







The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
(ManyDepth)
写在前面: 翻译软件翻译,后续可能慢慢优化
目 录
摘要
在训练过程中使用邻近帧作为监督信号来预测场景深度从而训练自监督的单目深度估计网络。然而,对于许多应用程序,视频帧形式的序列信息在测试时也是可用的。绝大多数的单目网络没有利用这些额外的信号,因此忽略了可以用来提高预测深度的有价值的信息。那些这样做的人要么使用计算成本高昂的测试时间细化技术,要么使用现成的循环网络,它们只是间接地利用了固有的几何信息。我们提出了 ManyDepth,这是一种自适应的密集深度估计方法,可以在测试时利用序列信息(如果可用)。从多视角立体视觉中获得灵感,我们提出了一种基于深度端到端代价量的方法,该方法只使用自监督进行训练。我们提出了一种新颖的一致性损失,鼓励网络在被认为不可靠时忽略代价量,例如在移动物体的情况下,并提出了一种应对静态摄像机的增强方案。我们在KITTI和cityscape上的详细实验表明,我们优于所有发布的自监督基线,包括那些在测试时使用单个或多个帧的基线。
1 引言
了解图像中每个像素的深度已经被证明是一种有用且通用的工具,其应用范围从增强现实[59]、自动驾驶[22]到3D重建[64]。虽然专业硬件可以提供逐像素的深度,例如通过结构光或激光雷达传感器,但更有吸引力的方法是只需要一个RGB相机。最近许多来自RGB方法的单目深度只使用自监督进行训练,这就不需要昂贵的硬件来捕获训练深度数据[21,99,23,26]。虽然这些方法看起来很有前途,但它们的测试时深度估计性能还不能与专业深度硬件或深度多视图方法相提并论[73]。
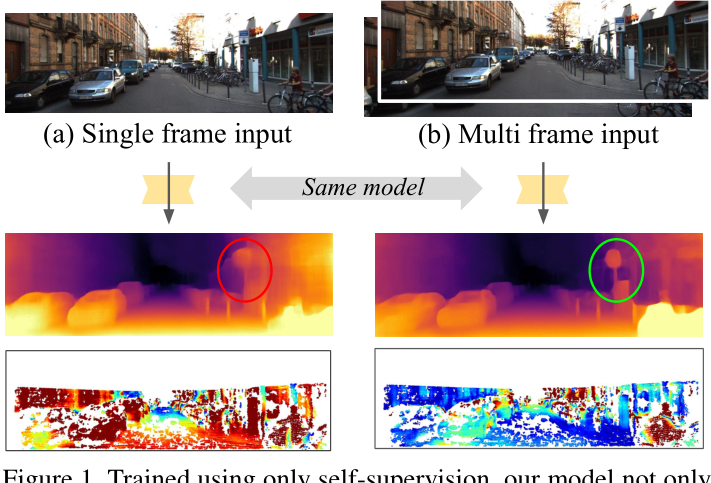
图 1. 仅使用自监督进行训练,我们的模型不仅可以从单帧预测深度 (a),而且还可以使用多个帧(如果可用),使用相同的模型 (b)。 这会在测试时产生出色的深度预测。 底行的误差图将大深度误差显示为红色,小为蓝色。
为了缩小这一性能差距,我们观察到,在大多数实际场景中,在测试时有不止一帧可用,例如来自移动车辆上的摄像头或手机摄像头的微基线帧[32,41]。然而,当前的单目方法通常不会利用这些额外的帧。在这项工作中,当这些额外的帧可用时,我们在训练和测试时间会使用他们,对多帧深度估计系统进行自监督。研究表明,将自监督训练直接应用于多视图平面扫描立体架构会产生较差的结果,明显比自监督单帧网络差。 为了克服这个问题,我们引入了一些创新来解决由移动物体、尺度模糊和静态相机引起的问题。 我们将生成的多帧系统称为 ManyDepth。
我们做了以下三点贡献:
- 一种新颖的自监督多帧深度估计模型,它结合了单目和多视图深度估计的优势,在测试时利用多帧(当它们可用时)。
- 研究表明,运动目标和静态场景对自监督多视点匹配算法有显著的影响,我们引入了有效的损失和训练方法来缓解这一问题。
- 我们提出了一种自适应代价量来克服单目序列自监督训练带来的尺度模糊问题。据我们所知,这是第一次从数据中了解代价量范围,而不是将其设置为参数。
我们的ManyDepth模型在KITTI和cityscape上优于现有的单帧和多帧方法
2 相关工作
2.1 单目深度估计
