







「Method」如何用Excel計算Z分數 How To Calculate Z Scores In Excel_哔哩哔哩_bilibili
将如下数据
转换成 z-score标准化后的数据
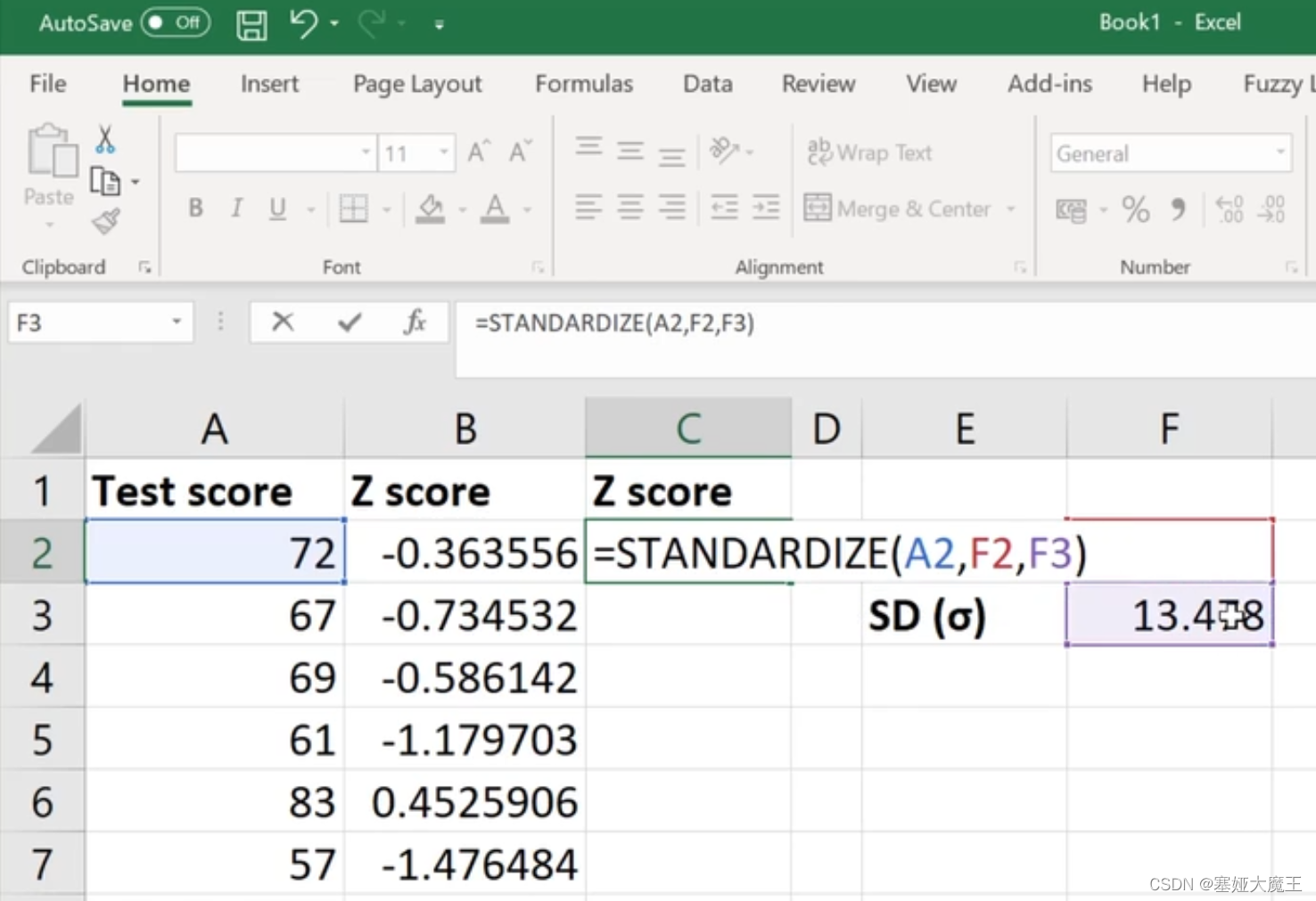
