







参考文献:
3.4. softmax回归 — 动手学深度学习 2.0.0 documentation (d2l.ai)
一、Softmax模型概论以及输出类别性质:
1. Softmax模型概论:
对于一般的回归模型,可以得到预测的数量,比如房价预测。但是在生活中同样存在大量分类问题,输出值O具有独特的性质。
2.Softmax输出值的编码方式以及性质:
输出值通常代表了某一个类别,比如猫狗鸡识别实验。为了使得输出值的编码方式与自然顺序无关,采用了一种名为独热编码的形式(one-hot encoding),对于猫狗鸡我们可以分别表示为(0,0,1),(0,1,0),(1,0,0)。
3.Softmax网络架构:
为了估计所有的条件概率,我们需要一个多输出的函数,每个类别对于一个输出。我们假设存在4个特征()和3个输出(
),由于每个输入的图像都具备4个特征,所以网络架构为一个全连接层,假设每个输出的函数数值需要调整,可以在输出的仿射函数上加上偏置(
)。

4.Softmax运算:
在猫狗鸡分类的问题中,三种动物的图像存在诸多特征,我们可以通过设置最大特征的阈值来识别最大概率的特征。假设对某一个输入的图像,存在三个输出的概率的数值分别为0.1,0.8,0.1,则我们预测的类别为2,结论为这个图像为鸡。
但是我们在不存在条件限制的条件下输出上述的理想化概率值,理想化概率值应该保证概率的基本公理,使得①概率的值加起来为1并且②输出的概率值不能为负值。
为了保证Softmax分类函数概率值为1和非负以及便于求导的性质,对输出的概率归一化并且指数化。由于输出的类别和未规划的预测之间一一对应,故可以将输出的类别概率值分配给未规划的输出,虽然Softmax是一个非线性函数,但是输入输出的过程由仿射变化决定。
输出的概率为 ,归一化概率
。
5.小批量样本的矢量化:
为了提高计算效率并且充分使用GPU,将输入的图片转化为维度d批量大小n的数组X,X∈。存在q个输出的类别,权重为W ∈
,偏置为b∈
。
Softmax回归矢量计算表达式为
转化为数组提高计算能力可以理解为100个小学生做加减题和1个小学生做加减题。
6.损失函数:
我们尝试使用损失函数来评估模型和真实值的结果差异,评估的过程采用最大似然估计。最大似然估计的定义为输入任意样本x输出为类y的条件概率。对于矢量化的数据集{X,Y}具有n个样本,索引i个样本由特征向量和独热向量
组成,我们可以将估计值与实际值相比较:
根据最大似然估计,我们最大化,相当于最小化负对数似然:
对于任何标签和模型预测
存在q个输出类别,故整个模型的损失函数为:
在后续的教程中会讲到,上述通常被称为交叉熵损失(cross-entropy loss),由于预测值值始终小于零,他们的对数永远不会大于零。但往往会因为输入特征没有足够的信息来完美地对每一个样本分类。
7.softmax导数以及导数所表示的意义:
将归一化预测值公式代入上式
得到
,对该公式进行分解优化得
。
再对上式进行求导,可以得到,导数得到的结果是softmax分配模型和实际情况之间的差异。导数和回归方程中的梯度相似,在回归方程中梯度是观测值与估计值
之间的差异。
8.熵的定义:
信息论的核心思想是量化数据中的信息内容。在信息论中,该数值被称为分布的熵(entropy),可以通过以下方程得到
。信息论的基本定理指出,为了对从分布
中随机抽取的数据进行编码,我们至少需要以纳特(nat)的数据形式进行编码。
二、从Fashion_MNIST数据集学习Softmax的从零回归:
1.数据集来源:
2. 载入各类数据库:
Python库的架构常识(以matplotlib库为例)以及导入方式(import或from ..import...)-CSDN博客
使用import语句导入数据库,使用”from....import...“导入数据库的模块,使用”import...as..“对导入的数据简写。
注意这里的"d2l.use_svg_display()",指定matplotlib软件包输出svg图标以获得更清晰的图像,使用'.use_svg_d2l将matplotlib包中的这个功能调入d2l包'。
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display() 3.数据集的读取:
使用torchvision中的内置函数将Fashion_MNIST数据集读取并存储在内存中,并使用ToTensor将图像数据由PIL类型变为32位浮点数格式,并除以255使得所有像素的数值均在0~1之间。
FashionMNIST数据集一般条件下下载比较慢,建议科学上网,我会把数据集下载好后放入本文的附录中供大家下载,大家只需要从csdn下载好后放入相对路径"../data"中。
在此处选用了torchvision.datasets中FashionMNIST参数,root=‘../data’表示FashionMNIST数据集下载的位置,train = True/False表示下载的数据集是否用于训练,download = True表示相对路径没有则需要下载。
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root='../data', train= True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root='../data', train=False, transform=trans, download=True)3.数据集下载验证:
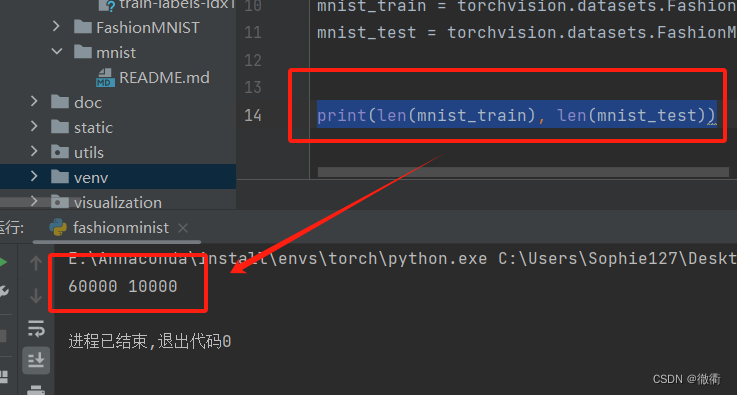
对于上述下载并且转化为向量的数据集,我们采用len(),来验证下载图片的数量。注意,如果拟选用的是jupyter笔记本可以直接输入如下代码来验证下载情况,如果采用Vscode或者Pycharm等IDE需要print函数:
#在jupyter笔记本中
len(mnist_test, mnist_train)
#在IDE中
print(len(mnist_train), len(mnist_test))出现输出的数值代表下载的图片数量,下载成功!
