







原文:Ryan Siegler RAG + LlamaParse: Advanced PDF Parsing for Retrieval
Github:https://github.com/KxSystems/kdbai-samples/blob/main/LlamaParse_pdf_RAG/llamaParse_demo.ipynb

检索增强生成(RAG)的核心重点是将您感兴趣的数据连接到大型语言模型(LLM)。这一过程将生成式人工智能的能力与您的数据相结合,实现基于您特定数据集的复杂问题回答和LLM生成的见解。我假设这些RAG系统不仅将对我们通常看到的聊天机器人类型应用有用,还将整合到旨在改善业务决策并进行预测的创新人工智能应用中。
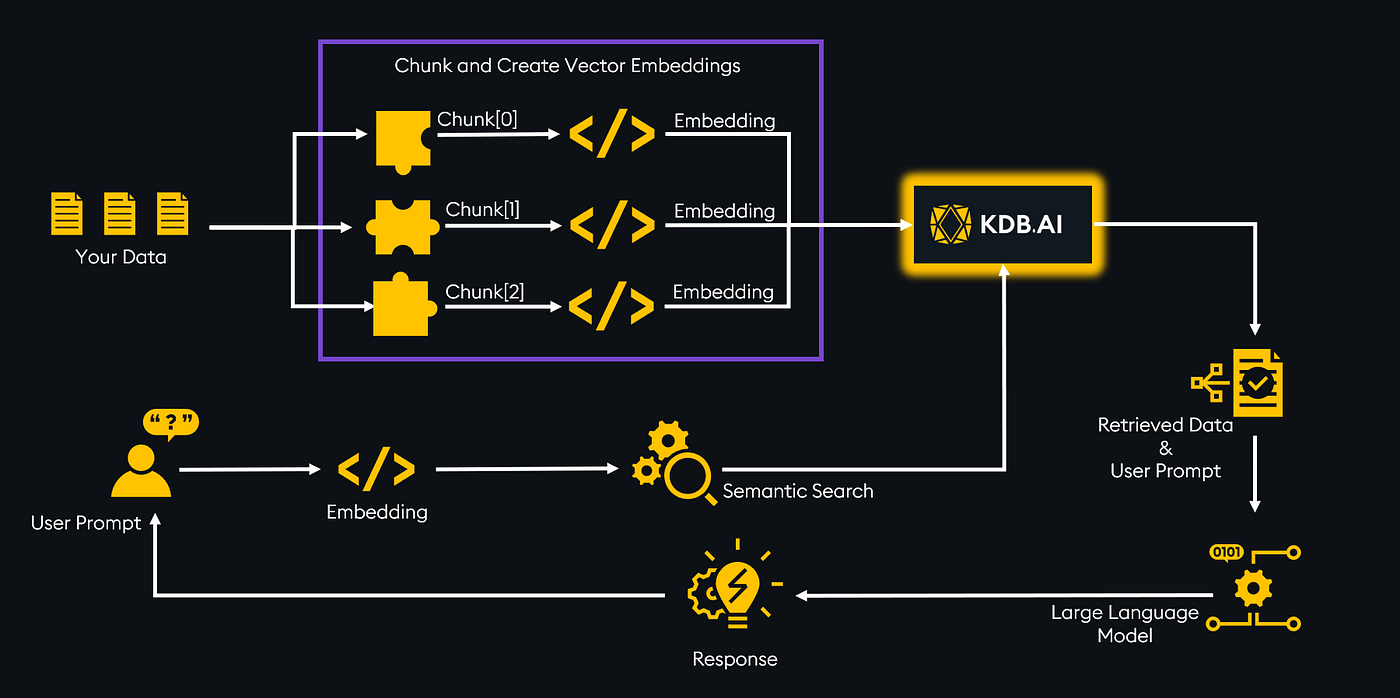
使用 KDB.AI 矢量数据库的示例 RAG 架构
毫无疑问,RAG 的实用性,随着技术的不断改进,我们可以期待更多变革性应用,这些应用将彻底改变我们从信息中学习和互动的方式。
但是… PDF 问题…
重要的半结构化数据通常存储在诸如难以处理的 PDF 文件之类的复杂文件类型中。想想看,重要文档经常以 PDF 格式存储 — 例如收益电话会议记录、投资者报告、新闻文章、10K/10Q 文件以及 ARXIV 上的研究论文等。我们需要一种方法,能够清晰高效地从这些 PDF 文件中提取嵌入的信息,如文本、表格、图像、图表等,以便将这些重要数据摄入到 RAG 管道中。
进入:LlamaParse
LlamaParse 是一种生成式人工智能启用的文档解析技术,专为包含表格和图形等嵌入对象的复杂文档设计。
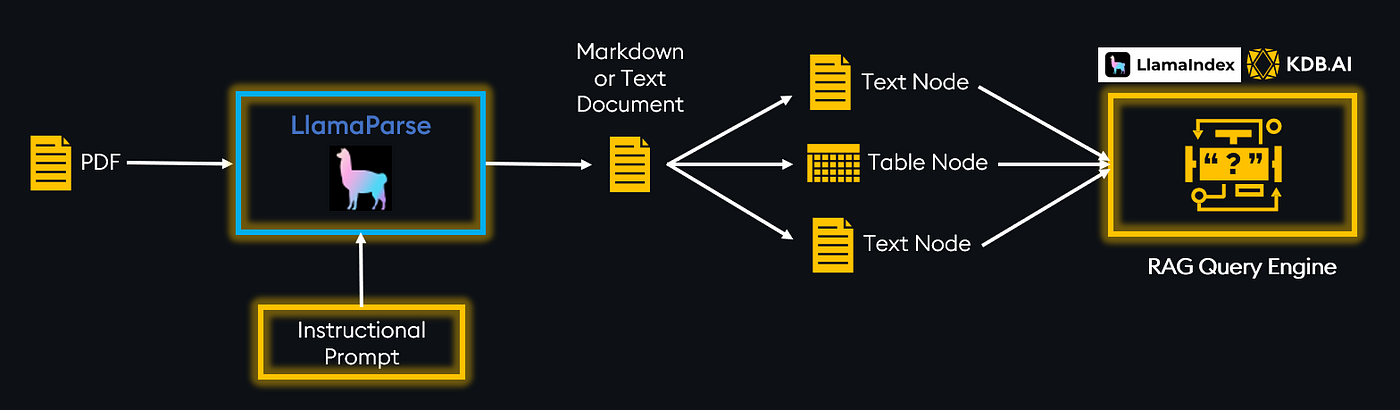
使用 LlamaParse 摄入复杂文档
LlamaParse 的核心功能是实现对这些复杂文档(如 PDF)的检索系统的创建。LlamaParse 通过从这些文档中提取数据并将其转换为易于摄入的格式(如 markdown 或文本)来实现这一点。一旦数据被转换,就可以将其嵌入并加载到您的 RAG 管道中。
有关 LlamaParse 的详细信息,请查看 LlamaIndex 的这篇博客。
LlamaParse 功能概述:
-
支持的文件类型:PDF、.pptx、.docx、.rtf、.pages、.epub 等…
-
转换的输出类型:Markdown、文本
-
提取能力:文本、表格、图像、图表、漫画、数学方程
-
定制解析指令:由于 LlamaParse 是 LLM 启用的,您可以像提示 LLM 一样传递指令。您可以使用此提示描述文档,从而为 LLM 在解析时提供更多上下文,指示您希望输出的外观,或要求 LLM 在解析过程中执行预处理,如情感分析、语言翻译、摘要等…
-
JSON 模式:输出文档的完整结构,提取带有大小和位置元数据的图像,以 JSON 格式提取表格,以便进行轻松分析。这对于定制的 RAG 应用程序非常理想,其中文档结构和元数据用于最大化文档的信息价值,并用于引用检索节点在文档中的位置。
Markdown 的优势
LlamaParse 将 PDF 转换为 markdown 格式具有一些独特的优势。Markdown 通过识别结构元素(如标题、标头、子标题、表格和图像)来指定文档的固有结构。这可能看似微不足道,但由于 markdown 识别这些元素,我们可以使用 LlamaIndex 的专门解析器(如 MarkdownElementNodeParser())轻松地根据结构将文档拆分为更小的块。将 PDF 文件表示为 markdown 格式的结果是使我们能够提取 PDF 的每个元素并将其摄入到 RAG 管道中。
代码
