






 本文介绍了如何使用MATLAB 2020b的强化学习库训练双足机器人行走。作者从基础的强化学习概念出发,详细解释了DDPG和TD3算法在该案例中的应用,以及环境、智能体、状态和动作等关键概念。通过理解MATLAB提供的双足机器人行走算例,作者解析了训练过程和参数设置,并探讨了如何根据自己的需求修改算例以进行强化学习研究。
本文介绍了如何使用MATLAB 2020b的强化学习库训练双足机器人行走。作者从基础的强化学习概念出发,详细解释了DDPG和TD3算法在该案例中的应用,以及环境、智能体、状态和动作等关键概念。通过理解MATLAB提供的双足机器人行走算例,作者解析了训练过程和参数设置,并探讨了如何根据自己的需求修改算例以进行强化学习研究。
%写在前面:
本人大四狗一名,不是计算机专业,所以这方面比较菜。最近在学习强化学习的一些算法,python更新太快,很多一两年前的学习资料就不太能用了,涉及到版本匹配和语法的更改等一系列问题。2020b的matlab中加入了DDPG\TD3\PPO等算法的强化学习算例和强化学习库,于是想用matlab来做强化学习。
最近看了看官方给出的双足机器人算例,注意到网上一般是这个算例的中文翻译,并没有对各种关节展开说明,于是想与和我一样看不懂算例,不明白原理的小白们共同讨论,共同进步,如果写的哪里不对,还请各位大佬多多指教。
matlab双足机器人强化学习算例介绍
matlab2020b版本中给出了 双足机器人直线行走的相关算例,这个算例是利用强化学习算法,使得小机器人能用最小的控制力让其能沿着一条直线行走下去,如下图,控制六个关节的输出力矩来达成目标。
算例中使用的是强化学习库中的函数来搭建模型和env与模型交互的学习框架。应用的是DDPG和TD3两种算法来完成学习任务,在matlab命令行中输入
openExample('control_deeplearning/TrainBipedRobotToWalkUsingReinforcementLearningAgentsExample')
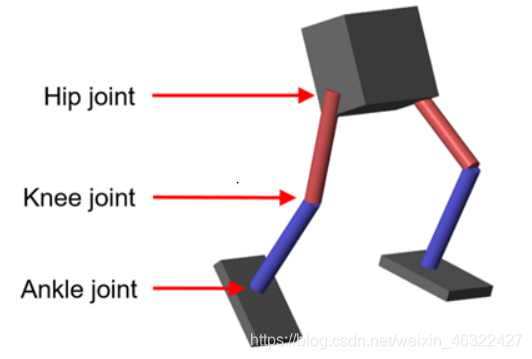
强化学习的一些基础理解
我理解强化学习就是一个在不断试错的过程中学习的过程,这和人类幼崽学习一件事物是比较相似的,比如婴儿学习抓取,爬,走路,都是跌跌撞撞地不断进步的,谁家的小孩儿不摔跤呢?这个过程对于学习行走地小孩儿来说,就是不断试错的过程。
比如:面对左脚在前,右脚在后的情况,该如何抉择呢?在没有经验的基础上可以随即决策。比如先迈了左脚,导致劈叉,裤裆疼,相当于收到了环境给出了反馈。小孩儿学会了在左脚在前,右脚在后的情况下先迈左脚就会摔倒或者受伤。下一次面临相似的抉择时就可以做出先迈右脚的决策,在先迈右脚比先迈左脚优先级更高的情况下(因为先迈左脚会受伤,而不是先迈右脚会成功),选择先迈右脚,这时成功走出一步,说明在这种情况下先迈右脚是一个比较成功的决策,那么小孩儿就学会了在这种情况下该如何决策才能完成行走。
对于智能体来说,强化学习的过程和上述的过程是类似的,实际上不同算法的核心思想都是如此,只是实现的手段上有所不同。相信想要学习强化学习的同学都一定听说过Q-learning算法,这种算法就是针对不同决策给一个价值表或者叫Q表,比如针对上述问题,在左脚在前,右脚在后的状态下有一个对两种决策的价值表[-1;1];-1代表先迈左脚的价值,1代表先迈右脚的价值,这是就很好选择了,选择1就对了。这时针对离散动作的抉择方法,如果对于连续的动作可以通过均值和方差的方法来定义。不同任务可以选择不同算法,但是各类任务的总体思想都是随即给出动作,环境给出奖励,智能体根据奖励更新策略的循环。
菜鸟对一些名词的理解
在上述理解的基础上,理解一些名词就比较方便了,要完成一个强化学习任务,就可以通过定义环境env,奖励函数reward,仿真结构(walking robot),学习算法,逼近函数来进行学习了。
状态observation,这个单词直接的翻译是观察,我理解这个词的意义是状态,相当于传感器对于状态量的观测,在python一些算法中会用到“observation_”这个变量,代表的是下一时刻的状态量。这是由于在计算reward时会用到下一个状态值。在迭代的过程中,先后顺于是:由此时此刻的状态observation根据某些策略(如e-greedy策略)得出这一时刻的动作值,再将动作和状态交给环境仿真模型来计算得出下一时刻的状态值observation_,再借助observation_的好坏来评估action的好坏,由env返回reward用于更新智能体的策略。