4.训练集图像处理以及图像类别的建立:
类和方法的定义方式:python——class类和方法的用法详解_python class-CSDN博客
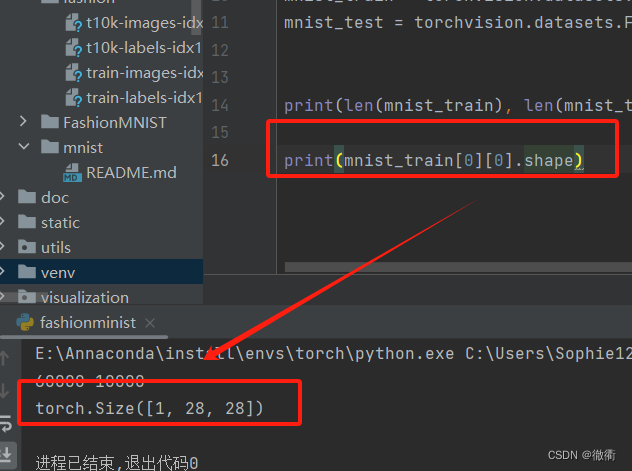
每个输入的图像均为单通道的灰度图像,输入图像的高度和宽度均为28个像素,长度为一个像素,使用print语句输出数据集图像的格式。
print(mnist_train[0][0].shape)可以得到输入图像的输出格式如下:
Fashion_MNIST一共有10个类别,分别为t-shirt,trouser,pullover,dress,coat,sandal,shirt,
sneaker, bag, ankle boot, 我们定义了一个父类labels,由子类get_fashion_mnist_labels来继承父类labels,创建一个方法。定义的方法get_fashion_mnist_labels承担返回Fashion_MNIST数据集文本标签的作用。
再创建一个元组,输入各个类别的名称,最后返回一个for循环在数字循环和文本名称之间转换。
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt','trouser', 'pullover', 'dress',
'coat', 'sandl', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)]for i in labels]5.自行创建一个函数来可视化这些样本(Python函数定义基础):
5.1在python中函数的定义:
函数是组织好的,可重复使用的,用来实现单一,或相关功能的代码块。
5.2在python中定义函数的格式:
参考文献:Python教程——def()函数_python中def函数的用法-CSDN博客
①函数代码块以def关键词开头,后接函数标识符名称和圆括号,在圆括号内可以定义传入的参数以及自变量。②函数的第一行语句一般选择性地使用文档字符串存放函数说明,函数内容以冒号起始并且缩进。③return[表达式]结束函数,选择性地返回一个值给调用方。如果不带return,代表返回为bool型的None。
5.3有参函数以及无参函数的定义方法以及实参与形参的定义:
无参函数指的是直接用def定义一个函数并且函数名后面的括号不带有任何的参数或者数组,而有参函数需要在括号内传入参数,参与后续的函数功能。
形参指的是赋值关系中的'key',需要完成‘相加’这个功能。而实参指的是赋值关系中的'value',是具体的数值相加,在hello(10,10)中调用数值10完成实际相加。
#无参实例,输出为'这里是一个def定义的函数块'
def hello():
print('这里是一个def定义的函数块')
hello()
#有参实例,向函数中传入两个参数执行”相加“功能
def hello(num1,num2):
result = num1+num2
print(result)
hello(10,10)5.4 多个参数传入函数的方式:
在知道要传入几个参数,但不想在括号内传入参数可以采用仍以传递实参。定义形式为def 函数名 (*元组名称)。对于含有数量较多的参数的函数时,可以定义函数创建一个空元组,或者在此之前定义好的元组。将参数传入函数创建的这个空元组内并且实现封装。
def get_result(*function):
return function #设置返回值
result = get_result('one', 'two', 'three') #将参数分装在函数function内
print(result) #返回结果为 one two three6.自行创建一个函数来可视化这些样本(Fashion-MNIST案例讲解):
参考文献:子图,生成子图(Spanning Subgraph),导出子图(Induced Subgraph)的定义-CSDN博客
【Python】详解 enumerate + zip 函数_enumerate(zip-CSDN博客
python在使用matplotlib隐藏坐标轴时遇到的问题_plt.axes().get_xaxis().set_visible(false)-CSDN博客
6.1函数定义的逐行解读:
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes①首先定义函数名称以及传入的参数名称,定义函数名称为show_images以及传入参数imgs,...,scale=1.5。
②使用figsize赋值形成一个形参的函数式,将图像扩大为原先的1.5倍大小。
③调用plt包的subplots函数,实现输出窗口的设置。_,axes = d2l.plt.subplots(num_rows, num_cols, figsize=figesize)中的num_rows表示的是子图的行数,num_cols表示的是子图的列数,figsize=figsize表示子图的宽度和高度保持不变;”,axes“之前的"_"采用了省略,省略了绘图窗口的大小fig,'axis'表示的是坐标系。
