






0. 论文信息
标题:DC-Gaussian: Improving 3D Gaussian Splatting for Reflective Dash Cam Videos
作者:Linhan Wang, Kai Cheng, Shuo Lei, Shengkun Wang, Wei Yin, Chenyang Lei, Xiaoxiao Long, Chang-Tien Lu
机构:Virginia Tech、Hong Kong University、USTC、University of Adelaide、CAIR、Sony Research
原文链接:https://arxiv.org/abs/2405.17705
代码链接:https://github.com/linhanwang/DC-Gaussian
1. 摘要
我们提出了DC-高斯,一种从车载仪表盘摄像头视频生成新视图的新方法。虽然神经渲染技术在驾驶场景中取得了长足的进步,但现有的方法主要是为自动车辆收集的视频设计的。然而,与dash cam视频相比,这些视频在数量和多样性方面都是有限的,dash cam视频更广泛地用于各种类型的车辆,并捕捉更广泛的场景。Dash cam视频经常遭受严重的障碍,例如挡风玻璃上的反射和遮挡,这极大地阻碍了神经渲染技术的应用。为了应对这一挑战,我们基于最近的实时神经渲染技术3D Gaussian Splatting (3DGS)开发了DC-高斯。我们的方法包括一个自适应图像分解模块,以统一的方式模拟反射和遮挡。此外,我们引入了照明感知障碍建模,以管理不同照明条件下的反射和遮挡。最后,我们采用几何引导的高斯增强策略,通过加入额外的几何先验来改善渲染细节。在自拍和公共dash cam视频上的实验表明,我们的方法不仅在新颖的视图合成方面达到了最先进的性能,而且在消除障碍物的情况下准确地重建了拍摄的场景。
2. 引言
神经辐射场(NeRF)凭借其可微体积渲染技术,彻底革新了基于图像的渲染领域。三维高斯溅射(3DGS)则以实时渲染速度进一步推动了这一领域的发展。这些技术已被应用于自动驾驶汽车采集的数据集,为自动驾驶领域开辟了众多新的可能性,例如模拟驾驶场景以进行感知模型的鲁棒性训练,以及提供有效的三维场景表征来增强对环境的综合理解。尽管这些数据集提供了多模态传感器数据,但它们在真实驾驶场景中的多样性仍然有限。
幸运的是,行车记录仪视频深刻反映了真实交通场景的多样性和复杂性。它们以众包的方式提供了大规模、多样化的驾驶视频数据集。行车记录仪视频还通过捕捉多主体驾驶行为和评估视觉危害下算法的鲁棒性,提供了独特价值。此外,随着人们对车辆安全意识的提高,全球行车记录仪市场正在迅速扩张。因此,探索在神经渲染中利用行车记录仪数据展现出巨大潜力,为自动驾驶应用提供了海量数据。
尽管存在一些基于单图像的去遮挡方法,但直接将其应用于此任务并非易事。这些遮挡物来自各种源头,而现有的去除方法对遮挡物施加了严格假设。例如,基于失焦和鬼影线索的假设使得先前的方法在特定情况下表现良好,但这些假设在行车记录仪视频中并不总是成立。此外,基于学习的方法对于分布外图像的性能会下降。一些NeRF方法尝试通过分解传输(背景场景)和反射,使用独立的NeRF来重建包含反射的场景。这种方法可以受益于NeRF强大的多视角聚合能力。然而,先前的方法对于行车记录仪视频来说是不够的,因为挡风玻璃上的遮挡物与NeRF的设计不太吻合。NeRF旨在处理静态场景,而挡风玻璃及其反射物体随车辆移动。
3. 效果展示
给定由行车记录仪捕获的视频序列,该序列可能包含如反射和遮挡等障碍物,DC-Gaussian方法能够实现高保真度的无障碍新视角合成。(a) 行车记录仪;(b) 原始视频帧;(c) 去除障碍物后的新视角渲染。