动作action动作就是智能体可以做出的动作,在面对一个状态observation时能够选择的动作,可以是连续的也可以是离散的,环境env再根据observation和action来给出下一时刻的状态。
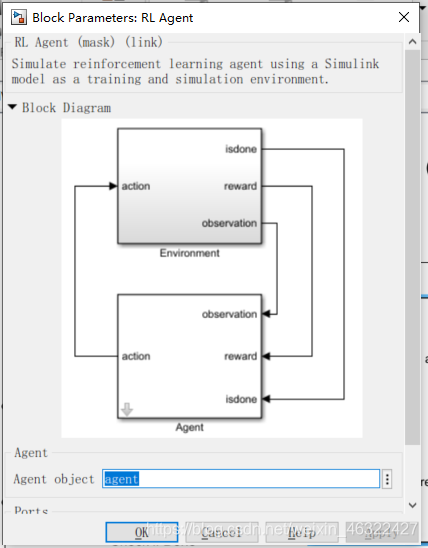
环境env,在算例中,env是这么描述的:
mdl = 'rlWalkingBipedRobot';%simulink文件的名字
blk = [mdl,'/RL Agent'];%RL Agent是simulink(mdl)中的一个模块,代表整个环境和智能体交互的过程,包括智能体和环境。见下图。
env = rlSimulinkEnv(mdl,blk,obsInfo,actInfo);%代表env是simulink(mdl)中的blk这个模块,observation是obsInfo、action是actInfo。
env.ResetFcn = @(in) walkerResetFcn(in,upper_leg_length/100,lower_leg_length/100,h/100);%在env中加入reset函数
所以,环境就是可以根据状态量给出反馈,又称奖励reward。
模型,模型就是搭建的仿真模型,一般是几个微分方程,可以根据动作量给出下一个状态量。
matlab强化学习库介绍
在matlab中的强化学习库就是一系列封装好的函数,包括环境搭建、智能体搭建、训练函数、各种模型参数设置等众多函数。在matlab的官网可以查到各个函数的help,具体请各位异步:https://ww2.mathworks.cn/help/reinforcement-learning/referencelist.html?type=function
里面是matlab强化学习的各类函数介绍。
双足机器人算例逻辑盘点
首先,初始化变量。加载一个变量包。
robotParametersRL;
第二步,打开simulink模型。
mdl = 'rlWalkingBipedRobot';
open_system(mdl)
第三步,建立连续的状态变量向量,29*1,类似python里面的tf.placeholder,是一种初始化,又称占着**不拉 *。
mdl = 'rlWalkingBipedRobot';
open_system(mdl)
第四步,建立连续的动作变量向量,6*1.
numAct = 6;
actInfo = rlNumericSpec([numAct 1],'LowerLimit',-1,'UpperLimit',1);
actInfo.Name = 'foot_torque';
第五步,利用simulink模型建立环境。注释在上文提及过,自行观看。
blk = [mdl,'/RL Agent'];
env = rlSimulinkEnv(mdl,blk,obsInfo,actInfo);
env.ResetFcn = @(in) walkerResetFcn(in,upper_leg_length/100,lower_leg_length/100,h/100);
第六步,选择学习途径,也就是算法种类了,这个例子中可以使用TD3或者DDPG,这里语法很好理解,不多赘述。
AgentSelection = 'TD3';
switch AgentSelection
case 'DDPG'
agent = createDDPGAgent(numObs,obsInfo,numAct,actInfo,Ts);
case 'TD3'
agent = createTD3Agent(numObs,obsInfo,numAct,actInfo,Ts);
otherwise
disp('Enter DDPG or TD3 for AgentSelection')
end
第七步,训练参数设置。具体见备注,或者见help(https://ww2.mathworks.cn/help/reinforcement-learning/ref/rltrainingoptions.html)
maxEpisodes = 2000;
maxSteps = floor(Tf/Ts);
trainOpts = rlTrainingOptions(...