④axes.flatten()表示将子图展开赋值给axes,axes[0]表示了调整后的数据集的第一个子图。
⑤采用枚举函数enumerate和拉链函数zip联用实现对图片命名:枚举函数通过调用__next__方法在每次迭代之后返回一个tuple,内含一个计数值和可迭代对象的值。拉链函数zip创建了一个迭代器iterator,打包/聚合来自各个输入可迭代对象iterable中的元素,zip返回一个元组迭代器iterator,其中的第i个元素tuple包含哥哥输入可迭代对象iterable的第i个元素。
#枚举函数enumerate的使用方法,作为一个迭代器遍历后返回一串tuple
x = ['a', 'b', 'c', 'd', 'e']
for i in enumerate(x):
print(i)
#使用枚举函数enumerate返回的结果
(0, 'a')
(1, 'b')
(2, 'c')
(3, 'd')
(4, 'e')
#拉链函数zip的使用方法,起到一个”打包“的作用,将多个列表的元素打包形成一串元组。
lst1 = [1, 2, 3, 4, 5]
lst2 = ['a', 'b', 'c', 'd', 'e']
for tup in zip(lst1, lst2)
print(tup)
(1, 'a')
(2, 'b')
(3, 'c')
(4, 'd')
(5, 'e')对于上述代码块中的for i, (ax, img) in enumerate(zip(axes, imgs)),首先利用拉链函数zip对两个元组进行打包,然后采用enumerate迭代器对先前打包好的元组进行编码。
⑥通过torch.is_tensor(obj)来检查打包好的元组中的img是否是一个张量。如果是则返回True并且执行语句ax.imshow(numpy())把数据类型为tensor的数据转化为ndarray型数据,并且将调用imshow()函数对图像进行展示。如果不是返回False,直接调用imshow()对图像进行展示。
⑦使用plt.axes().get_xaxis().set_visible(False)以及plt.axes().get_yaxis().set_visible(False)将两边的坐标轴进行隐藏。
⑧使用if titles: ax.set_title(titles[i])对图片使用之前打包好的元组进行命名。
6.2使用print输出命名好的图片集:
参考文献:Python迭代器基本方法iter()及其魔法方法__iter__()原理详解-CSDN博客
python一个窗口中显示多张图像(matplotlib.pyplot)_pyplot显示图片两行七列-CSDN博客
我们可以看到,使用Dataloder以batch_size为组加载的数据集,并使用python迭代器的基本方法iter(),next() 进行读取并展示。
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
print(show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y)))迭代器是一个可以记住遍历位置的对象,设置python迭代方法可以先创建一个迭代器对象对元组中的元素进行迭代,也可以使用自定义迭代器创建类中的某个方法实现迭代。
iter(obj[,sentinel])调用自定义函数的对象self,返回自定义对象self。next(iterator[,default])调用函数next(), 返回自定义对象x。
使用自定义类作为迭代器时,def后iter(函数名)两侧加的'__'为类的声明,说明该类的属性为私有,括号内的self表示自身的参数。通过myclass = MyNumbers()将上述定义的迭代器函数赋予给myclass这个变量,使用iter(myclass)对myiter返回一个迭代器对象,然后再使用next()函数对myiter这个迭代器对象执行+=1的函数功能,得到输出值1,2,3,4。
#创建迭代器对象进行迭代
a =[1, 2, 3]
it = iter(a)
print(next(it))
print(next(it))
print(next(it))
#输出
1
2
3
#自定义类作为迭代器
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
self.a += 1
return self
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
#输出
1
2
3
4对于模型中的代码,由data.DataLoader创建一个可迭代对象,调用iter()函数实现对DataLoader载入的数据集进行遍历,再调用next()函数给每个batch_size的图片进行排序。