单目深度估计的目标是预测单个输入图像中每个像素的深度。监督方法要么利用深度传感器(如[15,14,20])的密集监督,要么利用人工注释(如[8])的稀疏监督。自监督方法消除了需要真实深度标签监督的限制,取而代之的是使用立体对[87,21,23]或单目视频序列[99]进行图像重建损失训练。
自监督训练的最新进展集中在解决仅从图像中学习所带来的各种挑战,例如 更稳健的图像重建损失 [26, 72],离散而不是连续的深度预测 [56, 25, 40],特征空间重建损失 [93, 72],稀疏自动生成的深度监督 [49, 83],遮挡处理 [26] ],改进的网络架构 [28],以及在训练 [69, 24, 26, 78, 92, 9, 3, 75, 48, 53] 和测试[54] 期间移动对象。 我们的底层单目架构基于 [24],并且同样可以从上述许多增强功能中受益。
2.2 多帧单目深度估计
有越来越多的工作扩展现有的自我监督单目模型,以便它们可以利用测试时的时间信息来提高预测深度的质量。值得注意的是,除了传统的基于SLAM的方法[65、63、16、89]和集成单目深度估计网络的SLAM方法[74、4、52]之外,还有几种非深度学习方法也旨在产生一致的顺序深度估计[96,44]。然而,这里我们关注的是最新的基于神经网络的深度估计。
测试时改进方法采用单目方法在测试时使用序列信息,例如[5,9,59,62,72,51]。由于自监督训练不需要任何真实深度标签监督,因此可以将训练时使用的相同损失应用到测试帧上,以更新网络的参数。缺点是,这需要对一组测试帧进行多次前向和反向模型传递的额外计算,每一次传递可能要花费几秒钟的时间[62,59],尽管额外的一次向后传递可能是有效且快速的[51]。
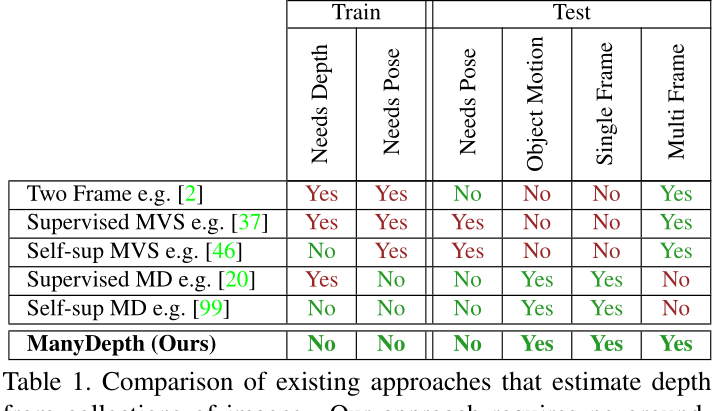
表 1. 从图像集合估计深度的现有方法的比较。 我们的方法不需要真实标签监督,并且对物体运动具有鲁棒性。 MVS 代表 Multi-View Stereo,MD 代表单目深度。
第二大类方法将传统的单目网络与循环层结合起来处理帧序列,例如[66,81,50,97]。一种相关的方法在测试时使用连续帧对,在姿态和深度模块[79]或计算流的深度[88]之间共享特征。这些方法比测试时的优化更有效,但在训练期间,由于需要从序列中的多个帧中提取特征,它们可能需要更多的计算量。这些方法的另一个局限性是,它们在推理过程中不显式地对几何进行推理;它们只是依赖于学习了如何提取有意义的时间表示的网络。
我们的实验表明,我们的方法在准确性方面通常优于测试时改进,同时在推理时保持循环方法的效率。
2.3 深度多视角深度估计
我们的多帧深度预测问题与多视角深度估计有关。早期的深度立体方法主要使用卷积层,利用真实标签监督从图像对映射到深度,例如[61,77,55],[45]表明,集成平面扫描立体视觉代价量显著提高了结果。最近的方法改进了底层架构,并贡献了更有效的方法来规范代价量[7,94,95,10]。也可以在没有真实标签监督的情况下训练立体网络[98,82,1,36],但这些模型通常被监督变量超越。一些研究将传统的基于匹配的立体估计与单目深度线索相融合[71,60,17]。相反,我们在训练或测试中不需要立体声对。
立体匹配问题的一个更普遍的版本是多视图立体(MVS),它对无序的图像集合进行操作。早期的深度MVS方法使用存储昂贵的3D网格表示法,例如[39,43]。目前的监督方法,如[37,80,91,38,57],利用代价量,但假设真实深度标签和相机姿态可用于训练。他们通常在测试时也需要相机姿态;这可以从最初的估计[84,56]得到改进。有些方法可以预测测试时的姿态,但仍然需要在监督下进行训练,例如[77]。
