






来源:3DCV
0. 论文信息
标题:AlterMOMA: Fusion Redundancy Pruning for Camera-LiDAR Fusion Models with Alternative Modality Masking
作者:Shiqi Sun, Yantao Lu, Ning Liu, Bo Jiang, JinChao Chen, Ying Zhang
机构:Northwestern Polytechnical University、Midea Group、Didi Chuxing
原文链接:https://arxiv.org/abs/2409.17728
1. 摘要
相机-激光雷达融合模型显著增强了自动驾驶中的感知性能。融合机制利用了每种模式的优势,同时最大限度地减少了它们的缺点。此外,在实践中,相机-激光雷达融合模型利用预先训练的主干进行有效训练。然而,我们认为,由于融合机制的性质,直接将单模态预训练相机和激光雷达主干加载到相机-激光雷达融合模型中会引入跨模态的相似特征冗余。不幸的是,现有的剪枝方法是针对单模态模型开发的,因此,它们难以有效地识别相机-激光雷达融合模型中的这些特定的冗余参数。在本文中,为了解决相机-激光雷达融合模型的上述问题,我们提出了一种新颖的修剪框架替代模态掩蔽修剪(AlterMOMA),它在每个模态上采用替代掩蔽并识别冗余参数。具体来说,当一个模态参数被屏蔽(去激活)时,屏蔽主干的特征缺失迫使模型重新激活另一个模态主干的先前冗余特征。因此,这些冗余特征和相关的冗余参数可以通过重新激活过程来识别。冗余参数可以通过我们提出的重要性分数评估函数,备选评估(AlterEva)来修剪,该评估函数基于当某些模态参数被激活和去激活时对损失变化的观察。在nuScene和KITTI数据集上进行的大量实验(包括不同的任务、基线模型和剪枝算法)表明,AlterMOMA优于现有的剪枝方法,达到了最先进的性能。
2. 引言
在自动驾驶领域,相机与激光雷达融合模型十分普遍,它们有效利用了传感器的特性,包括激光雷达点云提供的精确几何数据和相机图像提供的丰富语义上下文,从而提供了对环境更全面的理解。然而,由于融合架构导致参数数量呈指数级增长,这引入了显著的计算成本,尤其是在资源受限的边缘设备上部署这些系统时,这对自动驾驶来说是一个至关重要的挑战。网络剪枝是解决上述模型冗余识别与消除挑战的最具吸引力的方法之一。现有的剪枝算法针对的是单模态模型或多模态模型,这些多模态模型融合了不同类型的数据,如视觉和语言输入。然而,值得注意的是,直接将这些算法应用于相机与激光雷达融合模型可能会导致显著的性能下降。性能下降的原因主要在于现有剪枝方法忽略了两个主要因素:1)模型内针对视觉传感器输入的特定融合机制;2)训练方案,其中模型通常将单模态预训练参数加载到每个主干网络上。具体来说,由于单模态模型缺乏跨模态融合机制,现有的剪枝算法传统上不考虑模态间的相互作用。此外,由于预训练的主干网络(图像或激光雷达)是分别训练的,它们没有得到联合优化,从而加剧了从每个主干网络提取的特征中的冗余。尽管利用预训练的主干网络相比从头开始训练的模型提高了训练效率,但我们认为,直接将单模态预训练的相机和激光雷达主干网络加载到相机与激光雷达融合模型中,由于融合机制的特性,会在模态间引入类似的特征冗余。