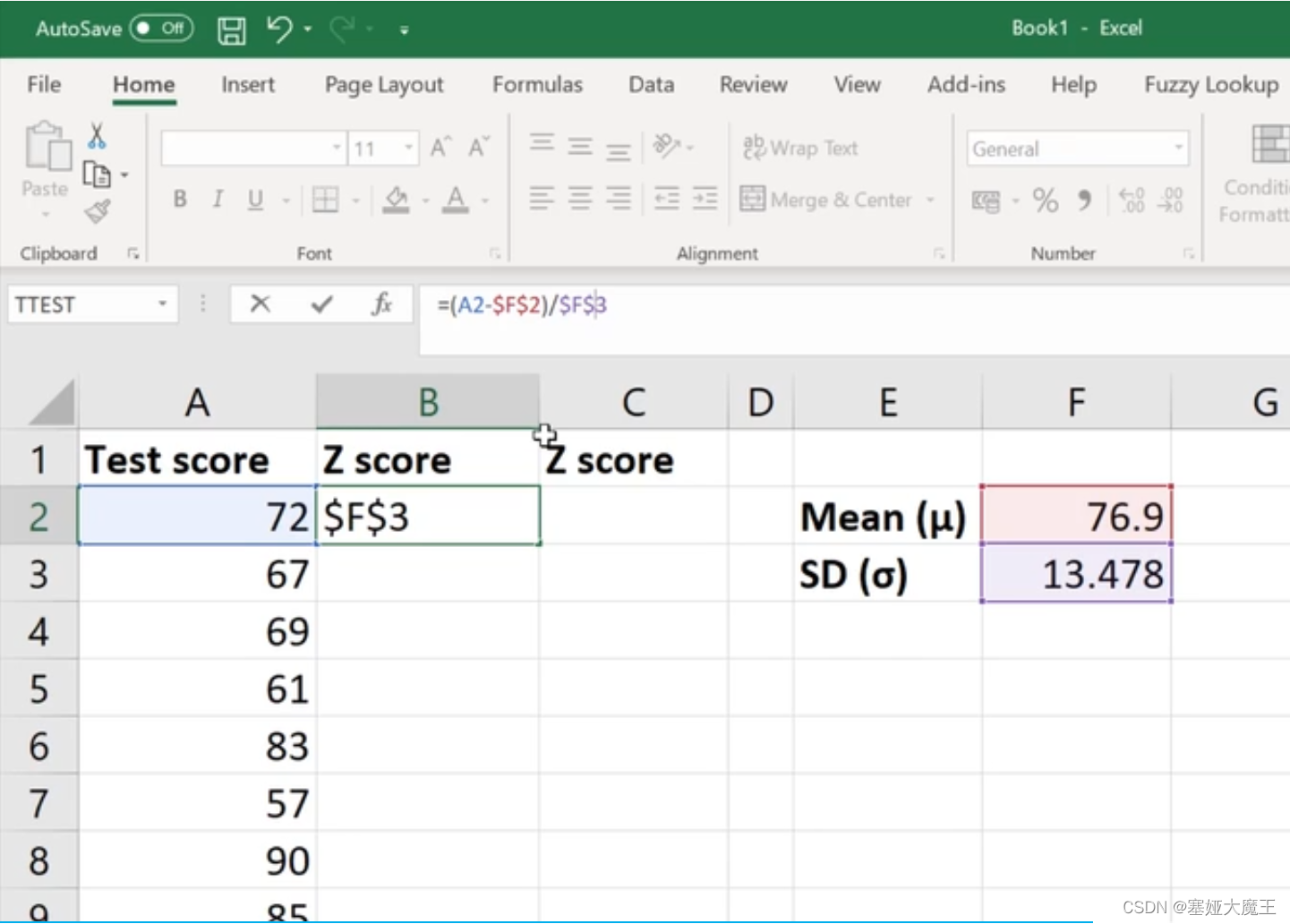
计算Mean (μ) 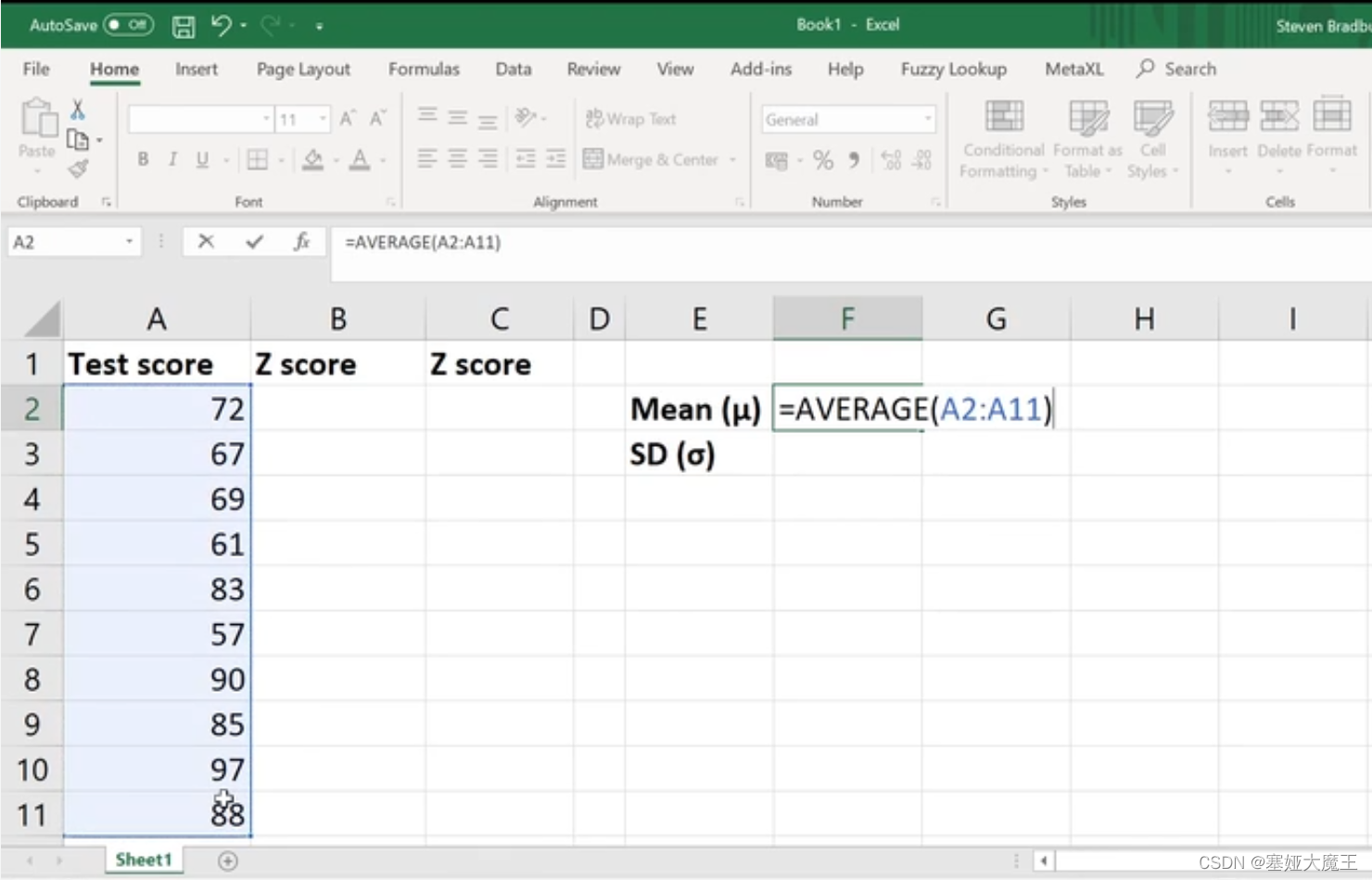