与我们的方法类似,[56,35]在测试时使用代价量处理帧序列。然而,通过使用真实深度标签监督和提供的相机姿态,从而避开了与单独的自监督训练有关的挑战。86] 在不需要姿态信息的情况下从三组帧预测深度,但是他们的方法不能在测试时处理可变数量的帧,并且使用真实深度标签进行训练。在我们工作的同时,[85]从代价量中学习深度,但它们在训练时使用立体对和稀疏监督深度,并使用长序列进行姿态估计。
与我们最相关的是自监督的MVS方法,它也不需要任何地面真实深度,即[46,13]。然而,这些现有的自监督和监督的MVS方法在许多场景中不适用的原因有几个:
- 它们在测试时需要多于一个输入图像
- 它们假设摄像机不是静态的
- 它们通常要求在训练期间(有时也在测试时间)提供摄像机姿态
- 它们假设场景中没有移动对象。
我们的方法充分利用了单目和多视图方法中最好的一种,在测试时利用了序列信息,同我们的方法通过在测试时利用序列信息(当它可用时)利用单目和多视图方法的优点,同时对场景运动也具有鲁棒性——见表 1。
3 问题的设置
深度估计的目的是预测与输入图像It像素对齐的深度图DT。传统的单图像深度估计方法,例如[14,23,99],训练深度网络θdepth以从它映射到DT,

相比之下,像其他多帧方法[66,81],我们的模型接受N个之前的时间视频帧作为输入,
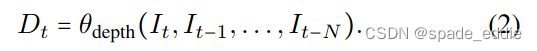
虽然我们的模型利用了来自多个帧的信息,但它也可以在测试时只有一个帧可用的情况下运行。与类似的方法不同,例如[50,97,9,59,5],我们在测试时不使用未来的帧,例如It+1,使用这些帧将排除在线应用。在训练时,我们利用以前和未来的帧作为监督信号,不需要立体声监督。我们没有假设可以访问它与之前帧之间的真实相对相机姿态;相反,我们学习在训练和测试时使用可微姿态网络θpose来预测这些姿态{Tn}Nn=1,遵循[99]。我们也不使用任何经过训练的语义模型来掩蔽移动对象,例如[5,26,29]。然而,我们确实假设已知的固定相机内参K–尽管我们可以放宽这些要求[26,18]。
4 方法论
我们的方法从两个成熟的组件开始:基于自监督重投影的训练和多视图代价量。然后,我们介绍了三个重要的创新,它们使得代价量匹配能够与来自单目视频的自监督训练一起工作:
(1)自适应代价量
(2)一种防止失败模式的方法,我们称之为‘代价量过度匹配‘
(3)静态摄像机和单帧输入的增强。
4.1 自监督单目深度估计
在[99]之后,我们仅使用时间上与其接近的视频帧来训练自监督深度网络。我们使用当前估计的深度Dt和姿态网络θpose对相对相机姿态Tt→t+n的估计来从与其相同的视点合成场景,但仅使用来自相邻源帧的像素,即{It+n,n∈{−1,1}}。它的合成对应物是
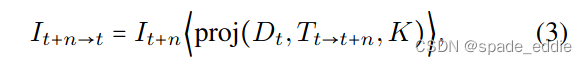
其中⟨⟩是采样运算符,Proj在重新投影到It+n的相机中时返回深度的2D坐标。请注意,尽管我们的代价量(稍后描述)仅使用先前的帧来启用在线应用程序,但在训练时间,我们的重新投影损失也使用未来的帧。在[24]之后,对于每个像素,我们通过选择重建损失Pe上的最小每个像素来优化最佳匹配源图像的损失,
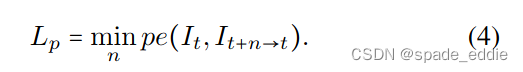