调用matplotlib包的函数show_images,show_images可以再一个窗口中绘制多张图像,将图片先转化为长为18,宽高为28的(三维)一组图片,再转换为2行9列的格式,分别命名为ankle boot,....,t-shirt。
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
print(show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y)))输出的图表:

7.创建小批量数据:
参考文献:Datasets & DataLoaders — PyTorch Tutorials 2.2.0+cu121 documentation
【PyTorch】torch.utils.data.DataLoader 简单介绍与使用-CSDN博客
How to use the d2l.base.Timer function in d2l | Snyk
for in遍历对象时break,continue,return尝试_for in break-CSDN博客
7.1使用torch.untils模块来创建小批量数据:
为了可以在读取训练集和测试集的时候更加容易,我们使用内置的数据迭代器。在每次数据迭代中,数据加载器每次都会读取一小批数据,大小为batch_size。通过内置数据迭代器,我们可以随机打乱所有样本,从而无偏见地读取小批量数据。
读取数据的data.DataLoader来自模块torch.utils,mnist_train为分批次对象的存储地址,batch_size为小批量中的样本个数。shuffle为bool型参数,shuffle = True的时候对样本进行随机打乱。num_workers使用多线程进行,在创建小批量数据之前,我们采用了def get_dataloder_workers()创建了一个返回值为4的无参函数,我们采用线程为4来创建数据。
batch_size = 256
def get_dataloder_workers():
"""使用4个进程来读取数据"""
return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())7.2使用d2l包中的Timer函数来查看训练数据所需时间:
使用for..in..遍历对象时,可以采用break、continue、return让遍历停止。 使用continue停止当前语句,并从头执行该语句。
timer = d2l.Timer()
for X, y in train_iter:
continue
f'{timer. Stop():.2f} sec'三、对于图像分类数据集的整合(功能整合):
在”二、从Fashion_MNIST数据集学习Softmax的从零回归“我们学习了数据集处理的流程,并定义了两个在数据集处理中所用到的函数"get_fashion_mnist_labels"和"show_images",现在使用函数定义的嵌套来实现上述”二、从Fashion_MNIST数据集学习Softmax的从零回归“中所有函数的功能。
1.函数赋值给变量加"[]":
数据增强(Data Augmentation)常用方法汇总-CSDN博客
通过给赋值带变量的函数加“[]”,实现一个列表存放数据增强的方法,现在trans是一个由图片转化的包含一系列数字的列表。
2.Python中List的insert方法:
Python中List的insert方法_python list insert-CSDN博客
Resize — Torchvision main documentation (pytorch.org)
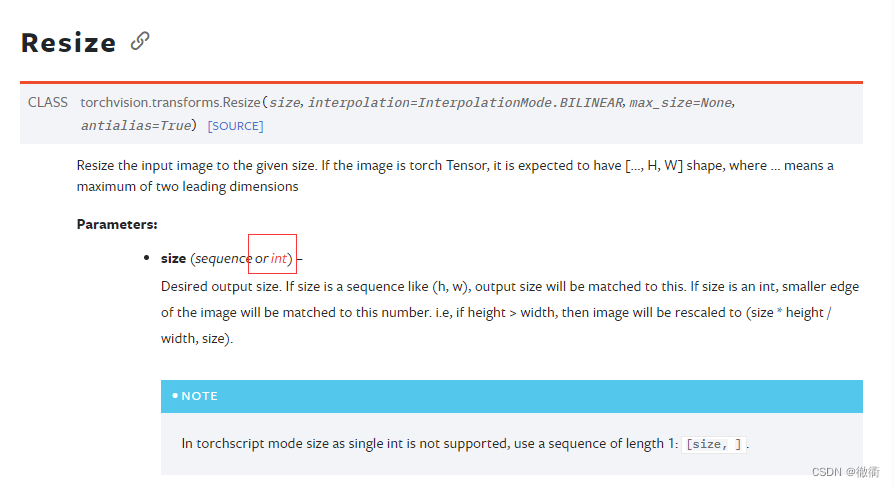
python中list.insert(index, obj)用于指定对象插入列表的指定位置,index为索引的位置而obj为需要插入的对象,例如list=[2,4,7,3],list.insert(2,5),需要在第三位上插入对象5。代码中嵌套了transforms包的子包Resize,子包Resize可以把输入的图像调整为指定大小,但是在写函数load_data_fashion_mnist时,子包参数size所引的resize = None,则在上述trans转化的数列前加一个空,即"[ , .., .., ...]"。
3.Pytorch中的transforms.Compose():
transforms.Compose()类,主要用于串联多个图片变换的操作。可以从transforms.Compose的类说明中得知,类的参数是列表,这个类把参数组合起来。语句“trans = transforms.Compose(trans)”用于之前图片转化后的列表组合。
class torchvision.transforms.Compose(transforms):