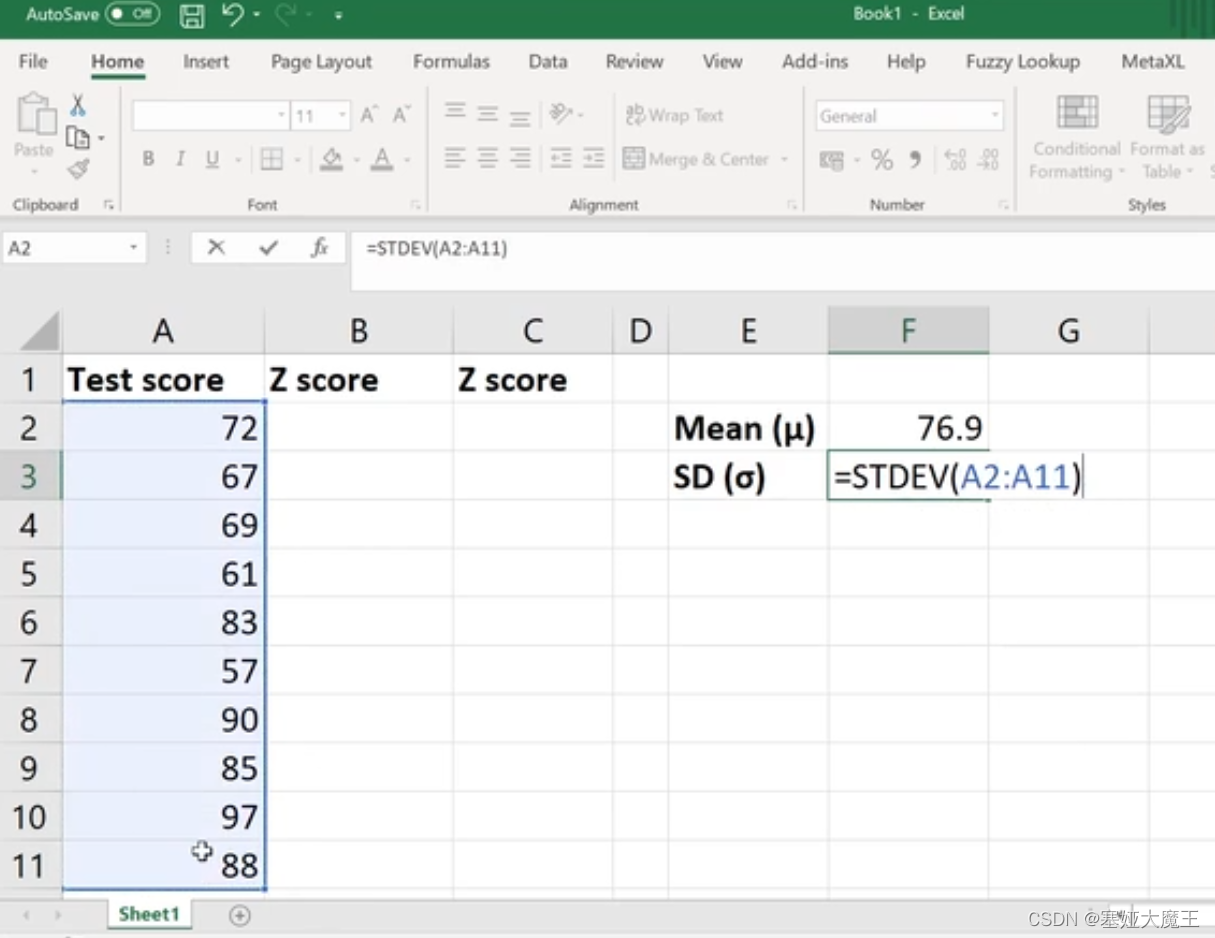
计算SD (σ)
进行z-score标准化
方法一
方法二
「Method」如何用Excel計算Z分數 How To Calculate Z Scores In Excel_哔哩哔哩_bilibili
将如下数据
转换成 z-score标准化后的数据
 1567
1515
5508
1万+
1567
1515
5508
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