我们将PE设置为SSIM和L1损失的组合,并在四个输出尺度上最小化训练图像中的所有像素的损失;有关更多详细信息,请参见[24]。
4.2 构建代价量
为了利用多个输入帧,受[11,42,45]的启发,我们建立了一个代价量来衡量来自它的像素与来自输入视频的邻近源帧之间在不同深度值的几何兼容性。这需要相对姿态T的知识,我们使用姿态网络θpose估计相对姿态T,并使用重投影损失进行训练。我们定义了一组有序平面P,每个平面垂直于其上的光轴,并且深度在dmin和dmax之间线性间隔。每一帧被编码到深度特征图Ft中,并使用每个假设的可选深度d∈P,使用已知的相机内部函数和估计的姿态来扭曲到它的视点。这创建了扭曲特征图Ft+n→t, d。最终代价量被构造为在每个d∈P处扭曲特征与来自它的特征之间的绝对差。这是在所有源图像上求平均的,遵循[65]。代价量实际上是说‘对于像素(i,j),对于P中的每个d,正确深度为d的可能性是多少?’。在[19]之后,将代价量与特征Ft级联,并用作卷积解码器的输入,该卷积解码器回归深度Dt。有关概述请参见图2。
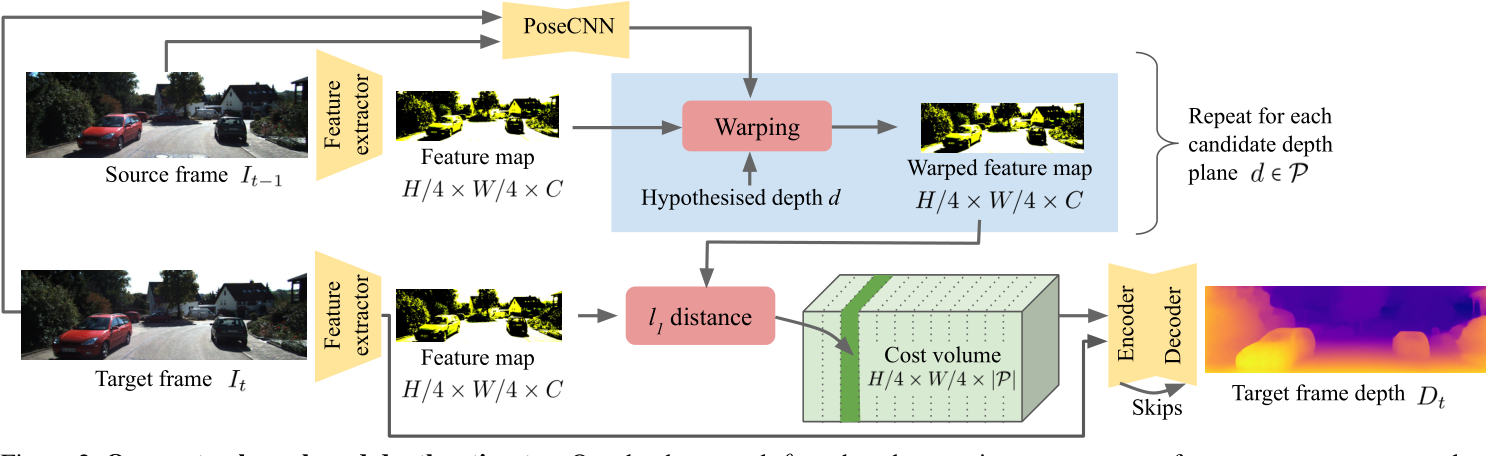
图 2. 我们基于成本量的深度估计器。 我们的深度网络 θdepth 具有三个主要组件:特征提取器、编码器和深度解码器。 我们的姿态网络 θpose 估计成对图像之间的相对姿态,然后通过扭曲从不同时间点的图像中提取的特征来在目标图像的参考框架中构建代价量。 编码器和深度解码器处理代价量以生成它的深度图像。
代价量的好处是允许网络利用来自多个视角的输入。但是,它们通常需要选择dmin和dmax作为超参数,并且它们假定世界是静态的。在接下来的几节中,我们将展示如何放松这些假设。
4.3 自适应代价量
代价量法有一个问题,即需要一个已知的深度范围,即dmin和dmax。这些通常是在训练之前根据数据集[13]的先验知识或从已知的相机姿态[37]选择作为超参数。我们无法做到这一点,因为在单目序列上训练的自监督深度估计只能“按比例”估计深度。这意味着,虽然我们假设最终预测的深度和来自姿态网络的相应姿态最终都将彼此广泛一致,但它们与真实世界的深度将有一个未知的比例因子不同。
为了解决这个问题,我们引入了一种新的自适应代价量,允许从数据中学习dmin和dmax,因此它们可以在训练期间随着网络发现自己的伸缩性而进行调整。这是使用来自DT网络的当前预测来完成的,由此我们计算训练批次上每个DT的平均最小和最大值。然后,这些被用来更新动量为0.99的dmin和dmax的指数移动平均估计。dmin和dmax与模型重量一起保存,然后在测试时保持不变。我们的方法与[27]他们在测试时以从粗到精的方式适应dmin、dmax形成了对比。
4.4 解决代价量过拟合
我们观察到,我们在单目监督下训练的基线代价量模型存在严重的伪影,包括在移动对象上打出的大“洞”。这些类似于在单目It→Dt模型中观察到的伪影(参见[5,24]以获取描述)。然而,在我们的代价量网络中,它们要严重得多(见图3©)。

图 3. 我们使自监督训练能够以代价量工作。 当我们从序列 (a) 构建代价量时,移动对象会在代价量 (b) 中创建不正确的深度。 这些误差会传播到我们预测的深度图 ©。 “传统的”单图像深度估计不会出现这种故障模式,但仍会产生偏差深度 (d)。 因此,我们使用单图像网络来帮助我们的模型从这种故障模式中恢复,但仅限于被我们的掩码 M (e) 识别为不可靠的像素。 我们的最终预测(f)优于我们的基线和单图像网络。