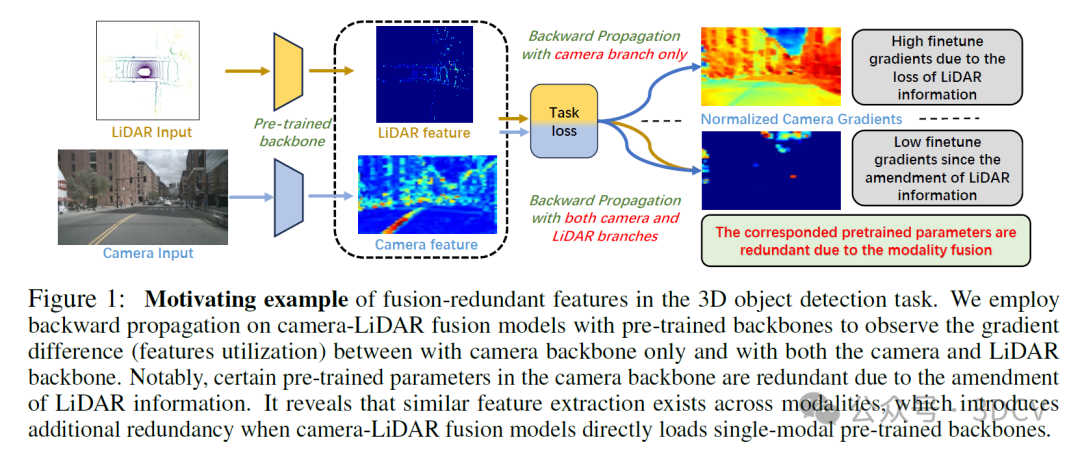
具体来说,由于主干网络是在单模态数据集上独立预训练的,它们会全面提取特征,这导致模态间提取的特征相似。同时,融合机制会选择性地利用可靠的特征,同时最小化较弱的模态间特征,以增强模型性能。这种在模态间相似特征提取基础上的选择性利用引入了额外的冗余:每个主干网络独立提取相似的特征,而后续的融合模块可能不会利用这些特征。例如,在预训练期间,相机和激光雷达主干网络都会提取几何特征以预测深度。然而,在融合过程中,从激光雷达主干网络提取的几何特征被认为更可靠,因为激光雷达输入数据包含比相机更准确的几何信息,如物体距离,这是由于传感器的物理特性。因此,这导致了相机主干网络中几何特征的冗余。综上所述,模态间的相似特征提取,加上后续融合模块中的选择性利用,导致模态间存在两类相似的特征:一类是由融合模块在某一模态中利用的特征(即融合贡献特征),另一类是在另一模态中冗余的特征(即融合冗余特征)。我们还在图1中说明了融合冗余特征。
为了解决上述挑战,我们提出了一种新的剪枝框架AlterMOMA,该框架专为相机与激光雷达融合模型设计,用于识别和剪除融合冗余参数。AlterMOMA在每个模态上采用交替掩码,然后观察当某些模态参数被激活和停用时损失的变化。这些观察结果作为识别融合冗余参数的重要指示,是我们重要性评分评估函数AlterEva的重要组成部分。具体来说,相机和激光雷达主干网络会交替被掩码。在此过程中,被掩码(停用)的主干网络中缺失的融合贡献特征和相关参数会迫使融合模块从另一个主干网络中重新激活其融合冗余对应项。在整个重新激活过程中,观察到的损失变化作为跨模态贡献和融合冗余参数的指标。然后,这些指标在AlterEva中被组合,以最大化贡献参数的重要性评分,同时最小化融合冗余参数的重要性评分。接着,将重要性评分较低的参数剪除,以降低计算成本。推荐课程:彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战。
为了验证我们提出框架的有效性,我们在多个流行的包含相机和激光雷达传感器数据的3D感知数据集上进行了大量实验,包括nuScenes和KITTI。这些数据集涵盖了多种3D自动驾驶任务,包括3D目标检测、跟踪和分割。
3. 效果展示
3D目标探测任务中融合冗余特征的激励示例。我们在具有预训练主干的相机-激光雷达融合模型上采用反向传播,以观察仅具有相机主干和具有相机和激光雷达主干两者之间的梯度差异(特征利用)。值得注意的是,由于LiDAR信息的修改,相机中枢中的某些预训练参数是多余的。它揭示了相似的特征提取存在于各模态之间,这在相机-激光雷达融合模型直接加载单模态预训练主干时引入了额外的冗余。
4. 主要贡献
