







补充一个小wiki:
https://zh.wikipedia.org/wiki/%E5%95%9F%E5%8B%95%E5%AD%90
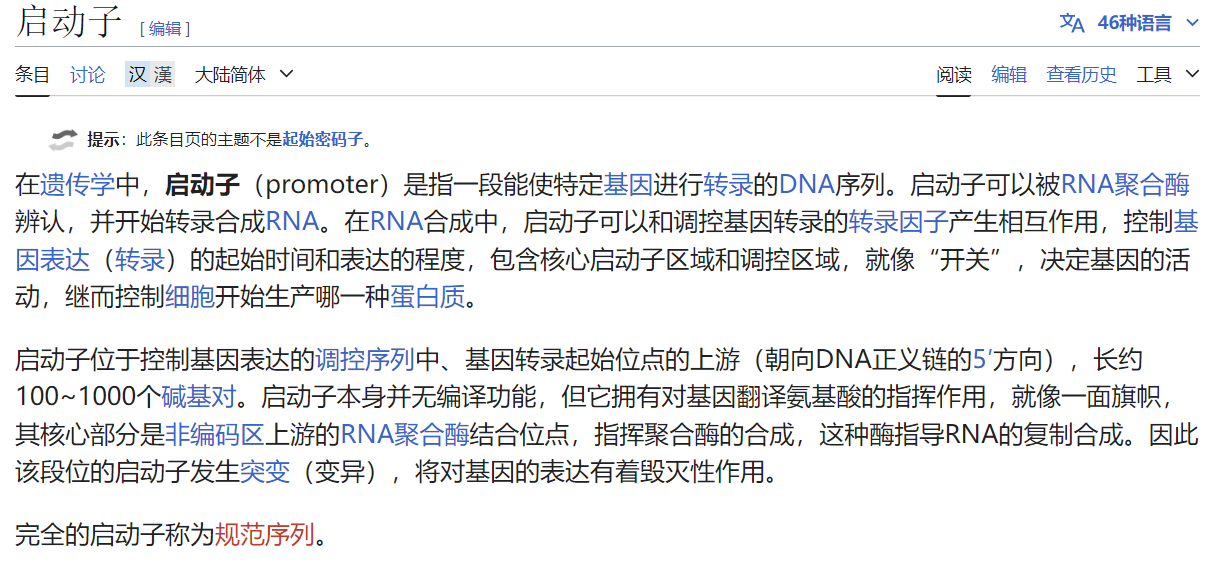
注意:
启动子是对应gene的调控区域序列,启动子在non-coding区,gene则是常规的coding-sequence(也就是coding