






0. 论文信息
标题:Towards Global Localization using Multi-Modal Object-Instance Re-Identification
作者:Aneesh Chavan, Vaibhav Agrawal, Vineeth Bhat, Sarthak Chittawar, Siddharth Srivastava, Chetan Arora, K Madhava Krishna
机构:Robotics Research Center, IIIT Hyderabad、is with IIT Delhi、Typeface Inc
原文链接:https://arxiv.org/abs/2409.12002
1. 摘要
重新识别(ReID)是计算机视觉中的一个关键挑战,主要在行人和车辆的背景下进行研究。然而,健壮的对象实例ReID对自主探索、长期感知和场景理解等任务具有重要意义,但仍未得到充分探索。在这项工作中,我们通过提出一种新的双路径对象实例重识别转换器架构来解决这一差距,该架构集成了多模态RGB和深度信息。通过利用深度数据,我们展示了在杂乱或具有不同照明条件的场景中ReID的改进。此外,我们开发了一个基于ReID的定位框架,能够跨不同视点进行精确的摄像机定位和姿态识别。我们使用两个定制的RGB-D数据集以及来自开源TUM RGB-D数据集的多个序列来验证我们的方法。我们的方法在对象实例ReID (mAP为75.18)和定位精度(TUM-RGBD上的成功率为83%)方面都有显著提高,突出了对象ReID在推进机器人感知方面的重要作用。我们的模型、框架和数据集已经公开。
2. 引言
环境中的物体可以作为重要的地标,并为空间认知和定位提供重要线索。它们为理解智能体的总体位置和精确方向提供了宝贵信息。然而,物体可靠的重识别——正式称为物体实例重识别任务——仍研究不足,特别是在机器人学的背景下。
物体实例重识别(ReID),通常简称为物体ReID,是指在不同视角和环境条件下可靠识别并匹配同一物体的不同实例的任务。例如,在仓库环境中,物体ReID可用于跨多个摄像头视图跟踪同一设备,即使光照或设备位置发生变化。尽管针对特定类别(如行人和车辆)的ReID已进行了大量研究,这些研究通常利用步态模式或车辆参数等特定领域的特征,但物体ReID这一更广泛的领域则面临着独特挑战。物体的结构、外观和类型差异巨大,缺乏统一的共同特征。基础模型如DINOv2和视觉-语言模型如CLIP[8]虽能提供大致分类,但在这些类别内重新识别特定实例时却力不从心。它们泛化到新场景的能力并不足以提供精确基于物体的应用所需的精细识别。
在机器人学中,准确重识别物体的能力可广泛用于各种任务。尤其是全局重定位,这是一项关键应用,其中准确的物体ReID可以显著提升性能。在具有重复场景或众多物体和房间的环境中,这项任务尤其具有挑战性,因为这些环境中局部和全局配准困难都很常见。传统的全局重定位方法通常依赖于对齐整个点云或大量图像集合,以最大化可用信息。然而,这些信息中有很大一部分可能是冗余的,或者对有效定位没有帮助。
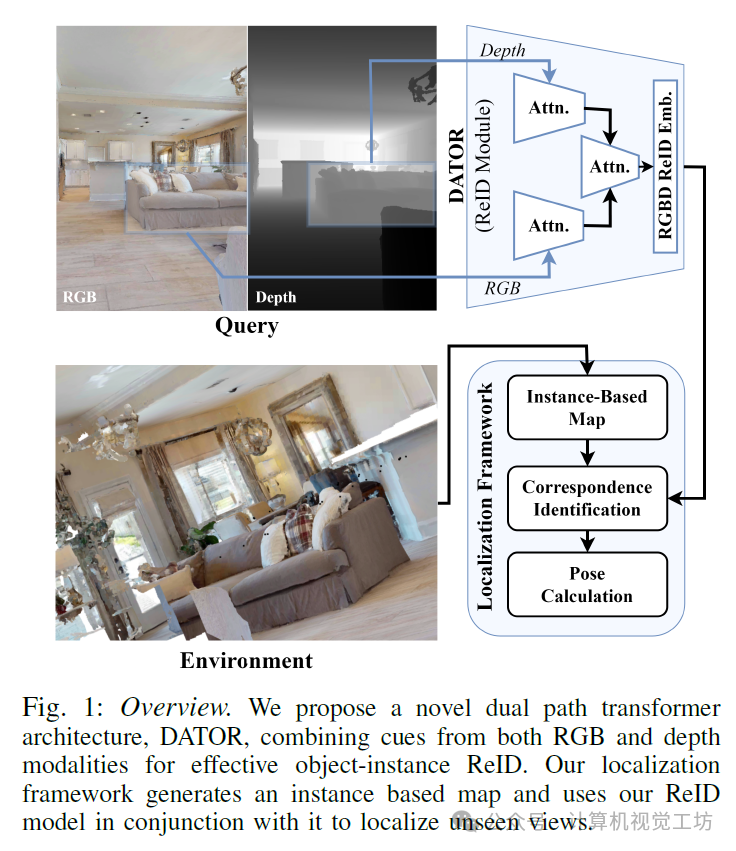
为解决这些挑战,我们引入了用于物体重识别的双路径注意力变换器(DATOR),这是一种深度物体ReID模型,利用移动机器人常用的RGB和深度传感器。DATOR采用双路径变换器架构,显著增强了其在多视图中的ReID能力。该架构从两种模态中提取并细化特征,将它们整合以生成稳健的最终嵌入。通过有效结合这两种模态,DATOR确保了物体ReID的高准确性,并在不同的光照条件和多样的环境设置中保持性能。
基于DATOR的精细ReID能力,我们引入了一个基于物体实例的全局定位框架。该框架在多样化的室内环境中有效运行,无需手动物体标注。受人类在熟悉环境中导航的启发,我们的方法通过映射可见物体来构建基于实例的地图,遵循与讨论的原则类似的原则。我们使用ReID模型对物体进行编目和编码,保留视觉和结构信息,同时通过单个物体的点云保持位置数据。对于定位,我们处理查询RGB-D视图以检测和匹配可见物体与物体地图中的物体,优化对齐以实现准确定位。
为验证我们的框架,我们提供了一个来自大型、物体丰富的实验室环境的真实世界数据集,该环境包含每个物体类别的多个实例(如桌子、椅子),呈现了一个具有挑战性的ReID场景。此外,我们还提供了一个包含多个类别物体的真实以及合成室内数据集,用于全局定位的基准测试。我们还将我们的方法与来自TUMRGB-D数据集的序列进行了基准测试。
3. 效果展示
我们提出了一种新颖的双路径Transformer架构,即DATOR,该架构结合了RGB和深度模态的线索,以实现有效的目标实例重识别(ReID)。我们的定位框架生成一个基于实例的地图,并结合我们的ReID模型来定位未见视图。
4. 主要贡献
我们做出了以下贡献:
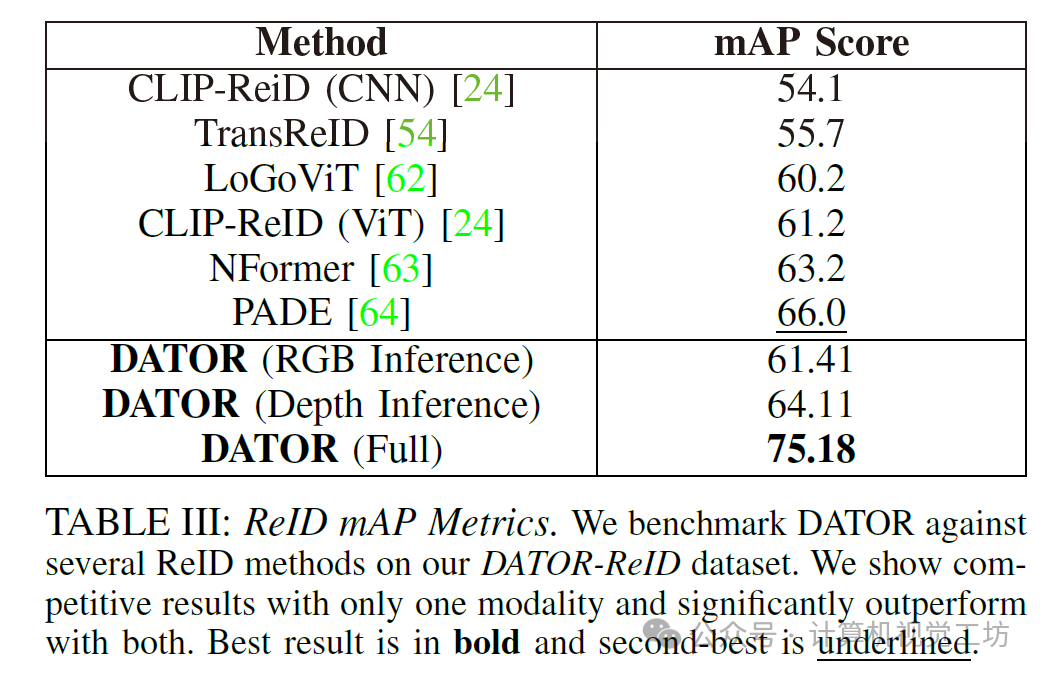
• 一种多模态RGB-D物体实例ReID模型(DATOR),实现了75.18%的mAP,高于其他最优模型。推荐课程:国内首个面向具身智能方向的理论与实战课程。
• 一种基于物体实例ReID的全局定位框架,无需手动标注,可在室内环境中实现高精度,在密集、公开可用的数据集上成功定位83.01%的时间。
• 一个全面的物体实例ReID数据集,包含不同光照条件下多个室内物体实例。
• 一个真实以及合成数据集,用于在复杂室内环境中进行全局定位的基准测试。
5. 方法
定位框架概述。我们的定位框架接收合成的RGBD图像,并形成一个基于对象的地图,该地图由实例及其描述符组成。给定一个查询RGB-D图像,我们使用ReID模块(DATOR)在该图像中识别对象,并在我们的地图中识别对应项。使用匹配度最高的对应项来计算姿态。