# Composes several transforms together.
# Parameters: transforms (list of Transform objects) – list of transforms to compose.
Example # 可以看出Compose里面的参数实际上就是个列表,而这个列表里面的元素就是你想要执行的transform操作。
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),])4.Datasets和DataLoader之间的区别:
torch.utils.data.Dataset是代表这一数据的抽象类(类),我们可以通过继承和重写这两个抽象类实现自己的数据集,只需要定义__len__和__getitrm__这两个函数。
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset)+采样器(sampler),并在数据集上提供单线程或多线程的可迭代对象。在DataLoader中具有obj,batch_size,shuffle等参数,以乱序的形式存储。
在如下代码中首先使用torchvision包中的datasets类下载FashionMNIST数据集的测试集和训练集,再通过torchvision.dat.DataLoader类返回一个存储好的数据集(由于未输入参数,此时返回的数据集为未设置batch_size和resize的列表)。
再调用load_data_fashion_mnist函数对train_iter和test_iter进行赋值,设置batch_size为32,resize为64,此时返回一个每批次元素为32个,返回的每个数组之前需要加一个“64”的元素。
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
def get_dataloader_workers():
"""使用4个进程来读取数据"""
return 4
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion_MNIST数据集,然后加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root='../data', train=True,
transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False,
transfroms=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break再通过指定resize参数来测试load_data_fashion_mnist函数的图像大小来调整功能。
四、Softmax回归模型的构建方法:
1.数据库的导入以及批次的设置&初始化模型参数:
注明:此处为Softmax回归模型构建的.py文件,如果想要和上述二、,三、图像预处理的文件写在同一个.py文件,只需要添加之前未添加的包Ipython以及小包display。
原始的数据集中的图像已经被处理为28*28,通过ToTensor()展开后形成一个长度为784的向量(你要不算算28*28是多少),把每个像素位置作为一个特征。由于 我们的数据集有10个类别,所以网络输出维度为10。
import torch
from Ipython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)由本文“一、Softmax模型概论以及输出类别性质:5.小批量的矢量化”中的内容可知,我们的输出和类别一样多。因此我们的数据集一共有10哥类别,构成784*10个权重矩阵,偏置将构成一个1*10的行向量。我们设置输入的列表长度为784,输出的类别为10。
和先前的线性回归方程的构建一样,使用正态分布初始化我们的权重w,偏置初始化为0。
num_inputs = 784
num_outputs = 10
w = torch. Normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)2.torch.sum()函数的应用以及Softmax表达式的构建:
2.1torch.sum()函数的应用:
首先,我们回顾一下torch.sum()函数中参数的设置以及作用,torch.sum(input, dim, keepdim=False, dtype=None)可以对输入的张量进行特定维度的求和,参数imput为张量(也可以使用X.sum()无需在参数中输入张量)。参数keepdim为bool型参数,如果keepdim=True,则按照keepdim这个参数之前的dim对给定的张量进行加合,如果keepdim=False,则对列表中的全部元素进行加合。
代码示例:
X = torch. Tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
print(X.sum(0, keepdim=True), X.sum(1, keepdim=True))
#输出dim=0对行相加,dim=1对列相加