region)——这是两个分隔的区域
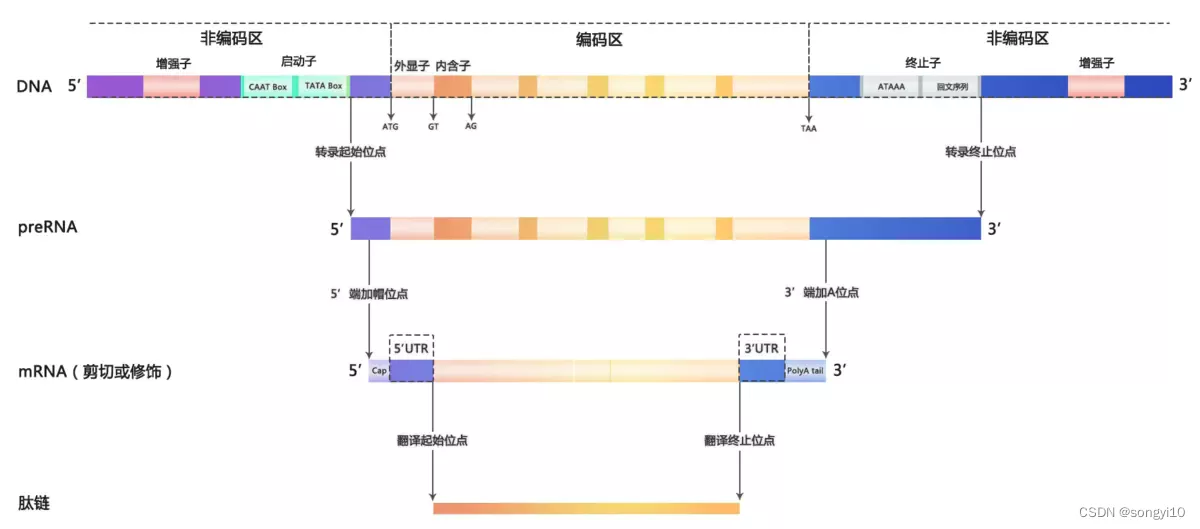
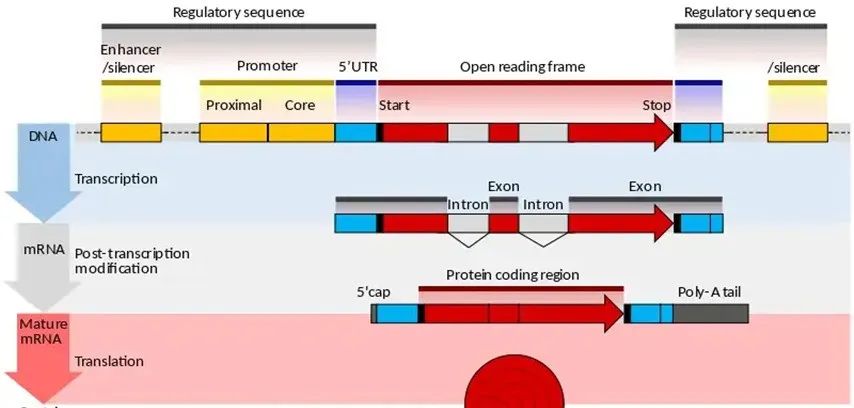
启动子一般在gene上游,结构上再启动子-gene的1st外显子之间还有一段序列,不然为什么分隔?

