







目录
前言
学习每部分内容其实都有它的意义所在,所以学习时候需要对自我进行灵魂拷问。
为什么需要辨识?什么叫辨识?辨识有什么用?
个人简单理解:从控制角度,由于实际应用中,被控对象的具体模型是未知的,或者说尽可知其名义模型,这往往对控制带来巨大挑战,可能导致系统控制效果不理想,甚至发散不稳定,但是输入输出的数据一般是可以知道的,这就可以利用输入输出的数据来反推被控对象数学模型,这便是系统辨识的初衷。随着系统辨识的广泛,辨识不仅仅局限于模型辨识,还可以延伸到参数辨识,如控制器参数等等。
而辨识的本质可以理解为利用已知的输入输出数据进行“反推”,这项工作目前有很多方法能做,如:最小二乘法,网络训练,甚至kalman等等,这些均可以理解为辨识。
本篇文章来较为渐显的介绍一下最小二乘辨识,起初的最小二乘辨识是批处理最小二乘;但是由于每次都需要进行批处理,数据量较大占用空间,于是后面有了递推最小二乘(RLS),即仅利用前一时刻的信息预测下一步;后面由于递推最小二乘针对慢时变参数会导致估计失败,所以便又提出了带遗忘因子的最小二乘(FFRLS),还有一些分支,这里不一一叙述。但是步骤上都是先选取性能指标,然后对性能指标函数求导证明提出参数估计准则公式,本质上即利用输入输出信息进行参数估计。
所以本质上可以分为两种辨识:
(1)采集输入输出数据进行辨识
(2)利用上一刻的实时数据递推进行预测辨识
注:
值得说明的是,由于实际过程中系统几乎都是离散的,虽然我们喜欢利用连续系统进行仿真,如常见利用simulink模块搭建模型,但是由于连续系统拟合出来的模型不唯一或者较差,所以更多地对离散系统模型进行辨识,如若需要连续系统,则通过连续化过程即可,d2c()。
1. 最小二乘法理论简介
前面已经介绍离散系统辨识更精确,所以假定离散系统传递函数为:
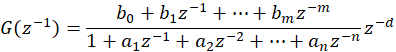
注:这里定义分子阶次为m,有的书上会定义成m-1,易误导。
对应的差分方程为:
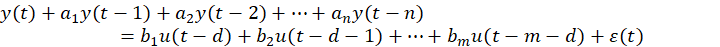
值得注意的是这种模型便可以称为ARX模型。
展开,即:
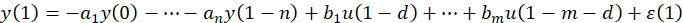
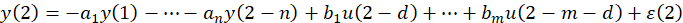


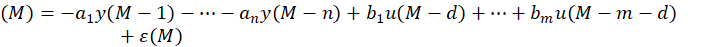
进一步,将其表述为矩阵形式:

其中,
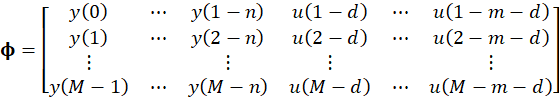
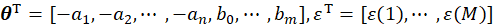
ε即为辨识的误差,所以辨识的目标就是最小化ε,所以定义如下的性能指标:
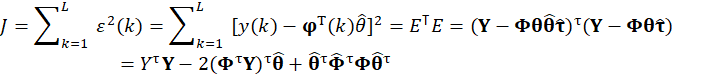
求导求极值:
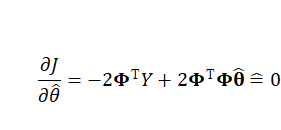
得到系统最小二乘估计值θ^:
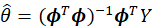
2.利用采集好的数据进行辨识
本篇文章用的是最小二乘法理论进行辨识,所以这里利用采集好的数据进行辨识,咱可称辨识方法为最小二乘辨识。
这里首先介绍两个概念:
①自回归历遍模型(ARX):输出信号呈周期,即按周期对模型输出进行采样得到的数据集。如果是这样的已知数据,可以通过matlab的arx([y,u],[m,n,d])函数直接辨识得出模型,其中y即为输出数据集,u为输入数据集,m=分子阶次+1,n为分母阶次,d为延时时间或者说纯滞后。
②伪随机二进制序列(PRBS):又称M序列,该信号可以利用matlab的idinput(k,'prbs')函数生成,其中k=(2^n)-1。
为了节省时间,此处就不利用采集数据进行辨识,而是利用M序列产生输入信号,随后利用lsim()函数仿真得到输出数据,后续与原模型进行对比,查看辨识模型,并且在假设模型阶次已知情形下。可以给出结论,采用PRBS作为辨识输入信号的辨识精度会更高,这也是为何要提出M序列概念的原由。
