





在当今数据驱动的世界中,Excel 仍然是企业的基石,其电子表格中包含着宝贵的见解。然而,从这些庞大的数据集中提取有意义的信息可能非常耗时,并且需要专业技能。这就是检索增强生成 (RAG) 发挥作用的地方。
RAG 是一种功能强大的方法,它将大型语言模型 (LLM) 的优势与信息检索的效率相结合。通过结合这些技术,RAG 使机器能够访问和处理来自各种来源(包括 Excel)的信息,并生成人类质量的文本格式。
本博客将引导您了解专为 Excel 数据量身定制的 RAG 系统。我们将利用 LlamaIndex 和 LlamaParse 的强大功能将您的电子表格转换为可搜索的知识库。我们将使用 LlamaParse 从 Excel 文件中提取数据并将其高效地存储在 Qdrant 中以便快速搜索。
骆驼指数
LlamaIndex 是一个数据框架,用于弥合自定义数据源与 Llama 3 等 LLM 之间的差距。它允许用户从各种来源(例如矢量数据库或文件)提取数据,然后将这些数据索引到中间表示中。然后,用户可以用自然语言查询他们的数据,并使用聊天界面与其交互。
LlamaIndex 的工作原理是在索引阶段首先将数据索引到向量索引中,从而创建特定于域的可搜索知识库。在查询阶段,系统根据用户的查询搜索相关信息,然后将这些信息提供给 LLM 以生成准确的响应。您可以在此处了解有关 LlamaIndex 的更多信息。
LlamaParse
LlamaParse 是一个功能强大的文档解析平台,旨在与 LLM 无缝协作。它旨在解析和清理数据,确保为 RAG 等下游 LLM 应用程序提供高质量的输入。LlamaParse 支持解析 PDF、Excel、HTML、XML 和许多其他常见文档格式。您可以在此处了解有关 LlamaParse 的更多信息。
Qdrant
Qdrant 是一个开源向量数据库和向量搜索引擎,提供快速且可扩展的向量相似性搜索服务。它旨在处理高维向量,以实现高性能和大规模 AI 应用程序。您可以在此处了解有关 Qdrant 向量数据库的更多信息。
Groq
Groq 是一家 AI 解决方案公司,以其尖端技术而闻名,尤其是语言处理单元 (LPU) 推理引擎,旨在通过超低延迟推理功能增强大型语言模型 (LLM)。Groq API 使开发人员能够将最先进的 LLM(如 Llama3 和 Mixtral)集成到应用程序中。在我们的 RAG 管道中,我们将使用它llama3-70b-8192作为 LLM 模型。
使用 Excel 数据构建 RAG
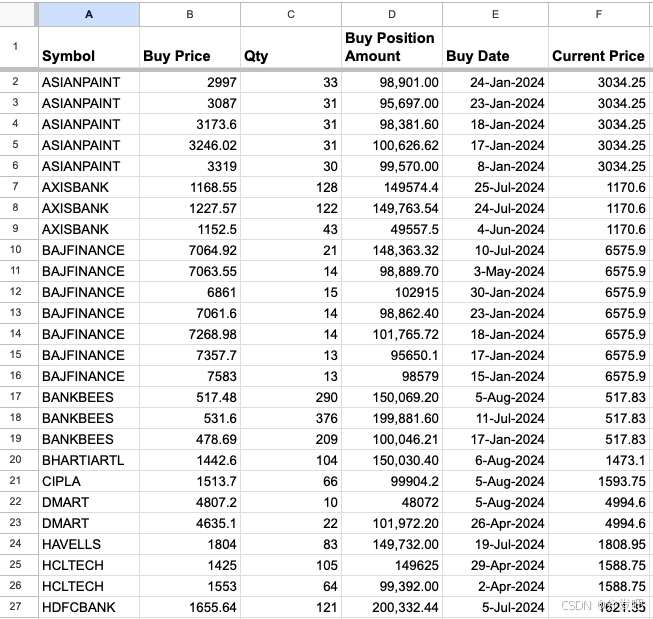
我们将利用股票交易数据集构建检索增强生成 (RAG) 系统。基础数据存储在 Excel 电子表格中,包含以股票代码、收购价格、数量和购买日期为特征的未平仓交易头寸。RAG 系统将有助于提取关键指标,例如按股票划分的头寸数量、价格分布和总持股量。
下面提供了 Excel 数据集的直观表示。
安装依赖项
www.cqzlsb.com
我们将首先安装所需的依赖项。复制复制
!pip install llama-index llama-parse qdrant_client llama-index-vector-stores-qdrant llama-index-llms-groq fastembed llama-index-embeddings-fastembed
llama-index是 LlamaIndex 的核心库。llama-parse用于解析Excel文件的库。qdrant_client和llama-index-vector-stores-qdrant是用于在 Qdrant DB 上执行插入和获取操作的两个依赖项。llama-index-llms-groq用于连接到 Groq 接口。fastembed并llama-index-embeddings-fastembed需要生成嵌入。
接下来,我们将创建 LlamaParser 的实例。复制复制
from llama_parse import LlamaParse
from google.colab import userdata
from llama_index.core import SimpleDirectoryReader
import nest_asyncio
nest_asyncio.apply()
parser = LlamaParse(
api_key=userdata.get('LLAMA_CLOUD_API_KEY'),
parsing_instruction = """You are parsing the open positions from a stock trading book. The column Symbol contains the company name.