本文的贡献如下:1)我们提出了一种剪枝框架AlterMOMA,以有效压缩相机与激光雷达融合模型;2)我们提出了一种重要性评分评估函数AlterEva,用于跨模态识别融合冗余特征及其相关参数;3)我们在nuScenes和KITTI数据集上验证了所提AlterMOMA在3D检测和分割任务中的有效性。
5. 方法
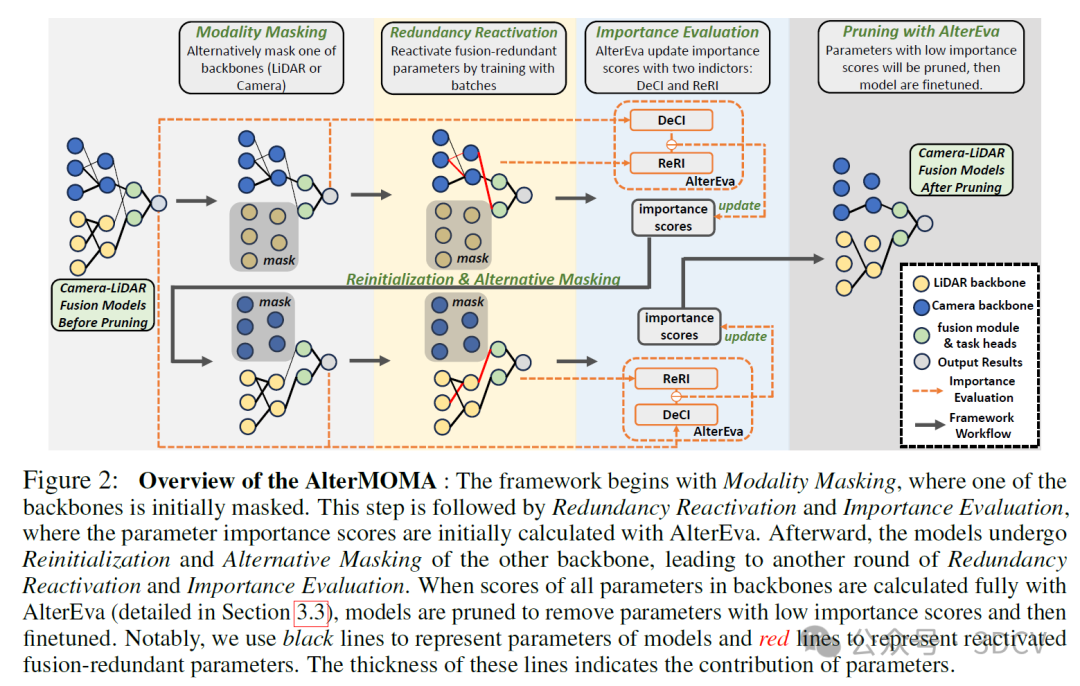
模态间的相似特征提取,加上后续融合模块对特征的选择性利用,在相机与激光雷达融合模型中引入了冗余。因此,相似的特征及其相关参数可以在模态间分为两类:一类是对融合和后续任务头有贡献的特征(即融合贡献特征),另一类是冗余的特征(即融合冗余特征)。在本节中,我们提出了剪枝框架AlterMOMA,该框架交替地对相机和激光雷达主干网络采用掩码,以识别和移除融合冗余参数。AlterMOMA是基于一个新的见解开发的:“融合贡献特征的缺失将迫使融合模块‘重新激活’其融合冗余对应项作为补充,尽管这些对应项的效果较差,但对于维持功能却是必要的。”例如,如果激光雷达主干网络被掩码,则它之前提供的融合贡献几何特征将缺失。为了满足对准确位置预测的需求,模型仍然需要处理几何特征。因此,融合模块被迫利用未掩码的相机主干网络中的几何特征,这些特征之前被认为是融合冗余的。我们将这一过程称为冗余重新激活。通过观察这一过程中的变化,可以识别出融合冗余参数。AlterMOMA的概述如图2所示。
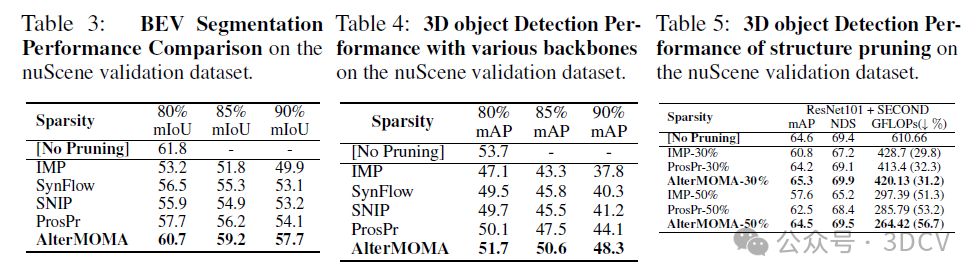
6. 实验结果
7. 总结 & 未来工作
尽管我们的方法识别出了相机-激光雷达融合模型中的相似特征冗余,但其应用仅限于感知领域。若要将其扩展到其他多模态模型(如视觉-语言模型),则还需进一步研究。跨不同模态的融合模块展现出不同的功能。在多传感器融合模型(相机、激光雷达和雷达)中,重点是利用传感器的物理特性来补充和空间对齐数据,融合低级特征。然而,在视觉和语言等数据类型不同的模型中,融合模块则侧重于匹配高级语义上下文。因此,AlterMOMA主要解决多传感器融合感知架构中由补充功能引起的冗余问题。
在本文中,我们探讨了相机-激光雷达融合模型的计算量减少问题。提出了一种名为AlterMOMA的剪枝框架,以解决这些模型中的冗余问题。AlterMOMA在每个模态上采用交替掩码,并观察在激活和停用某些模态参数时的损失变化。这些观察结果对于我们的重要性评分评估函数AlterEva至关重要。通过广泛的评估,我们提出的AlterMOMA框架实现了更好的性能,超越了单模态剪枝方法建立的基线。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~


目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

















 3391
3391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