**为什么单目训练的代价量会失败?**理论上,我们的模式应该会做得很好。它使用类似的重投影损失进行训练,用于训练最先进的单帧深度估计器,但它还可以通过代价量获得额外的信息源。然而,代价量中包含的信息仅在特定情况下是可靠的,例如在具有纹理表面的静态区域中。在物体移动的区域,或表面没有纹理的区域,代价量将不是深度信息的可靠来源(图3(B))。例如,图3中移动的汽车在不正确的深度导致代价量的匹配,并且对应于非常低的重投影损失。在训练期间,网络变得过度依赖于代价。它没有忽视围绕移动物体的代价量,而是过于信任它。然后,在训练和测试期间,在最终深度图中引入来自移动对象的代价量中的瑕疵。最后,最终预测的深度继承了代价量的错误。我们介绍了一种在训练期间纠正这一问题的方法,通过教导网络不信任这些不可靠区域中的代价量。
**使用单独的网络进行正则化。**我们观察到,单幅图像深度网络不存在代价量,因此不受代价量过拟合的影响。虽然在训练期间移动对象仍然是这些方法的问题[5,24,69],但总的来说,它们在移动对象上犯的错误要小得多。因此,我们在训练阶段使用单目网络来帮助我们的代价量网络获得正确的答案–但仅限于我们怀疑代价量有问题的地区。这种单独的网络θconsistency为每个训练图像产生深度图ˆDT,并在训练后被丢弃。θconsistency与我们的主网络共享θpose,以帮助确保θdepth和θconsistency之间的尺度一致预测。我们的多帧输出中的潜在问题像素由二进制掩码M标识。在这些掩码区域中,我们对DT应用L1损失,鼓励预测类似于ˆDT,
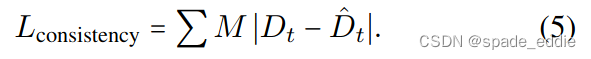
禁止ˆDT求导,确保知识只在教师和学生之间传输,而不是反过来。
**识别不可靠的像素。**我们的二进制掩码M在被认为不可靠的区域中为1,否则为0。为了生成此掩码,我们再次使用ˆDT。我们推断,在代价量可靠的地区,由ˆDT表示的深度将类似于由代价量的argmin表示的深度。因此,我们将代价量的argmin表示的深度(即Dcv,而不是Dt)与θconsistency预测的深度ˆDT进行比较。只有在ˆDT和Dcv显著不同的区域中,才将掩码M设置为1,因此
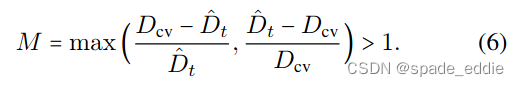
使用单独的“一次性”网络帮助训练正则化的想法并不新鲜,例如[69,99]。我们的创新之处在于使用了单帧深度网络来改进多帧系统。我们的方法也比使用离线语义分割[26]成本更低,限制更少,并且比基于RANSAC的过滤[29]做的假设更少。在我们的实验中,我们比较了[69]和[24]中的两种替代掩蔽方案,并表明我们的方法是优越的。
4.5 静态相机和开始序列
在测试时使用多个帧会给我们的方法带来两个潜在的挑战。
第一个问题是当It−1不存在时,即当预测单个图像或序列开始时的深度。这种情况可以通过单目方法简单地处理,因为它们只需要单帧作为输入。然而,MVS方法在这些情况下失败了。为了解决这个问题,在概率为p的训练过程中,我们将代价量替换为一个零张量。对于这些图像,这鼓励网络学习只依赖直接来自它的特征。然后在测试时,当It−1不存在时,我们简单地将代价量替换为0。
