex> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
CurveFittingEdge(double x) : BaseUnaryEdge(), _x(x) {}
virtual void computeError() override{
const CurveFittingVertex *v = static_cast<const CurveFittingVertex *>(_vertices[0]);
const Eigen::Vector3d abc = v->estimate();
_error(0,0) = _measurement - std::exp(abc(0,0)*_x*_x + abc(1,0)*_x + abc(2,0));
}
virtual void linearizeOplus() override{
const CurveFittingVertex *v = static_cast<const CurveFittingVertex *>(_vertices[0]);
const Eigen::Vector3d abc = v->estimate();
double y = exp(abc[0]*_x*_x + abc[1]*_x + abc[2]);
_jacobianOplusXi[0] = -_x*_x*y;
_jacobianOplusXi[1] = -_x*y;
_jacobianOplusXi[2] = -y;
}
virtual bool read(istream &in){}
virtual bool write(ostream &out)const{}
public:
double _x;
};
int g20CurveFitting()
{
double ar = 1.0, br = 2.0, cr = 1.0; // 真实参数值
double ae = 2.0, be = -1.0, ce = 5.0; // 估计参数值
int N = 100; // 数据点
double w_sigma = 1.0; // 噪声Sigma值
double inv_sigma = 1.0 / w_sigma;
cv::RNG rng; // OpenCV随机数生成器
vector<double> x_data, y_data;
for(int i=0; i<N; i++)
{
double x = i/100.0;
x_data.push_back(x);
y_data.push_back(exp(ar*x*x + br*x + cr) + rng.gaussian(w_sigma*w_sigma));
}
typedef g2o::BlockSolver<g2o::BlockSolverTraits<3,1>> BlockSolverType;
typedef g2o::LinearSolverDense<BlockSolverType::PoseMatrixType> LinearSolverType;
auto solver = new g2o::OptimizationAlgorithmGaussNewton(
g2o::make_unique<BlockSolverType>(g2o::make_unique<LinearSolverType>()));
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm(solver);
optimizer.setVerbose(true);
CurveFittingVertex *v = new CurveFittingVertex();
v->setEstimate(Eigen::Vector3d(ae,be,ce));
v->setId(0);
optimizer.addVertex(v);
for(int i=0; i<N; i++)
{
CurveFittingEdge *edge = new CurveFittingEdge(x_data[i]);
edge->setId(i);
edge->setVertex(0,v);
edge->setMeasurement(y_data[i]);
edge->setInformation(Eigen::Matrix<double,1,1>::Identity() * 1 / (w_sigma*w_sigma));
optimizer.addEdge(edge);
}
optimizer.initializeOptimization();
optimizer.optimize(10);
Eigen::Vector3d abc_estimate = v->estimate();
cout << "estimated model: " << abc_estimate.transpose();
}
CMakeLists.txt
cmake_minimum_required(VERSION 2.6)
project(test_optimize)
add_executable(test_optimize main.cpp)
find_package(OpenCV REQUIRED)
find_package(Ceres REQUIRED)
install(TARGETS test_optimize RUNTIME DESTINATION bin)
target_link_libraries(test_optimize ${OpenCV_LIBS})
target_link_libraries(test_optimize ${CERES_LIBRARIES})
target_link_libraries(test_optimize ${G2O_LIBS})















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









