






0. 论文信息
标题:PixelGaussian: Generalizable 3D Gaussian Reconstruction from Arbitrary Views
作者:Xin Fei, Wenzhao Zheng, Yueqi Duan, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, Jiwen Lu
机构:Tsinghua University、University of California, Berkeley
原文链接:https://arxiv.org/abs/2410.18979
代码链接:https://github.com/Barrybarry-Smith/PixelGaussian
1. 导读
我们提出了PixelGaussian,一种有效的前馈框架,用于从任意视图学习可推广的3D高斯重建。大多数现有方法依赖于统一的像素式高斯表示,其为每个视图学习固定数量的3D高斯,并且不能很好地推广到更多的输入视图。不同的是,我们的PixelGaussian基于几何复杂度动态地适应高斯分布和数量,导致更有效的表示和重建质量的显著提高。具体来说,我们引入了级联高斯适配器来根据关键点计分器识别的局部几何复杂度调整高斯分布。CGA利用上下文感知超网络中的可变形注意力来指导高斯修剪和分裂,确保在复杂区域中的准确表示,同时减少冗余。此外,我们设计了一个基于变换器的迭代高斯细化模块,通过直接的图像-高斯交互来细化高斯表示。随着输入视图的增加,我们的像素高斯模型可以有效地减少高斯冗余。我们在大规模的ACID和RealEstate10K数据集上进行了大量的实验,其中我们的方法达到了最先进的性能,并对各种数量的视图进行了良好的推广。
2. 引言
新颖视角合成(NVS)旨在从一系列输入视角中重建3D场景,并从未见过的视角生成高质量图像。高质量且实时的重建和视角合成对于自动驾驶、机器人感知以及虚拟现实或增强现实至关重要。
基于神经辐射场(NeRF)的方法通过将3D场景编码为隐式辐射场取得了显著成功,然而,为NeRF渲染采样体积在时间和内存上成本高昂。最近,Kerbl等提出使用一组3D高斯函数显式表示3D场景,通过可微光栅化实现更高效、高质量的渲染。尽管如此,原始的3D高斯溅射(Splatting)需要对每个单独的场景进行单独优化,这大大降低了推理效率。