以下代码演示了一个摄入 PDF 文件的 RAG 管道的实现。
在我们的 GitHub 上查看完整笔记本,或在 Colab 上打开笔记本。
安装并导入库:
!pip install llama-index
!pip install llama-index-core
!pip install llama-index-embeddings-openai
!pip install llama-parse
!pip install llama-index-vector-stores-kdbai
!pip install pandas
!pip install llama-index-postprocessor-cohere-rerank
!pip install kdbai_client
from llama_parse import LlamaParse
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core import VectorStoreIndex
from llama_index.core.node_parser import MarkdownElementNodeParser
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.vector_stores.kdbai import KDBAIVectorStore
from llama_index.postprocessor.cohere_rerank import CohereRerank
from getpass import getpass
import kdbai_client as kdbai
为LlamaCloud、OpenAI和Cohere设置API密钥:
# llama-parse是异步优先的,要在笔记本中运行异步代码,需要使用nest_asyncio
import nest_asyncio
nest_asyncio.apply()
import os
# 访问llama-cloud的API
os.environ["LLAMA_CLOUD_API_KEY"] = "llx-"
# 使用OpenAI API进行嵌入/llms
os.environ["OPENAI_API_KEY"] = "sk-"
# 使用Cohere进行重新排序
os.environ["COHERE_API_KEY"] = "xyz..."
设置KDB.AI向量数据库(免费注册在这里):
#设置KDB.AI端点和API密钥
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
#连接到KDB.AI
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
为KDB.AI表创建模式并创建表格:
# 模式包含两个元数据列(document_id,text)和一个嵌入列
# 在嵌入列中指定索引类型、搜索度量(欧几里得距离)和维度
schema = dict(
columns=[
dict(name="document_id", pytype="bytes"),
dict(name="text", pytype="bytes"),
dict(
name="embedding",
vectorIndex=dict(type="flat", metric="L2", dims=1536),
),
]
)
KDBAI_TABLE_NAME = "LlamaParse_Table"
# 首先确保表格不存在
if KDBAI_TABLE_NAME in session.list():