实例分析:
假设已知如下的模型,分别利用PRBS信号和正弦信号作为辨识输入信号,最后对比辨识的结果
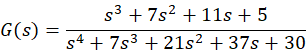
2.1 利用PRBS信号作为辨识输入信号仿真分析
%% 利用PRBS信号作为辨识输入信号(准确)
G=tf([1,7,11,5],[1,7,21,37,30]);%原模型
t=[0:0.1:3]';%采样时间为0.1s,需要转置因为PRBS是列信号,
u=idinput(31,'prbs');%产生PRBS信号,这里定为31是因为输入时间长度为31
y=lsim(G,u,t);%计算系统输出信号
n=4;%分母阶数
m=3;%分子阶数
U=arx([y,u],[m+1,n,1]);%辨识离散系统模型
G1=tf(U);%辨识离散系统传递函数
G1.Ts=0.1;%采样时间,要对应上t向量的采样时间
G2=d2c(G1)%连续化模型G2 =
From input "u1" to output "y1":
s^3 + 7 s^2 + 11 s + 5
--------------------------------
s^4 + 7 s^3 + 21 s^2 + 37 s + 30
Continuous-time transfer function.
2.2利用正弦信号作为辨识输入信号仿真分析
G=tf([1,7,11,5],[1,7,21,37,30]);%原模型
t=[0:0.1:3]';%采样时间为0.1s,需要转置因为PRBS是列信号,
u=sin(t);%产生PRBS信号,这里定为31是因为输入时间长度为31
y=lsim(G,u,t);%计算系统输出信号
n=4;%分母阶数
m=3;%分子阶数
U=arx([y,u],[m+1,n,1]);%辨识离散系统模型
G1=tf(U);%辨识离散系统传递函数
G1.Ts=0.1;%采样时间,要对应上t向量的采样时间
G2=d2c(G1)%连续化模型G2 =
From input "u1" to output "y1":
0.01706 s^3 - 0.08085 s^2 + 9.901 s - 2.577
-------------------------------------------
s^4 + 7 s^3 + 21 s^2 + 37 s + 30
Continuous-time transfer function.
2.3利用批处理最小二乘进行辨识
%% 利用批处理最小二乘进行辨识
G=tf([1,7,11,5],[1,7,21,37,30]);%原模型
t=[0:0.1:3]';%采样时间为0.1s,需要转置因为PRBS是列信号,
u=idinput(31,'prbs');%产生PRBS信号,这里定为31是因为输入时间长度为31
y=lsim(G,u,t);%计算系统输出信号
n=4;%分母阶数
m=3;%分子阶数
d=1;
M=length(y);%M=end
Phi=[[0;y(1:M-1)] [0;0;y(1:M-2)],[0;0;0;y(1:M-3)] [0;0;0;0;y(1:M-n)],...%n列y,默认y(-1)=0,所以补0,同理y(-2)=0、y(-3)=0....
[0;u(1:M-d)] [0;0;u(1:M-d-1)],[0;0;0;u(1:M-d-2)] [0;0;0;0;u(1:M-m-d)]];%m
T=Phi\y;%忽略辨识误差ε
T=T';%转置成行向量
G1=tf(ans(n+1:n+m+1),[1,-ans(1:n)],'Ts',0.1);%离散模型
G2=d2c(G1)%连续化模型G2 =
s^3 + 7 s^2 + 11 s + 5
--------------------------------
s^4 + 7 s^3 + 21 s^2 + 37 s + 30
Continuous-time transfer function.