网络架构:我们提出了一种新颖的网络架构,用于利用RGB和深度模态的信息(图3)。该网络具有一个RGB路径和一个深度路径,分别接收RGB图像和深度图像作为输入。在网络内部,两个路径之间会交换信息,并最终将两个路径的特征结合起来,以生成最终的嵌入表示。

6. 实验结果

7. 总结 & 未来工作
我们提出了一种基于对象的定位框架,该框架能够在多种室内环境中实现泛化,且无需手动标注,这在自主室内导航领域取得了重大进展。我们的方法在真实环境和合成环境中均表现出准确且鲁棒的定位能力。此外,我们的重识别(ReID)架构在一个具有不同光照条件的挑战性数据集上实现了75.18%的高平均精度均值(mAP),证明了其对真实场景的适应能力。
我们模型生成的嵌入特征使得对象实例重识别的定位成功率更高,相较于其他大规模图像编码模型,该模型在TUM-RGBD的多个序列中平均成功定位率达到83.01%。此外,我们还发布了一对具有挑战性的、富含对象的真实和合成重定位数据集,以及一个包含不同光照条件的对象ReID数据集。
未来的工作包括探索扩展我们的框架,以有效识别重要的非对象地标、在室外环境中发挥作用、增强其对更极端的光照变化和遮挡情况的鲁棒性,并将其集成到移动机器人管道中。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。

















 1147
1147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