Please extract Symbol, Buy Price, Qty and Buy Date information from the columns.""",
result_type="markdown"
)
实例化 LlamaParse 对象时,我们传递了:parsing_instruction和result_type作为解析选项。
在 中,result_type我们指定了输出格式。默认情况下,LlamaParse 将以解析后的文本形式返回结果。其他可用选项包括 markdown(将输出格式化为干净的 Markdown)和 JSON(返回表示解析后对象的数据结构)。在 中,parsing_instruction我们可以为 LlamaParse 提供更多有关其正在解析的数据的上下文。LlamaParse 可以在后台使用 LLM,使我们能够为其提供关于其正在解析的内容和如何解析的自然语言指令。
现在让我们加载 Excel 文件并使用 LlamaParser 对其进行解析。复制复制
file_extractor = {".xlsx": parser}
documents = SimpleDirectoryReader(input_files=['my_report.xlsx'], file_extractor=file_extractor).load_data()
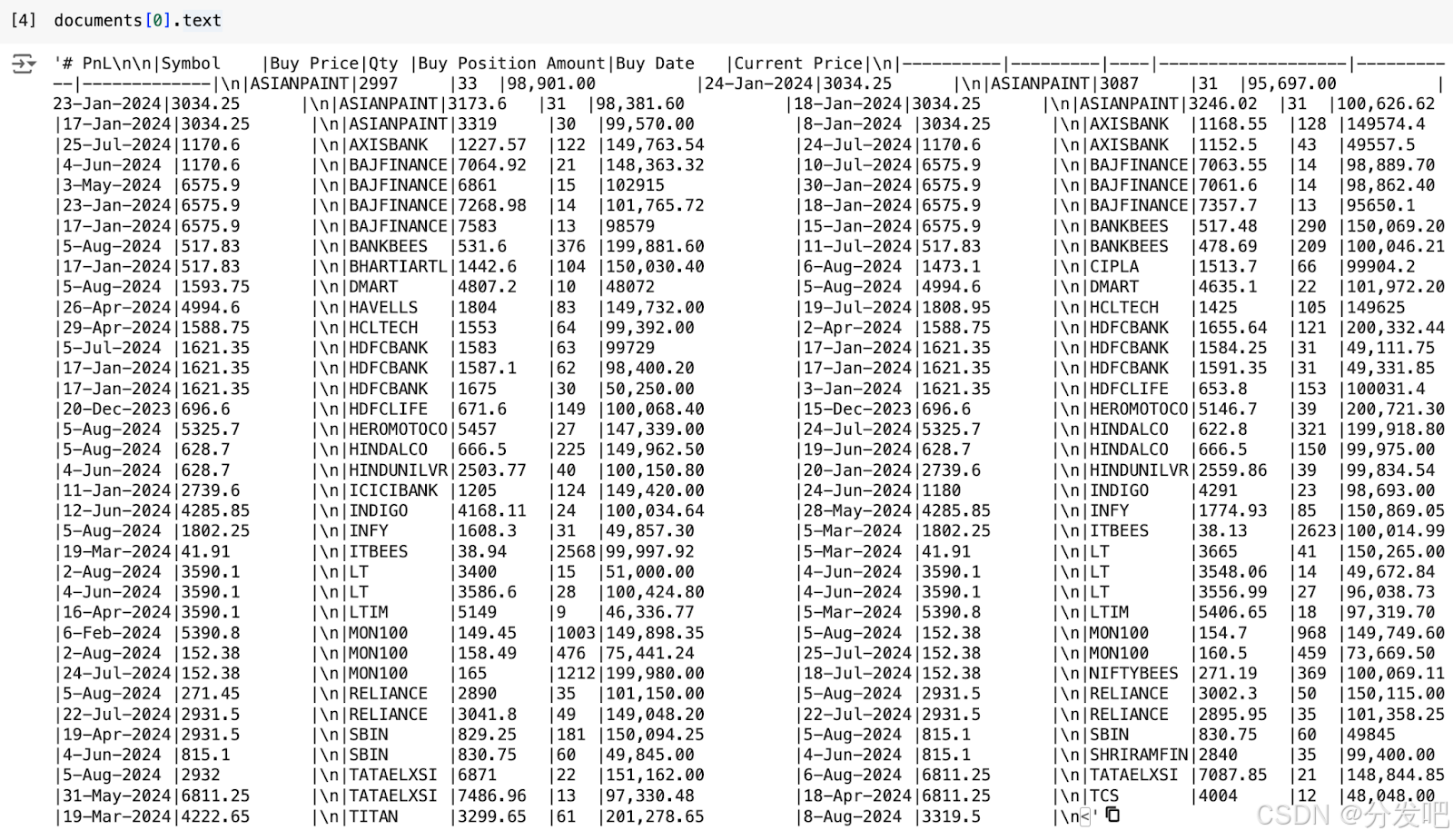
由于我们已将 result_type 值作为 markdown 传递,因此我们获得了 markdown 格式的解析输出。以下是解析后的输出。
在 Qdrant 中存储 Excel 数据
解析后的 Excel 数据现在存储在变量中documents。我们的下一个目标是用这些信息填充 Qdrant 数据库。为此,我们将文档转换为 VectorStoreIndex。此索引随后将存储在向量数据库中。此过程的底层 LLM 模型是llama3-70b,通过 GROQ API 进行交互。为了生成嵌入,我们选择了模型bge-small-en-v1.5。复制复制
from llama_index.llms.groq import Groq
from llama_index.core import Settings
from llama_index.embeddings.fastembed import FastEmbedEmbedding
from google.colab import userdata
llm = Groq(model="llama3-70b-8192", api_key=userdata.get('GROQ_API_KEY'))
Settings.llm = llm
embed_model = FastEmbedEmbedding(model_name="BAAI/bge-small-en-v1.5")
Settings.embed_model = embed_model
要建立与 Qdrant 数据库的连接,需要一个 Qdrant 客户端实例。我们将继续创建此实例。复制复制
from qdrant_client import QdrantClient
from google.colab import userdata
QDRANT_URL = userdata.get('QDRANT_URL')
QDRANT_API_KEY = userdata.get("QDRANT_API_KEY")
qdrantClient = QdrantClient(
url=QDRANT_URL,
prefer_grpc=True,
api_key=QDRANT_API_KEY)
现在我们将调用 VectorStoreIndex 方法将索引存储在 Qdrant DB 中。VectorStoreIndex 获取文档并将其拆分为节点。然后,它会创建每个节点文本的向量嵌入,以供 LLM 查询。
LlamaIndex 分块策略
当我们使用时VectorStoreIndex.from_documents,文档被分成块并解析为 Node 对象,这些对象是文本字符串的轻量级抽象,用于跟踪元数据和关系。