'MaxEpisodes',maxEpisodes,...%训练集最大值
'MaxStepsPerEpisode',maxSteps,...%每次喂入网络的数据集大小,这样调用神经网络事件较快,且一定程度上避免练偏。
'ScoreAveragingWindowLength',250,...%窗口长度,不太重要。
'Verbose',false,...%在命令行输出训练进度
'Plots','training-progress',...%可视化
'StopTrainingCriteria','EpisodeCount',...%训练停止条件
'StopTrainingValue',maxEpisodes,...%终止训练条件。
'SaveAgentCriteria','EpisodeCount',...%保存网络的条件
'SaveAgentValue',maxEpisodes);%保存网络的条件
trainOpts.UseParallel = true;%是否并行训练
trainOpts.ParallelizationOptions.Mode = 'async';%并行计算模式
trainOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;%向主机发送数据的步骤数
trainOpts.ParallelizationOptions.DataToSendFromWorkers = 'Experiences';%发送给主机的数据类型
步骤八,利用环境和智能体交互来训练网络(train)。例子中可以选择自己训练或者加载数据。
doTraining = 1;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainOpts);
else
% Load a pretrained agent for the selected agent type.
if strcmp(AgentSelection,'DDPG')
load('rlWalkingBipedRobotDDPG.mat','agent')
else
load('rlWalkingBipedRobotTD3.mat','agent')
end
end
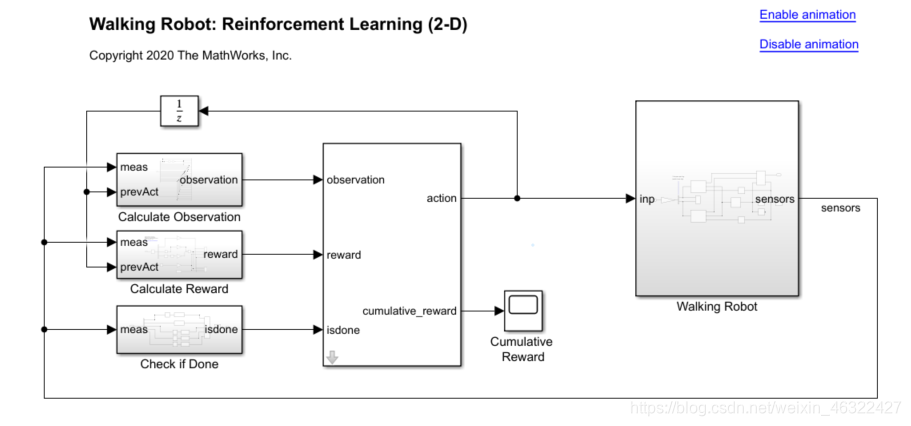
到这里训练就已经完成了,之后的代码是为了进行可视化和比较,在这里不多讨论。
如何改写算例做自己的强化学习。
在上文中,对算例有了一个大概的介绍,那么,学会了例子并不是最终目的,怎么修改这个例子来为自己服务呢?在这个框架上不需要改动太多,只要把每部分都替换成自己要研究问题的公式就可以了。比如,这里的动力学建模是一个双足机器人,把他的动力学模型改变一下,也就是改变了收到动作和状态得出的新状态。
对应不同目标的任务就要改变reward模块儿,用reward来训诫智能体做出希望的动作。
改变结束学习的判定条件,能省点儿时间就是点儿吧。
再在m文件中把需要初始化的各个数据改成自己需要的,bang!属于你的强化学习模型就搭建出来了。
%写在最后,水平有限,请有幸看到的您多多指正。在工作之余,祝您早安,午安,晚安。Have a nice day。
(可能的话点个赞再走吧)

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