tensor([[5., 7., 9.]])
tensor([[6.0],
[15.]])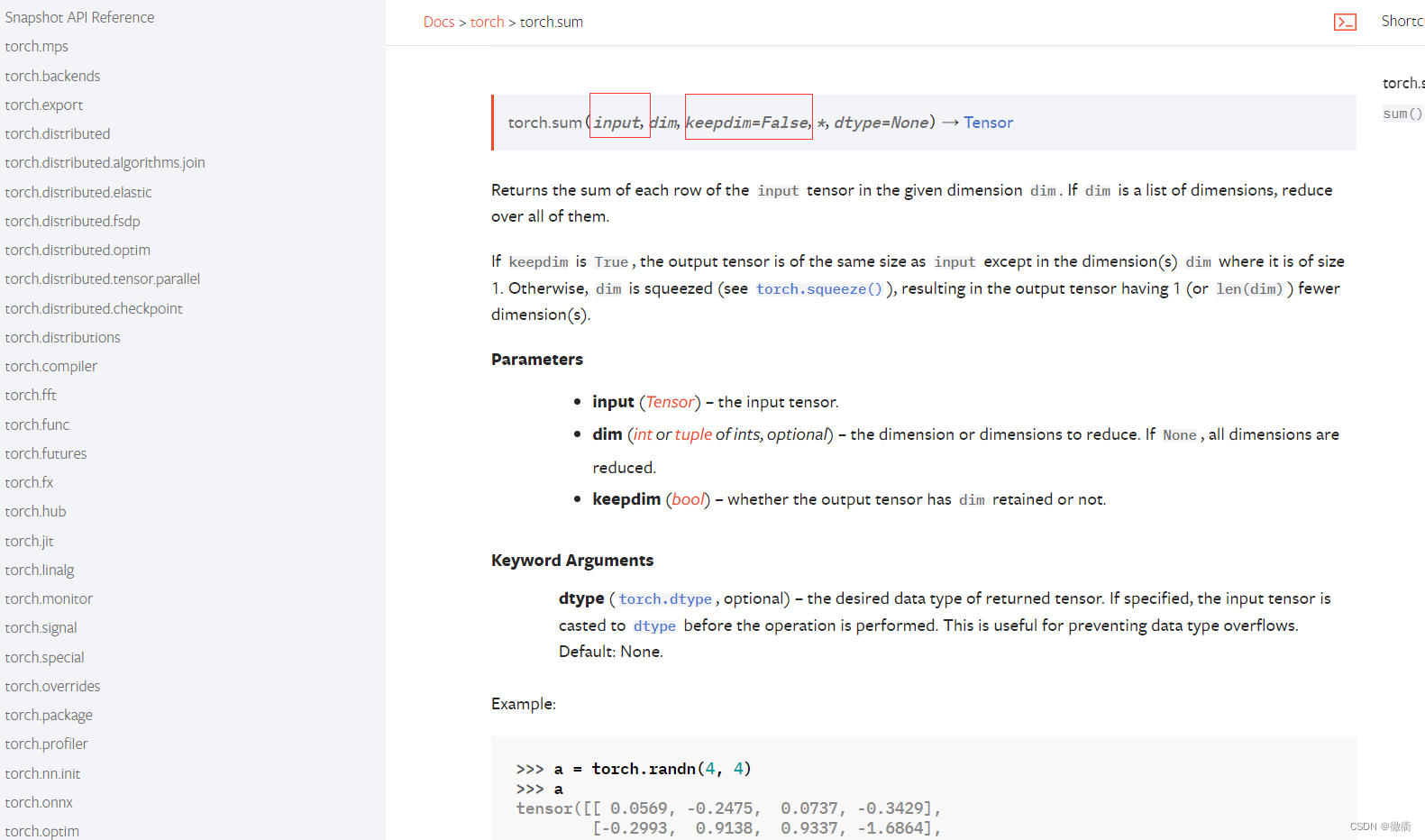 2.2 Softmax函数的构建:
2.2 Softmax函数的构建:
①首先需要对每一项求幂(使用exp)。②再对每一行使用tensor.sum()函数求和,得到每个样本的规范化常数。③最后将每一行初一其规范化常数,确保结果的和为1。
让我们自己定义这个函数吧!幂函数设定可以使用torch.exp()求幂,使用X_exp.sum对列进行求和,最终使用return返回这个函数。
def softmax():
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp/partition由于存在10个输出类别,我们设定一个2行5列的矩阵为输出的矩阵,使用torch.normal(0, 1, (2,5)
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(x)
print(X_probe, X_probe.sum(1))
#输出
tensor([[0.2062, 0.2050, 0.1084, 0.2236, 0.2568],
[0.0920, 0.1169, 0.1715, 0.5259, 0.0937]]) tensor([1.0000, 1.0000])3.定义softmax回归模型:
参考文献:python reshape函数参数-1(X.reshape(X.shape[0], -1).T)-CSDN博客
在定义softmax操作后,我们可以实现softmax回归模型。下面定义的函数net()定义了如何通过网络映射到输出,将数据传递到模型之前,我们使用reshape函数将每张原始图像展开为向量。这里我们采用的是numpy.reshape(a, newshape, order='C')。其中a为操作的对象,newshape是展开的向量形式。

再让我们学习一下python中variant.shape[]的作用,使用variant.shape[0]可以读取第一维度(行的个数)。
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)4.定义Softmax的损失函数:
在Softmax模型中,我们引入交叉熵损失函数,交叉熵采用真实标签的预测概率的负对数似然,通过一个运算符选择所有的元素。下面我们创建一个数据样本y_hat,其中包含2个样本在3个类别中的预测概率,以及他们对应的标签y。我们使用y作为y_hat中概率的索引,我们选择第一个样本中第一类的概率和第二个样本中第三个类的概率。在第一个样本中第一类是正确的预测,在第二个样本中第三类是正确预测。
y = torch.tensor([0, 2])
y_hat = torch. Tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y_hat[[0, 1], y]此时y_hat索引嵌套了两个列表,首先索引了第一行和第二行,在分别索引第一行第一个以及第二行第三个,输出为tensor([0.1000, 0.5000])。
定义交叉熵损失的时候,采用len()求出y_hat的长度。range(start, stop[, step]),由于只包含了len(y_hat)的长度,所以采用range()函数的时候可以创建一个由0到2的整数列表,即[0, 1, 2]。得到整数列表后我们再次采用上述y_hat[]索引张量中元素的方法,对y_hat中第一行、第二行、第三行(由于不存在第三行,return隐式返回为None)的第一个和第三个张量进行索引,得到张量tensor([0.1000, 0.5000])。
torch.log是以e为底的对数函数,定义cross_entropy函数得到输出预测的负对数,也就是交叉熵损失。
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)5.定义分类精度:
参考文献:python中的[1:]、[::-1]、X[:,m:n]和X[1,:]_1:python-CSDN博客
对于给定的概率分布y_hat,当我们必须输出硬预测时候,我们通常选择预测概率最高的类。对于邮件Gmail,必须把收到的邮件分为“Primary, Social, Updat, Forums”,Gmail只能把收到的邮件分到其中一类。
当预测与标签分类y一致的时候,即是正确的。分类精度是正确预测数量与总预测数量之比。虽然直接优化精度可能很困难(因为精度的计算不可导),但精度仍然是一个值得关注的衡量标准。
我们定义一个名为“精度”的accuracy函数,含有两个参数y_hat和y,在这个函数中我们需要完成三个功能:使用argmax对每行概率最大的预测类别进行索引、将预测类别和真实类别进行比较(返回一个包含0(错),1(对)的张量),return回一个正确预测的数量。
此处我们承接了上文中的y_hat,上文中y_hat是一个(2,3)的矩阵,列表中共存在6个元素,故len(y_hat.shape)=6。首先我们关注第一行的if句,len(y_hat.shape)>1说明至少存在一个输入项和一个预测类别,y_hat.shape[1]为输入列表的第一项,只有两个条件都满足的时候才能进入下面的函数。