为解决这一问题,近期研究旨在通过前馈网络直接生成3D高斯函数,而无需对每个场景进行优化。通常,这些方法遵循一种范式,即为输入视角中的每个像素预测固定数量的高斯函数。然后,将从不同视角得到的高斯函数直接合并,以构建最终的3D场景表示。然而,这种范式限制了模型性能,因为高斯溅射在图像中均匀分布,难以有效捕获局部几何细节。此外,随着输入视角数量的增加,直接合并高斯函数会因视角间严重的高斯重叠和冗余而降低重建性能。
为解决这一问题,我们提出了PixelGaussian,其能够在3D高斯分布和数量上实现动态适应。具体而言,我们首先根据Chen等的方法均匀初始化高斯位置,以准确定位高斯中心。为识别图像间的几何复杂度,我们然后以一种端到端的方式从图像特征中为每个输入视角计算相关性得分图。在得分图的指导下,我们构建了级联高斯适配器(CGA),其利用可变形注意力来控制修剪和分割操作。经过CGA处理后,为精确重建,将更多高斯分配给几何复杂的区域,同时修剪视角间不必要的和重复的高斯以减少冗余并提高效率。由于这些高斯表示仍不足以充分捕获图像细节,我们进一步引入了基于Transformer的迭代高斯精炼器(IGR),通过直接图像-高斯交互来精炼3D高斯。最后,我们使用基于精炼高斯的光栅化渲染,在目标视角生成新颖视角。
3. 效果展示
大多数现有的可推广的3D高斯分布方法(例如,pixelSplat,MVSplat)为每个像素分配固定数量的高斯分布,导致在捕捉局部几何形状和跨视图重叠时效率低下。不同的是,我们的PixelGaussian在前馈框架中基于几何复杂度动态调整高斯分布。以相当的效率,PixelGaussian(使用2个视图训练)成功地推广到具有自适应高斯密度的各种数量的输入视图。

ACID和RealEstate10K基准测试的可视化结果。基于像素的方法由于次优的高斯分布而遭受高斯重叠,而像素高斯方法实现了动态高斯适应和改进的局部几何细化。

4. 主要贡献
我们在ACID和RealEstate10K基准数据集上进行了大规模3D场景重建和新颖视角合成的广泛实验。PixelGaussian在不同输入视角上表现优于现有方法,且推理速度相当。值得注意的是,现有的可泛化的3D高斯溅射方法(pixelSplat和MVSplat)在转移到更多输入视角时无法取得良好结果,而我们的方法展示了稳定的性能。这是因为现有的逐像素方法生成均匀且与像素对齐的高斯预测,而我们的模型根据局部几何复杂度动态调整其分布,从而减轻视角间的高斯重叠和冗余。可视化和消融实验进一步证明,CGA和IGR模块在适应高斯分布方面至关重要,使提出的PixelGaussian能够捕获几何细节并实现更高的重建精度。