session.table(KDBAI_TABLE_NAME).drop()
#创建表格
table = session.create_table(KDBAI_TABLE_NAME, schema)
下载一个示例PDF,或导入您自己的PDF:
这个PDF是一篇名为“LLM In-Context Recall is Prompt Dependent”的精彩文章,作者是来自VMware NLP实验室的Daniel Machlab和Rick Battle。
!wget 'https://arxiv.org/pdf/2404.08865' -O './LLM_recall.pdf'
让我们使用LLM和嵌入模型设置LlamaParse和LlamaIndex:
EMBEDDING_MODEL = "text-embedding-3-small"
GENERATION_MODEL = "gpt-3.5-turbo-0125"
llm = OpenAI(model=GENERATION_MODEL)
embed_model = OpenAIEmbedding(model=EMBEDDING_MODEL)
Settings.llm = llm
Settings.embed_model = embed_model
pdf_file_name = './LLM_recall.pdf'
创建自定义解析指令以传递给LlamaParse:
parsing_instructions = '''The document titled "LLM In-Context Recall is Prompt Dependent" is an academic preprint from April 2024, authored by Daniel Machlab and Rick Battle from the VMware NLP Lab. It explores the in-context recall capabilities of Large Language Models (LLMs) using a method called "needle-in-a-haystack," where a specific factoid is embedded in a block of unrelated text. The study investigates how the recall performance of various LLMs is influenced by the content of prompts and the biases in their training data. The research involves testing multiple LLMs with varying context window sizes to assess their ability to recall information accurately when prompted differently. The paper includes detailed methodologies, results from numerous tests, discussions on the impact of prompt variations and training data, and conclusions on improving LLM utility in practical applications. It contains many tables. Answer questions using the information in this article and be precise.'''