Node 解析器负责接收文档列表,并将它们分块为 Node 对象,这样每个节点都是父文档的特定块。当文档被分解为节点时,其所有属性都会被子节点继承(即元数据、文本和元数据模板等)。
由于我们的文档是 Markdown,因此将使用 MarkdownNodeParser 来解析原始 Markdown 文本。
LlamaIndex 提供各种基于文件的节点解析器,旨在根据正在处理的特定内容类型(例如 JSON、Markdown 和其他格式)生成节点。
您可以在此处阅读有关 LlamaIndex 节点解析器的更多信息。复制复制
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
from llama_index.core.indices.vector_store.base import VectorStoreIndex
vector_store = QdrantVectorStore(client=qdrantClient, collection_name="stock_trade_data")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Create vector store index and store it in Qdrant DB
VectorStoreIndex.from_documents(documents, storage_context=storage_context)
检索和响应生成
成功填充矢量数据库后,后续阶段涉及从该存储中检索信息以响应用户查询。首先,将嵌入加载到 VectorStoreIndex 中。在此基础上,构建查询引擎。该引擎充当中介,将用户查询转换为可搜索的格式,并返回从矢量化数据中得出的综合响应。复制复制
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core import StorageContext
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.core.indices import load_index_from_storage
vector_store = QdrantVectorStore(client=qdrantClient, collection_name="stock_trade_data")
db_index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# create a query engine for the index
query_engine = db_index.as_query_engine()
def get_response(query):
response = query_engine.query(query)
return response.response
结果
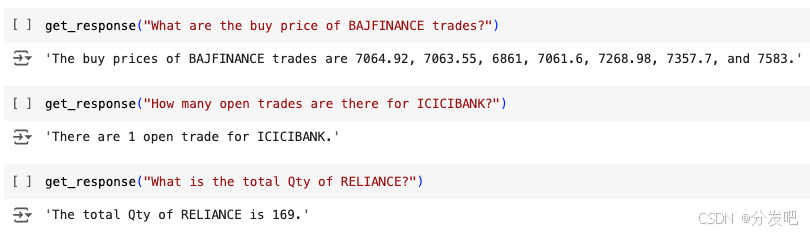
现在,我们将通过检查 RAG 管道对各种股票相关查询的响应来评估其性能。以下示例展示了系统从数据集中准确提取和提供信息的能力。
结论
本博客概述了构建以 Excel 数据为中心的检索增强生成 (RAG) 管道的方法。我们演示了使用 LlamaParse 从 Excel 电子表格中提取信息、将其转换为 VectorStoreIndex 格式,然后将此索引存储在 Qdrant 数据库中的过程。这些步骤的最终结果是功能齐全的 RAG 管道,能够根据存储的 Excel 数据为用户查询提供信息丰富的响应。如果您对此主题有任何疑问,请随时在评论部分提问。我非常乐意为您解答。您可以在此Google Colab 页面上找到此项目的源代码。
我经常撰写有关构建 LLM 应用程序、AI 代理、矢量数据库和其他 RAG 相关主题的内容。如果您对类似的文章感兴趣,请考虑订阅我的博客。

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