2.4总结
①可以看到利用PRBS信号作为输入信号辨识准确
②本篇文章由于篇幅原因没有介绍采集数据的辨识,读者有信号,只需将arx中的y和u替换为已有的采集信号即可。
③此外可以利用matlab自带的系统辨识工具箱
④可以,如果有输入输出信号,但是不知道阶次,可以用AIC准则进行选择,此处省略不做详细介绍。其定义为:
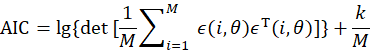
3.利用递推最小二乘法进行辨识
当遗忘因子λ=1时,带遗忘因子的递推最小二乘法即普通的递推最小二乘法,所以这里直接给出带遗忘因子的递推最小二乘法表达式:
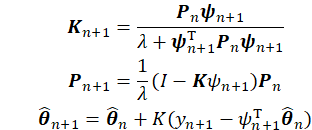
注:
①其实这种递推思想和kalman类似,K可以理解为递推增益,同样其与估计值、真实值以及K的前后时刻值无关,所以它可以先前离线计算;
②一般遗忘因子λ≥0.9,如果是线性系统则≥0.95,也有文献称λ自回归系数;
③数据向量:
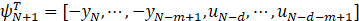
④P=αI,α=1e4~1e10
⑤θ(0),即辨识参数的初值选为零向量或充分小的正实向量。
3.1 simulink案例仿真
现在其实更多的现成代码都是m语言,不利用做控制,所以作者根据原理编写s函数,其实网上也有部分博主写过,确实真的每个人写的风格都不一样,但是我觉得程序应该在产生同样效果上更为简洁的才是好程序,好了都是一些基本功,下面通过案例测试作者构建的程序和模型。
网上有看到博文说对于激励信息u不能选随机噪声模块?理论上,激励信息不是随便给么?给定激励得到输出,如果是离线的那就可以通过批处理最小二乘,如果不是,那就实时的递推最小二乘。