然而,直接在行车记录仪视频上训练3DGS往往会导致渲染质量和几何形状的显著恶化。这种退化主要是由于挡风玻璃上普遍存在遮挡物(如手机支架和污渍产生的反射和遮挡,如图2所示)。在这些场景下,3DGS将遮挡物建模为静态几何形状,而它们本质上是动态的(随车辆移动),因此不可避免地会在新视角下产生几何形状不准确和渲染模糊的问题。推荐课程:多传感器标定不得不聊的20种标定方案(Lidar/Radar/Camera/IMU等)。

4. 主要贡献
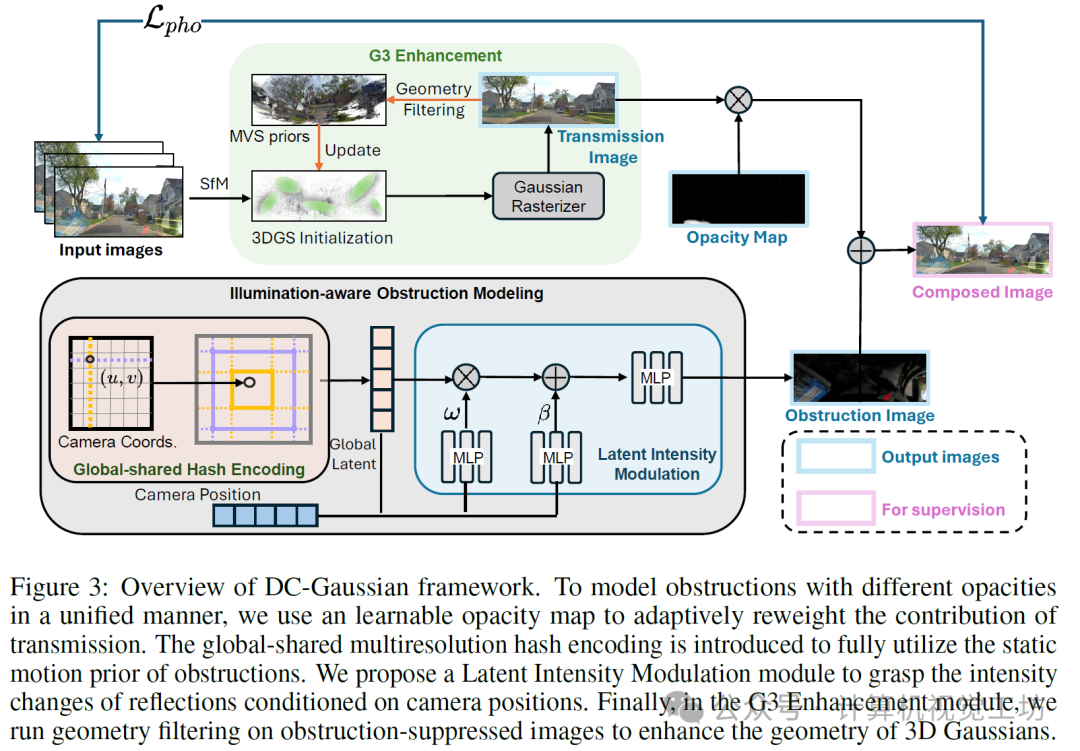
在本文中,我们介绍了DC-Gaussian,这是一种从行车记录仪视频中建模高保真无遮挡三维高斯溅射的方法。我们提出了三项关键创新:1)自适应图像分解。为了清晰分解包含复杂反射和遮挡的图像,我们提出了一种自适应图像分解方法。我们使用不透明度图来学习挡风玻璃的透射率,从而自适应地估计背景场景对图像的贡献。2)光照感知遮挡建模(IOM)。我们观察到遮挡物主要是由相对于行车记录仪静止的物体造成的,但遮挡物因光照变化而呈现出不同的效果。因此,我们提出对所有视角共享的全局遮挡进行建模。此外,还引入了一种新颖的潜在强度调制(LIM)模块,以学习场景中的光照变化,并能够实现不同强度反射的合成。3)几何引导高斯增强(G3E)。我们进一步利用多视角立体视觉将几何先验引入3DGS训练,从而增强了3DGS渲染的细节和清晰度。
为了评估我们方法的有效性,我们在公共数据集和自采集数据集上进行了大量实验。实验表明,我们的方法不仅实现了最先进的新视角合成,还从神经渲染中清晰地去除了遮挡物。
5. 方法
DC-Gaussian框架概述。为了以统一的方式对不同不透明度的障碍物进行建模,我们使用可学习的不透明度图来自适应地重新加权传输的贡献。我们引入了全局共享的多分辨率哈希编码,以充分利用障碍物的静态运动先验。我们提出了一个潜在强度调制模块,以根据相机位置捕捉反射强度的变化。最后,在G3增强模块中,我们对去除障碍物后的图像进行几何滤波,以增强3D高斯体的几何结构。
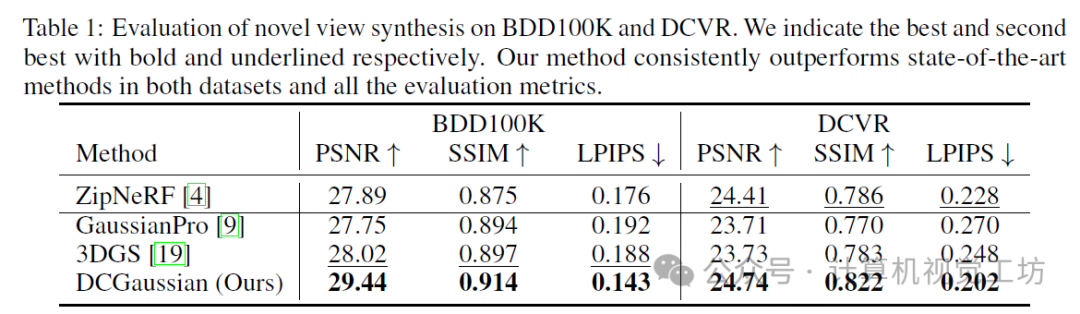
6. 实验结果