5. 方法
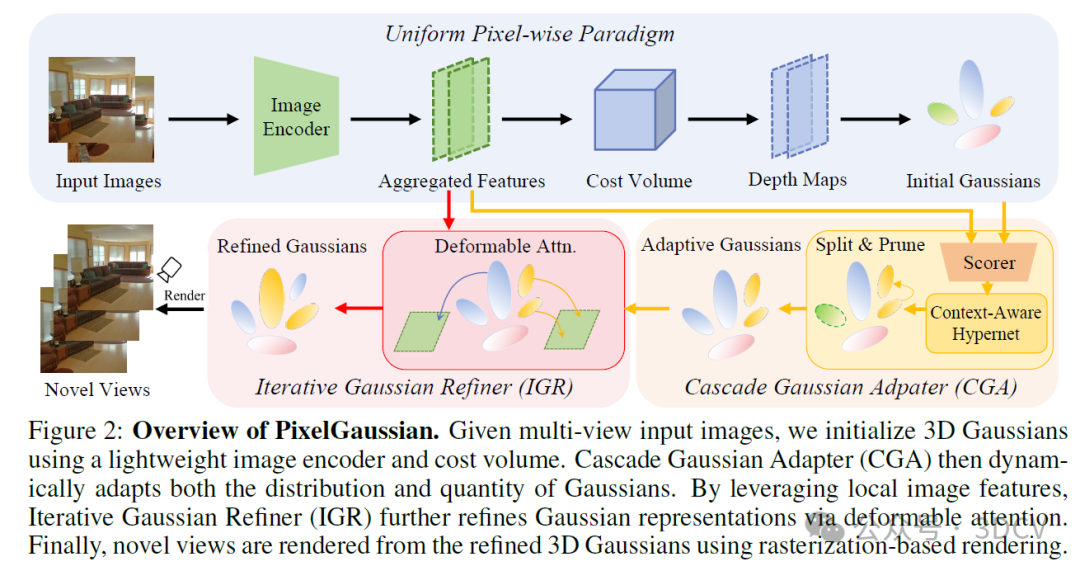
如图2所示,我们首先使用轻量级代价体积进行深度估计和高斯位置初始化。然后,我们引入级联高斯适配器(CGA),其根据局部几何复杂度动态适应高斯分布和数量。最后,我们解释了迭代高斯精炼器(IGR)如何通过直接图像-高斯交互,进一步精炼高斯分布和表示,从而增强重建效果。
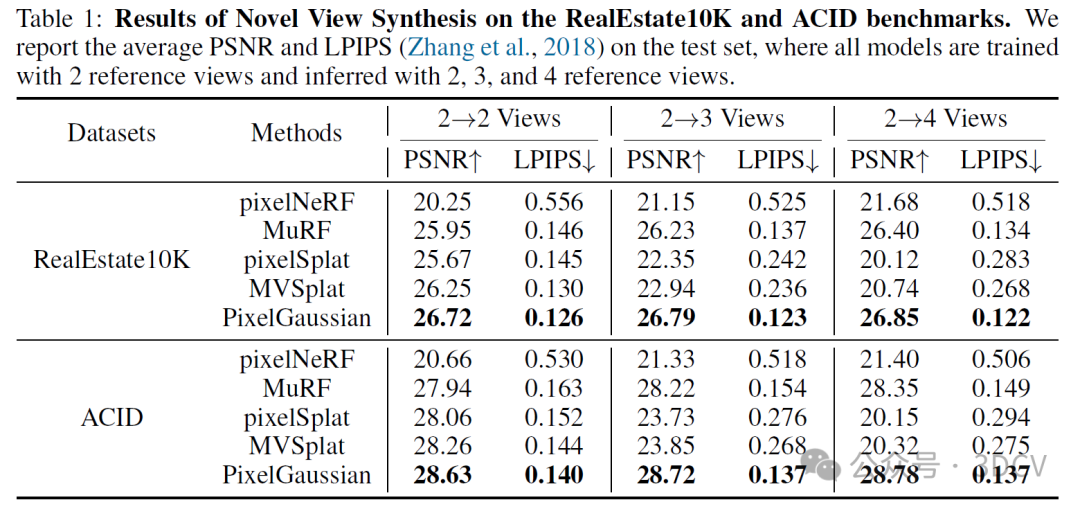
6. 实验结果
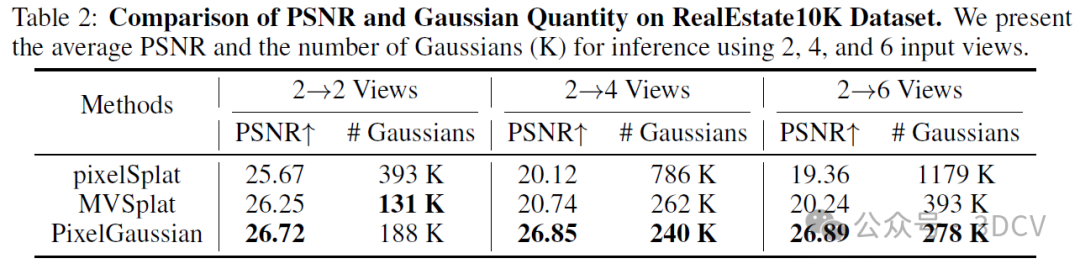
7. 总结 & 未来工作
在本文中,我们提出了PixelGaussian方法,旨在从任意输入视角学习可泛化的三维高斯重建。我们方法的核心创新在于上下文感知的级联高斯适配器(Context-aware Cascade Gaussian Adapter,CGA),该适配器能够动态地将具有复杂几何细节区域的高斯分布进行拆分,并剔除冗余部分。此外,我们在迭代高斯细化器(Iterative Gaussian Refiner,IGR)中融入了可变形注意力机制,促进了图像与高斯分布之间的直接交互,从而提升了局部几何结构的重建质量。
与以往均匀的逐像素方法相比,PixelGaussian能够根据局部几何细节的复杂度动态调整高斯分布及其数量,将更多资源分配给细节丰富的区域,并减少不同视角间的冗余,从而在重建和视图合成方面表现出更优异的性能。
讨论与局限性。尽管PixelGaussian能够动态调整三维高斯分布,但初始高斯分布仍然来源于逐像素的反投影。当我们完全随机初始化高斯中心时,模型无法收敛。此外,当高斯数量极大时,IGR中的可变形注意力机制会消耗大量计算资源,这凸显了需要一种更高效的方法,以使用更少的高斯分布来表示三维场景。此外,PixelGaussian无法感知输入视角之外的三维场景的未见部分,这表明可能需要结合生成模型来满足这一潜在需求。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。


















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