下面通过一个简单例子进行分析,由于辨识模型通常为离散模型,此外,为了方便使用,对模块进行了封装,其实编写方法也很基础,参考我这边文章的思路,有三种方法。但是网络普遍存在的是将θN和P都当成状态,也有道理,因为二者都是实时更新的,但是没必要,这样维度做起来挺复杂,状态变量个数为:(r+m+1)*(r+m+1)+(r+m+1),前者为P方阵元素个数,后者为θN个数。还有一种方法是借助线性kalman编程思路:只将辨识参数作为状态变量,这样状态个数就变成r+m+1,即辨识的参数个数。我都做了一下,结果都一致,但是第一种编写要复杂一些。
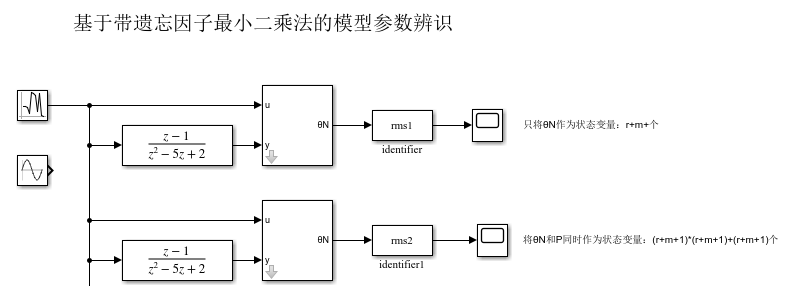
3.1.1 只将θN作为状态变量
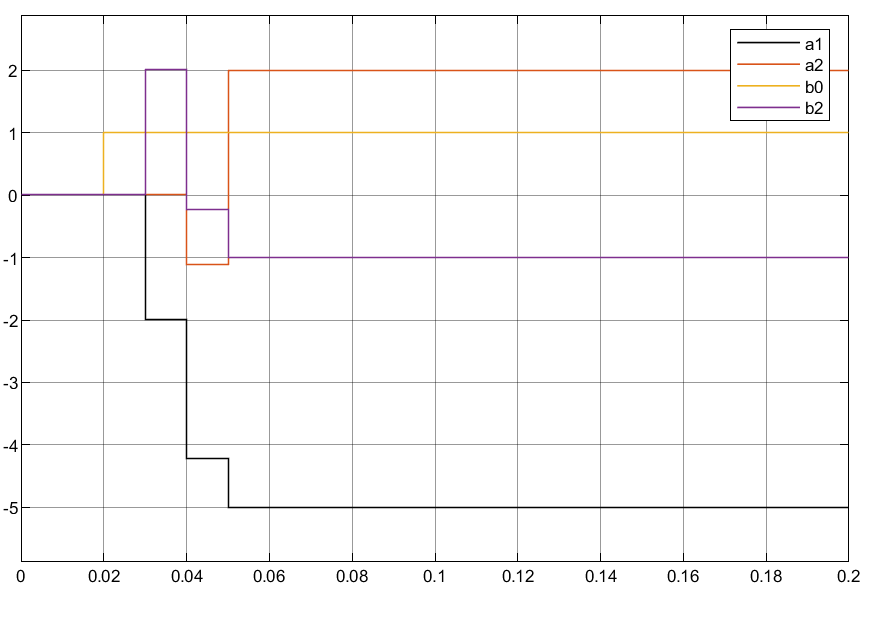
3.1.2 同时将θN和P作为状态变量
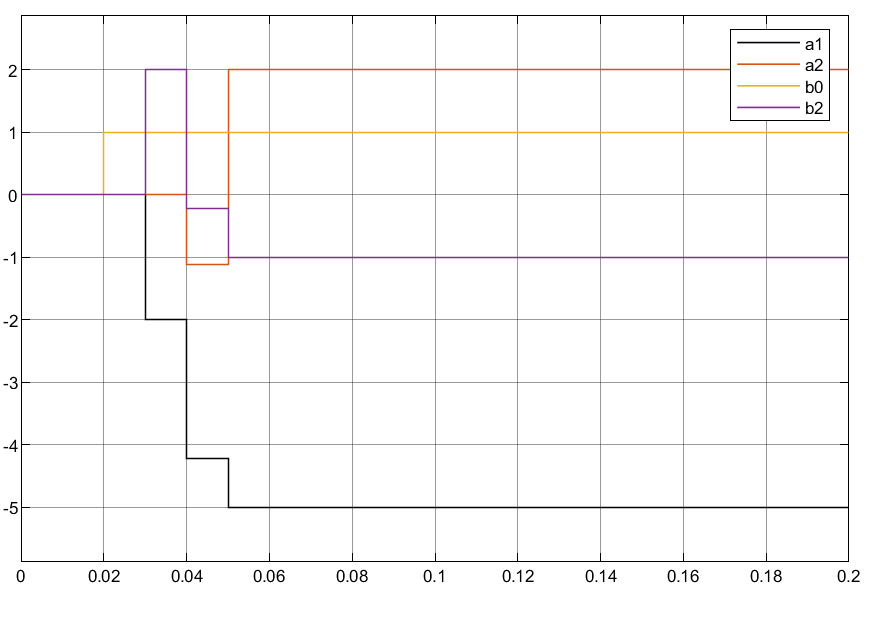
3.1.3 仿真小结
①可以看到两种编写方法结果均一致,且辨识速度和准确度较高;
②此外,读者可以借助我《几种神经网络整定PID参数原理剖析及simulink案例仿真》这篇文章用几种方法尝试编写。
几种神经网络整定PID参数原理剖析及simulink案例仿真_Mr. 邹的博客-CSDN博客
4 学习问题
①尝试连续系统的模型辨识;
②连续模型阶次的转换;
③并非所有模型都能辨识?



















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