第二个问题是当摄像头在It−1和It之间不移动时,例如一辆汽车停在红绿灯前。同样,这也是MVS方法的另一个失败案例。为了在训练时解决这个问题,我们用概率q用颜色增强的版本来替换代价量的It−1输入,但仍然用公式4中的It−1,It+1进行监督。这使得网络能够预测合理的深度,即使当代价量是从没有相机基线的图像构建的时候也是如此。我们的最终损失是L=(1−M)LP+Lconsistency+Lsmooth,其中Lsmooth是来自[23]的平滑度损失。
5 实现细节
我们使用[24]中的设置,对馈送到深度和姿态网络的图像使用训练时间颜色和翻转增强。除非另有说明,否则我们所有的模型都是以640×192的输入和输出分辨率训练的,我们固定N=1,所以在训练和测试时都用帧{It,It-1}来构造代价量。在所有情况下,训练期间的自监督都来自帧It-1, It,It+1}。我们用Adam[47]训练了20个epoch,学习率为10−4,在最后5个epoch中下降了10倍。在Q个历元之后,我们确定了dmin和dmax以及θpose和θconsistency的权重。这允许θdepth与不移动的目标进行微调。我们为Kitti设置Q=15,为Cityscapes设置Q=5,以说明Cityscapes训练集中的图像数量较多。
θdepth中的特征提器包括前五个ResNet18层[33]。这些特征被聚合成代价量,其结果与我们的输入图像特征级联,然后是剩余的ResNet18卷积层。我们使用的是[24]中的深度解码器。我们的姿态网络θpose和θdepth的跳越连接与[24]相同。θconsistancy使用[24]中的标准体系结构,未做任何修改。完整的体系结构细节在B部分。按照[24,83,79,31],我们使用在ImageNet[70]上预先训练的权重,但在补充材料中提供从头开始训练的结果,参见表8。对于我们的所有实验,我们在训练期间设置p=q=0.25。
6 实验
在这里,我们评估我们的ManyDepth模型,(1)显示它通过以标准化的方式与单帧和多帧深度估计进行比较来给出SOTA结果,以及(2)通过消融实验来验证我们的设计决策。补充材料中提供了其他结果。我们在两个具有挑战性的深度估计数据集上进行了评估,这两个数据集都显示了移动对象。对于两者,我们使用来自[14,15]的标准深度评估度量。
(A)Kitti[22]。我们使用[14]中的Eigen split。这通常用于单帧深度估计,但最近也用于多帧方法,例如[81,66]。Kitti Eigen测试集中的22个帧位于序列的开头,没有先前的帧。我们仍然将这些图像包括在评估中。对于这些图像,网络无法访问任何其他帧,因此仅基于一个帧进行预测。在表13中,我们还包括根据改进的Kitti真实深度标签评估模型[76]。
(B)Cityscapes[12]。在[99,90,92]之后,我们对来自单目序列的69,731幅图像进行训练,并使用[99]中的脚本将其预处理成三元组。我们不使用立体声对或语义。我们使用提供的SGM[34]视差图对1,525个测试图像进行评估。与Kitti一样,我们将预测深度限制在80米,并仅根据低于80米的真实深度值进行评估。
6.1 KITTI结果
在表2中,我们比较了多帧方法,其中一些方法,例如[9,5,66,79,62],比我们看到更多的帧,或者也使用未来的帧,例如[9,5,62]。我们不包括[56]的结果,因为他们没有提供Kitti Eigen Split的分数(参见[88])。此外,我们还与性能最好的自监督单目深度估计方法进行了比较。为了控制分辨率,我们将低分辨率模型和高分辨率模型分开,并将使用昂贵的多遍测试时间精化的方法分成单独的部分。我们观察到,我们的方法比之前发布的所有自监督方法都要好,这些方法在大多数指标上都没有使用语义监督。