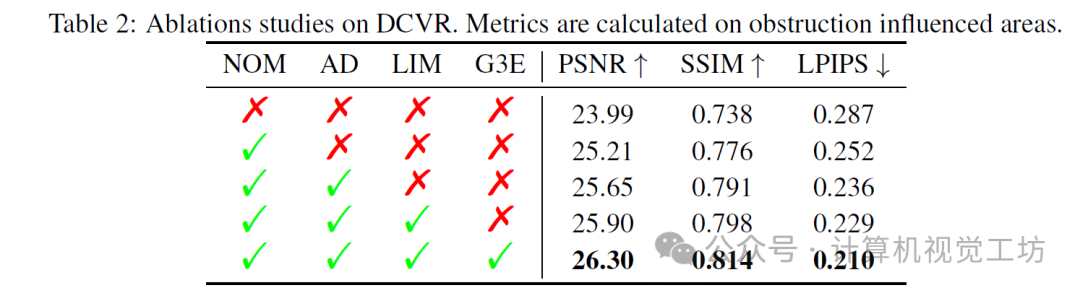
7. 总结 & 未来工作
综上所述,我们提出了DC-Gaussian方法,该方法有效地解决了将3D高斯溅射扩展到行车记录仪视频中的挑战。在BDD100K和DCVR数据集上的实验表明,该方法在渲染质量和图像分解方面取得了显著提升,为基于行车记录仪视频的神经渲染设立了新的基准。
局限性与未来工作:目前,DC-Gaussian仅针对单序列视频进行了评估。然而,考虑到海量的行车记录仪视频资料,将DC-Gaussian扩展到多序列视频设置,并利用密集视图图像以获得更令人满意的结果,将是未来研究的一个有前景的方向。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。

















 3045
3045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