运行LlamaParse并打印一些markdown输出!
documents = LlamaParse(result_type="markdown", parsing_instructions=parsing_instructions).load_data(pdf_file_name)
print(documents[0].text[:1000])
从markdown文件中提取base_nodes(文本)和object nodes(表格):
# 使用MarkdownElementNodeParser解析文档
node_parser = MarkdownElementNodeParser(llm=llm, num_workers=8).from_defaults()
# 检索节点(文本)和对象(表格)
nodes = node_parser.get_nodes_from_documents(documents)
base_nodes, objects = node_parser.get_nodes_and_objects(nodes)
创建一个利用KDB.AI的索引:
vector_store = KDBAIVectorStore(table)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
#创建索引,将base_nodes和objects插入到KDB.AI中
recursive_index = VectorStoreIndex(
nodes= base_nodes + objects, storage_context=storage_context
)
# 查询KDB.AI以确保节点已插入
table.query()
创建一个LlamaIndex查询引擎来执行RAG流程:
- 我们使用Cohere reranker来帮助改进结果
### 定义reranker
cohere_rerank = CohereRerank(top_n=10)
### 创建查询引擎以使用LlamaIndex、KDB.AI和Cohere reranker执行RAG流程
```python
query_engine = recursive_index.as_query_engine(similarity_top_k=15, node_postprocessors=[cohere_rerank])
```python
让我们来试一下:
query_1 = “仅使用提供的信息描述草堆中的针方法”
response_1 = query_engine.query(query_1)
print(str(response_1))
输出:
\>>>*草堆中的针方法涉及将一个事实(称为“针”)嵌入到一段填充文本(称为“草堆”)中。然后,模型被要求检索这个嵌入的事实。通过在不同长度的草堆和不同针的放置位置上评估模型的召回性能,以识别性能模式。该方法表明,LLM召回信息的能力不仅受提示内容的影响,还受其训练数据中潜在偏见的影响。对模型的架构、训练策略或微调的调整可以增强其召回性能,为更有效的应用提供LLM行为的见解。*
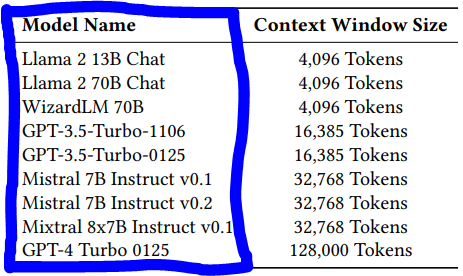
query_1 = “列出使用草堆中的针测试评估的LLM”
response_1 = query_engine.query(query_1)
print(str(response_1))
输出(此输出摘自PDF文档中的表格):
\>>>*Llama 2 13B、Llama 2 70B、GPT-4 Turbo、GPT-3.5 Turbo 1106、GPT-3.5 Turbo 0125、Mistral v0.1、Mistral v0.2、WizardLM 和 Mixtral 是使用草堆中的针测试评估的LLM。*
query_1 = “在旧金山做什么最好?”
response_1 = query_engine.query(query_1)
print(str(response_1))
输出(此输出摘自PDF文档中的表格):
\>>>*在旧金山做的最好的事情是在一个阳光明媚的日子里吃个三明治,坐在多洛雷斯公园里。*

# 总结
在这个演示中,我们探讨了如何在复杂的PDF文档上构建一个检索增强生成管道。我们使用LlamaParse将PDF转换为markdown格式,提取文本和表格,并将它们输入到KDB.AI中,以便使用LlamaIndex查询引擎进行检索。随着RAG系统的投入生产,重要的是它们能够吸收复杂文档类型中保存的知识 — LlamaParse实现了这一点!


















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