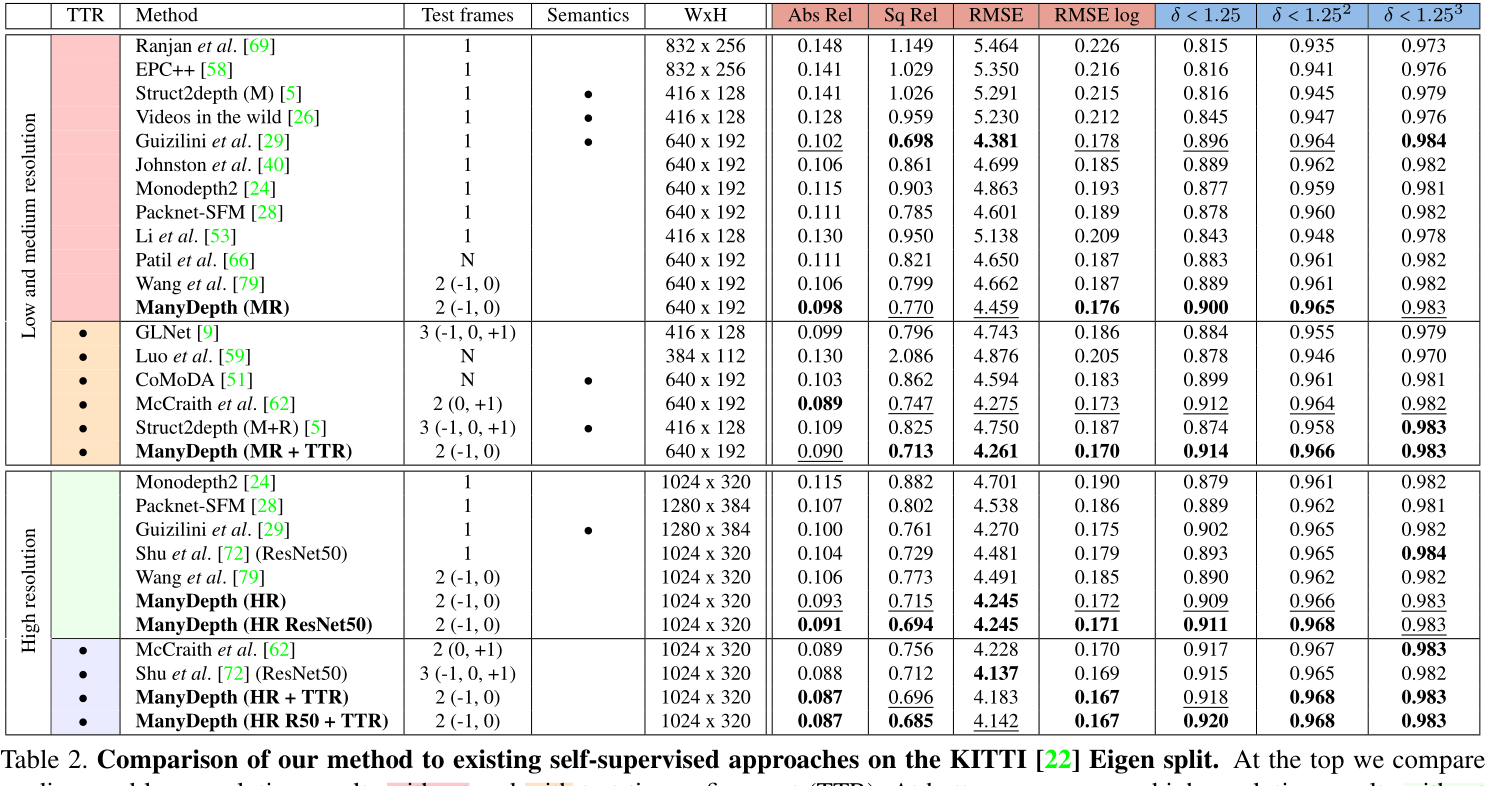
表 2. 我们的方法与 KITTI [22] Eigen split 上现有的自我监督方法的比较。 在顶部,我们比较了没有和有测试时间细化 (TTR) 的中低分辨率结果。 在底部,我们比较了没有和有 TTR 的高分辨率结果。 每个小节中的最佳结果以粗体显示; 次优加下划线。 我们的方法在大多数指标的所有小节中都优于所有以前的方法,无论基线是否在测试时使用多个帧。 我们指出一种方法是否使用语义监督(语义),并且由 N 表示的方法将一长串帧作为每个测试图像的输入(例如,前一帧或时间前后的帧)。
我们还在我们的模型上实现了[62]的测试期间改进方案,使用来自测试集中的连续图像对来更新深度和姿态编码器的权重,持续50步。毫不奇怪,这进一步改进了我们的结果,并且我们的性能优于其他测试时间优化方法。
定性结果如图4所示。在某些情况下,预测的深度图看起来与单目模型定性相似,但误差图显示了可能存在的高错误程度。

图4. Kitti的定性结果。第2栏和第4栏中显示了abs_rel,即与新的真实深度标签[76]相比的误差图,从好(蓝色)到坏(红色)。所有误差图都被等同地进行颜色映射。虽然深度图在我们的多帧预测(底部几行)和基线之间看起来定性上相似,但误差图揭示了只能访问单个测试时间图像的方法所犯的巨大“隐藏错误”。这在模棱两可的地区尤其明显,例如在高速公路右侧的黑暗路堤。此外,请注意,[66]也可以在测试时访问多个帧,但是他们的方法不显式使用几何体。这导致了比单帧[24]更好的结果,但误差明显高于我们的方法。
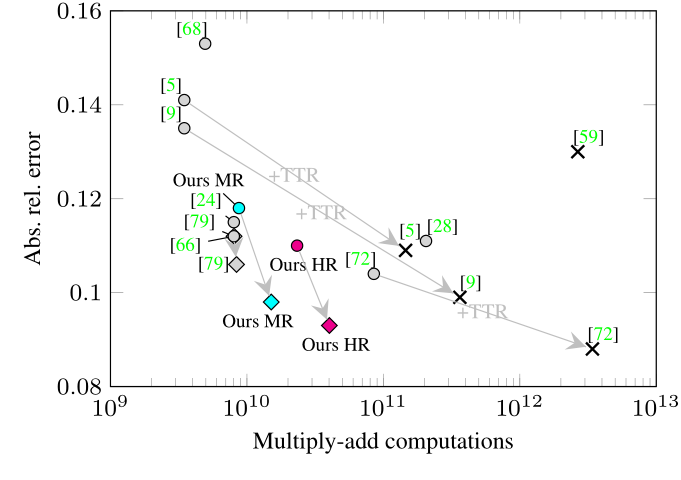
**效率比较。**图5说明了我们的ManyDepth模型(640x192:和1024x320:)与其他方法(包括测试时间精化方法())相比的运行效率。我们报告了每种方法的乘加计算(MAC),并表明执行多个正反向遍的测试时间求精模型对计算的要求太高,无法用于实时应用。完整的结果表请参见表11,更多详细信息请参见第C节。

6.2 KITTI消融实验
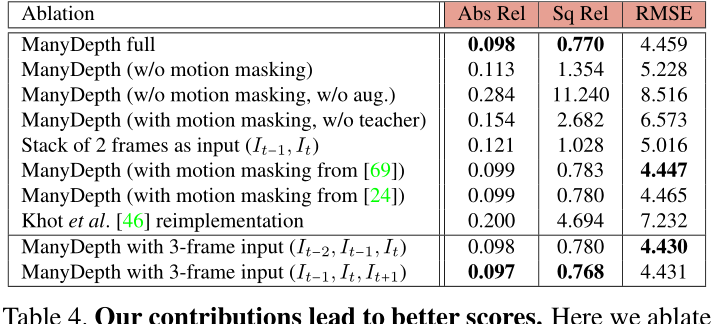
表 4. 我们的贡献带来了更好的分数。 在这里,我们使用 Eigen 拆分在 KITTI 2015 [22] 上消融了我们的 ManyDepth 方法。 完整的数字在表 7 中。
在表4中,我们通过轮流打开和关闭来显示我们方法的各个组件的重要性。
- 许多深度无运动掩码:我们省略了损失中的一致性,并将M到处设置为零。
- 许多深度无运动掩码,无增强:如上所述,但也省略了我们的增强。
- ManyDepth有运动遮罩,但没有老师:我们删除了LConsistency,但仍然使用M来遮罩Lp。
- 堆叠2帧作为输入:直接将(it−1,it)映射到dt的基线。我们修改了[24]的网络,以接受两个图像作为输入,并使用它们的损失进行训练。
- 许多使用[69]的运动掩码:我们使用我们的全部损失,但我们的掩码M与[69]相同。我们使用他们的预训练模型来离线计算整个训练集的这些掩模。
- 许多使用[24]的运动掩蔽:这里我们使用我们的全部损失,但将掩码M设置为来自[24]的‘自动掩码’。
- [46]:我们在KITTI上训练了这种无监督的MVS方法,实施自[30].