起始密码子是在第一个外显子上的前3个碱基;
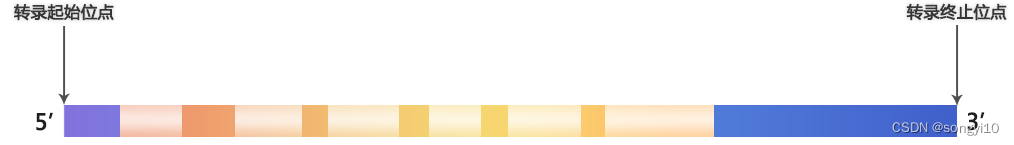
其实这一段分隔出来的区域是5’-UTR,也就是非翻译区(当然能转录)
所以大致序列分布,在脑海中有个印象:
启动子region-TSS-5’ UTR-gene(此时是第一个exon)

总之理解概念序列分布即可:
启动子region-TSS-5’ UTR-gene(此时是第一个exon)
此处粗略使用TSS作为分界线,以上下游区分启动子、5’ UTR区域等
部分ref:https://blog.csdn.net/songyi10/article/details/126413932
当然做生信分析时就比较粗糙了(部分涉及到bed文件集合运算等,主要是交集运算等):

其实我们一般的疑惑是:
TSS与启动子的关系
https://mp.weixin.qq.com/s/n4wsmH6cXJqES9AmaQk3nw
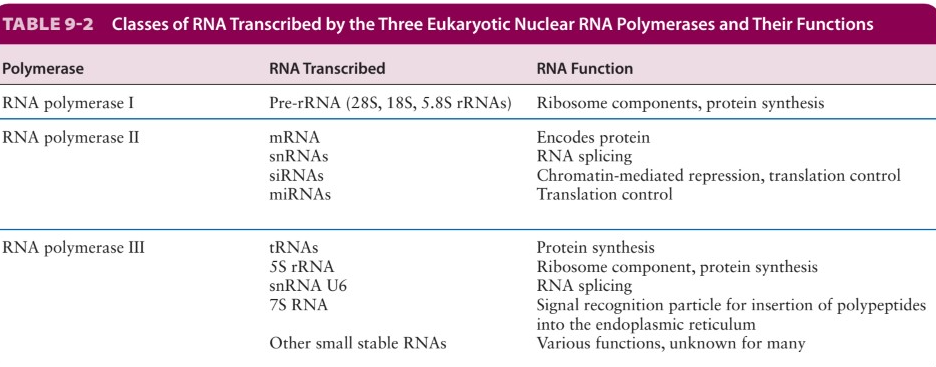
众所周知真核生物有3种RNA pol,我们主要关注的是pol II,因为其主要转录mRNA,也就是coding gene,而蛋白质编码gene是我们主要关注的;
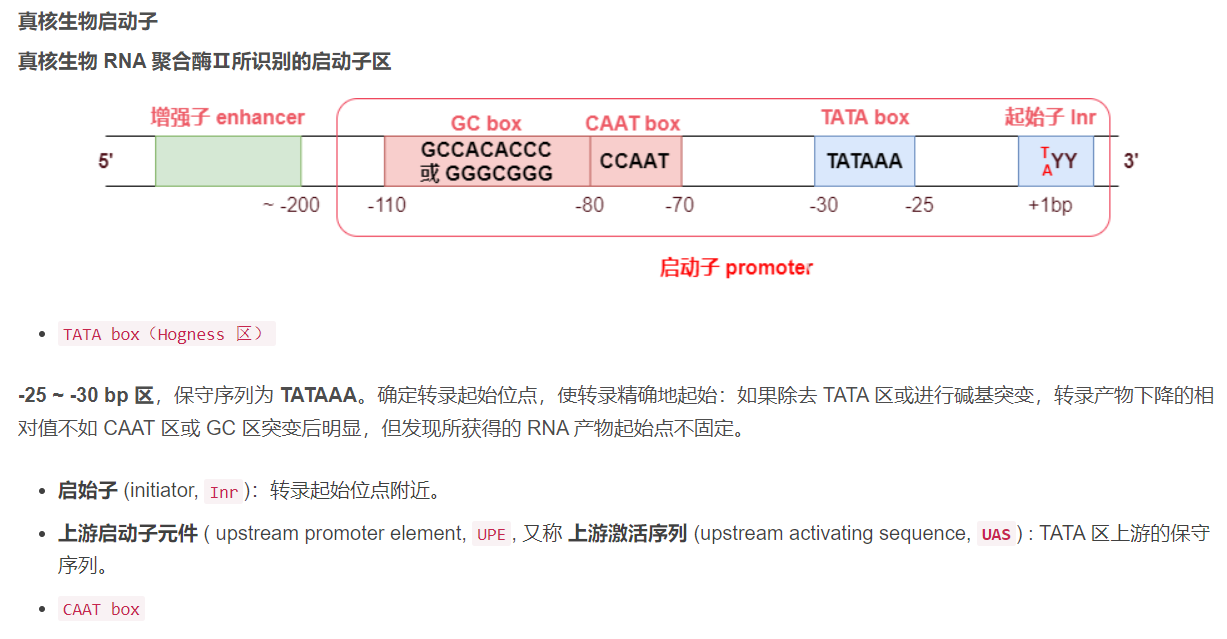
所以对应pol II识别的II类启动子结构是我们首要关注的重点:

(from个人高级生化课件——至少这个是真的,是我课上的课件,以这个为准)

综上:
在我们生信研究的一般背景或者是语境中:
我们所说的启动子(也就是II类启动子)是包含TSS的,
也就是**TSS是在启动子序列中**的
实际上是:启动子包含起始子/引发子Inr元件(而Inr以TSS为中心)
启动子region(Inr中含有TSS)-5’ UTR-gene(此时是第一个exon)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