argmax(a, axis, out)是numpy包中的一个函数,用于在列表(array)中的每一行(axis=1)查找最大的概率。
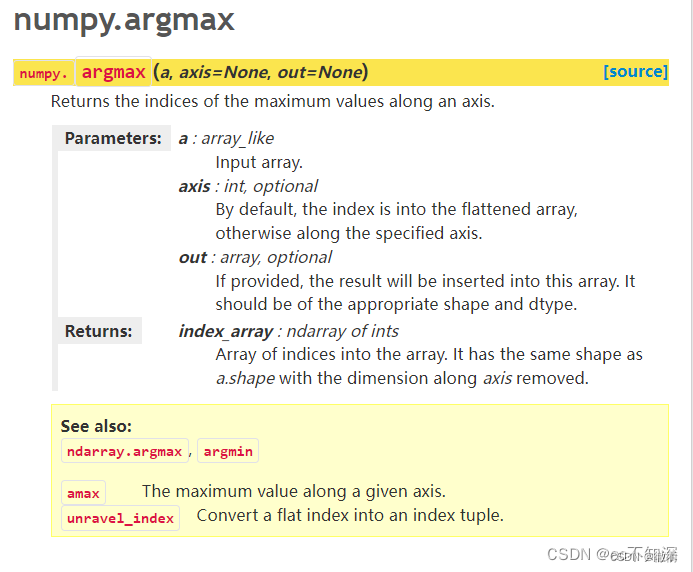
再看第三句cmp = y_hat.type(y.detype) ,.detype()是Numpy包中的一个函数,用于描述变量的数据类型(describe type)。然后再使用numpy包中的type()函数,将y_hat的数据类型转化为y的数据类型。最后将y_type赋值给y。
def accuracy(y_hat, y):
"计算预测正确的数量"
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.detype) == y
return float(cmp.type(y.dtpe).sum())最后return返回y_hat.type总和的浮点型形式。以之前定义的变量y_hat和y分别作为预测的概率分布和标签。 可以看到,第一个样本的预测类别是2(该行的最大元素为0.6,索引为2),这与实际标签0不一致。 第二个样本的预测类别是2(该行的最大元素为0.5,索引为2),这与实际标签2一致。 因此,这两个样本的分类精度率为0.5。
使用print函数对精度进行输出:
print(accuracy(y_hat, y) / len(y)6.定义evaluate_accuracy函数,计算在指定数据集的精度:
参考文献: pytorch教程之nn.Module类详解——使用Module类来自定义模型-CSDN博客
Pytorch的net.train 和 net.eval的使用_net.train()-CSDN博客
【pytorch系列】 with torch.no_grad():用法详解_with torch.no_grad()放在哪里-CSDN博客
首先让我们确定一下这个函数的功能,这个函数用于计算指定数据集上的模型精度。定义了两个参数net和data_iter,其中net具有评估模式的属性net.eval()。
if后更了一个python的isinstance()函数,用于判断一个对象是否是一个已知的类型,假设2是int型,输入语句print(isinstance(2, int)),如果2的数据类型是int,则返回True。torch.nn.module是pytorch中定义神经网络的一个类,如果参数net也是pytorch创建的神经网络,那么执行下面的语句,如果不是隐式返回False。
在训练神经网络的过程中,训练模型net的时候通常会加上net.eval()用于测试训练的模型,
metric变量用于存储由Accumulator创建的两个变量,实现通过遍历后存储正确预测的数量和预测的总数量。
在python中with语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后的自动关闭。在pytorch中tensor存在一个require_grad参数,用于反向传播时的自动求导,如果采用with torch.no_grad()函数,反向传播的时候不会自动求导,大大节约了内存。
在"for X, y in data_iter"语句中通过对预测结果遍历实现对正确预测数量和预测总数量的统计并传给函数Accumulator(),y.numel()用.numel()函数查看预测标签的数量,再通过accuracy()函数实现对输入张量X在net网络内精度的预测,最后再使用.add()函数对错误数值和正确数值的比值(metric[0] / metric[1])。
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]7.定义Accumulator函数,实现对每个批次的结果累加:
李沐的深度学习Accumulator怎么理解_python accumulator-CSDN博客
Python中*args 和 **kwargs的用法总结 - 知乎 (zhihu.com)
Python 中的 __getitem__() 方法解析_getitem函数-CSDN博客
①首先让我们确定一下函数的功能,这个函数主要用于对上面创建的变量的累计加和,在上述accuracy()函数中我们使用了y_hat和y两个变量用于存储正确预测的数量和预测的总数量。
②此处使用def __init__(self, n),定义了class类的参数slef和另外定义的一个参数n。创建一个self.data的属性,使用一个包含浮点型数的列表对self.data进行赋值,列表中元素和实例中的变量数量相等。假如n = 2,则self.data = [0.0, 0.0]。
③arg是Argument的缩写,*arg用于函数定义,可以将不定数量的参数传递给另一个参数。这里的不定指的是预先不知道函数使用者会传递多少个参数给你。*args是用来发送一个非键值对的可变数量的参数列表给一个函数。通过下例来理解*arg传递参数的方式。我们可以看到输出了一个名为yasoob的key和三个python,eggs,test的value。