- ManyDepth(it−2,it−1,it)和ManyDepth(it−1,it,it+1):重新训练了我们的模型的变体,它从三个帧而不是只有两个帧构建代价量。这改善了一些指标,但不是全部。
从我们的扩容中获益。在表5中,我们评估了三个不同的场景,将我们的模型与没有在第4.5节中进行增强的情况下进行训练的基线进行比较。当在标准模式下(即使用先前和当前帧作为输入)对整个Kitti测试集进行评估时,两个模型之间的差异可以忽略不计。这在一定程度上是因为Kitti测试的图像主要来自移动的相机。然而,当我们在序列开始模式(即仅使用(It)作为输入的标准单目设置)和‘静态摄像机’评估模式(即模拟具有输入(it,it)的静态摄像机)下进行评估时,我们的增强方案明显更好。
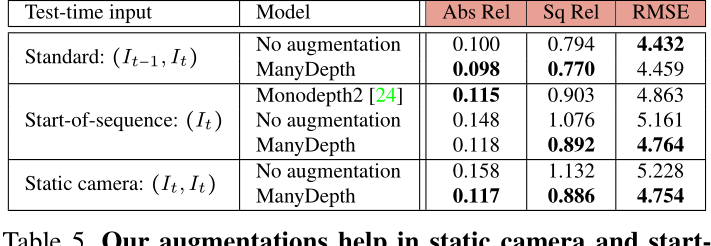
表 5. 我们的增强有助于静态相机和序列开始的情况。 我们比较了我们模型的两种变体,一种用我们的新数据增强(“我们的”)训练,另一种没有。 我们创建了两个人工场景来测试每个模型在序列开始图像(我们刚刚输入它的地方)和静态相机(两个输入帧完全相同)上的性能。
6.3 Cityscapes结果
在表3中,我们在城市景观数据集[12]上进行训练和测试,并执行额外的比较。同样,我们的表现始终优于竞争对手的方法,即使是那些使用语义监督的方法。
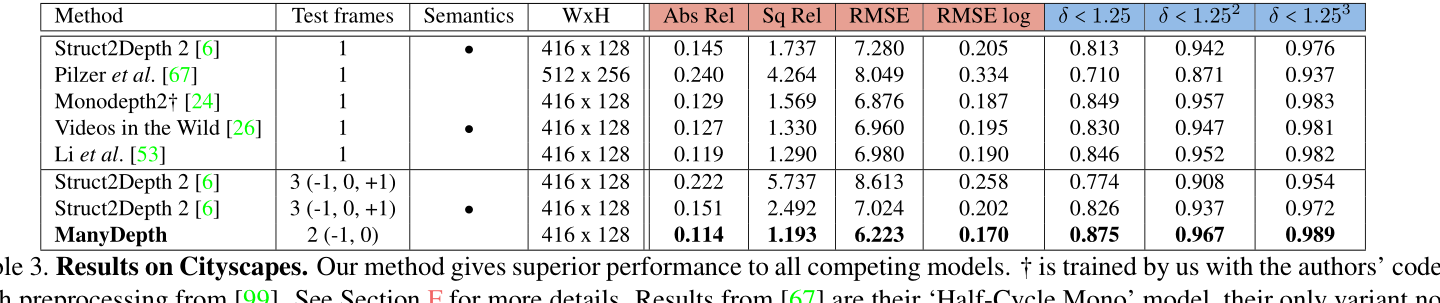
表 3. Cityscapes的结果。 我们的方法为所有竞争模型提供了卓越的性能。 † 由我们使用作者的代码进行训练,预处理来自 [99]。 有关详细信息,请参阅 F 部分。 [67] 的结果是他们的“半周期单声道”模型,他们唯一的变体不需要测试时立体声对。 在与作者交谈后,我们使用 [6] 的裁剪方案进行评估; 详见 E.1 节。
7 结论
我们提出了一种完全自监督的在线方法,可以从单个图像或多个可用的图像预测更高的深度。我们实现了多帧和单目方法的好处,同时在移动对象和静态摄像机上更健壮,而不是简单的集成代价量。我们展示了KITTI和cityscape数据集的最新结果。虽然测试时细化方法在深度精度方面是接近的竞争对手,但我们已经表明,我们的方法在推断期间明显更有效。我们希望通过最近在单眼深度估计方面的互补进展,例如离散输出深度[25]或基于特征的损耗,我们的结果能够得到进一步的改善[72]。

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