在"self.data = [a + float(b) for a, b in zip(self.data, args)]"这句命令中,我们首先使用zip函数将输入的args和self.data列表进行缝合,再通过遍历的方式在zip缝合的列表中找到int型的a和float型的b,最后将找到的a,b重新排列key和value赋值给self的属性data。
刚才说到,self.data是[0.0, 0.0],倘若args接收的传参为(4, 5),那么for a, b in zip(self.data, args) 表示 a = 0.0,b = 4,然后执行a + float(b),得到结果4.0,此时self.data = [4.0, 0.0],然后同样再来一次for循环,a = 0.0, b = 5,然后执行a + float(b) 得到结果5.0,最后self.data = [4.0, 5.0]。
def test_var_args(f__arg, *args):
print("first normal arg:", f__arg)
for arg in args:
print("another arg through *arg:", arg)
test_var_args('yasoob', 'python', 'eggs', 'test')
#输出的结果:
first normal arg: yasoob
another arg through *argv: python
another arg through *argv: eggs
another arg through *argv : test
④定义reset函数的时候,使用self.data的长度称以[0.0]并赋值给self.data。
⑤ __getitem__()函数返回所给键对应的值。当对象是序列时,键是整数。当对象是映射(字典时),键是任意值。在定义类时,如果希望计算机通过key寻找value,则需要定义__getitem__方法。如果给类定义了__getitem__()函数的时候,则应当按照key寻找value的时候,可以直接返回__getitem的结果。
通过“def __getitem__(self, idx):”可以将每个批次结果在硬盘中的所在位置返回给类test。
class test():
def __init__(self):
self.a = 100
#定义 __getitem__(),key为test的键
def __getitem__(self, key):
b = self.a + key
return b
t = test()
t[100]
#输出值为200
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]8.定义对样本训练的函数:
首先,我们定义一个函数来训练一个迭代周期。在这个函数中一共有三个参数net,train_iter, loss, updater。updater时更新模型参数的常用函数,可以使用批量大小作为参数。同时updater可以是d2l.sgd函数,作为框架内的优化函数。
如果updater是torch自带的更新器,需要先清空之前的梯度,并且计算损失函数的反向传播。如果自己实现则损失函数的结果是个向量,进行反向传播更新并且记录预测正确返回的个数。最后通过return函数记录预测正确的个数。
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]下来我们实现一个训练函数,它会在train_iter访问到的训练数据集上训练一个模型net,由于之前函数对样本的epoch进行了设置,训练函数会运行多个迭代周期。在每个周期结束后,使用 test_acc函数预测每个epoch的准确度。然后调用绘图函数绘制训练误差,训练精度,测试误差,测试精度。
最后使用assert函数用于程序的调试,首先定义训练集训练后的误差,如果训练后的误差小于0.5,则返回值为True,程序继续训练。其次对训练集和测试集的准确度进行了要求,如果精确度小于0.7则发生asserterror发生报错。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc我们从零开始实现,使用小批量随机梯度下降来优化模型的损失函数,设置学习率为0.1。设置10个训练epoch,使用我们之前定义好的函数train_ch3进行训练,得到最终结果。
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
9.预测模型的输出:
在这里我们定义了一个函数predict_ch3,包括net,test_iter和n,对训练集和预测集的数值使用遍历进行索引,并采用d2l.get_fashion_mnist_labels()函数将之前索引的预测值在图片上侧进行输出。
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)














 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









