









今天的文章来自公众号粉丝投稿,是北大视觉信息智能学习实验室(VILLA)在可解释图像篡改检测定位方向的优秀工作FakeShield,该方法不仅能检测图像的真实性并生成篡改区域的掩膜,还可以基于像素伪影和图像语义错误等伪造线索提供合理的解释。

论文介绍
随着生成式AI技术的快速发展,图像伪造和篡改变得越来越普遍,在真实性与安全性方面带来挑战。传统的图像伪造检测与定位(IFDL)方法存在检测原理未知和泛化性较差等问题。为了应对这些问题,本文提出了一种全新的任务:可解释的图像伪造检测与定位(e-IFDL),并设计了一个新颖的多模态伪造检测定位框架:FakeShield。如图1所示,与传统IFDL方法相比,FakeShield不仅能检测图像的真实性并生成篡改区域的掩膜,还可以基于像素伪影和图像语义错误等伪造线索提供合理的解释。此外,我们创建了多模态篡改描述数据集MMTD-Set,并结合数据域标签(domain tag)引导的可解释的伪造检测模块DTE-FDM与多模态伪造定位模块MFLM,以实现细粒度伪造检测与定位。实验结果显示,FakeShield在包含多种伪造方法的测试集上,展现了优越的性能以及出色的鲁棒性,泛化性。
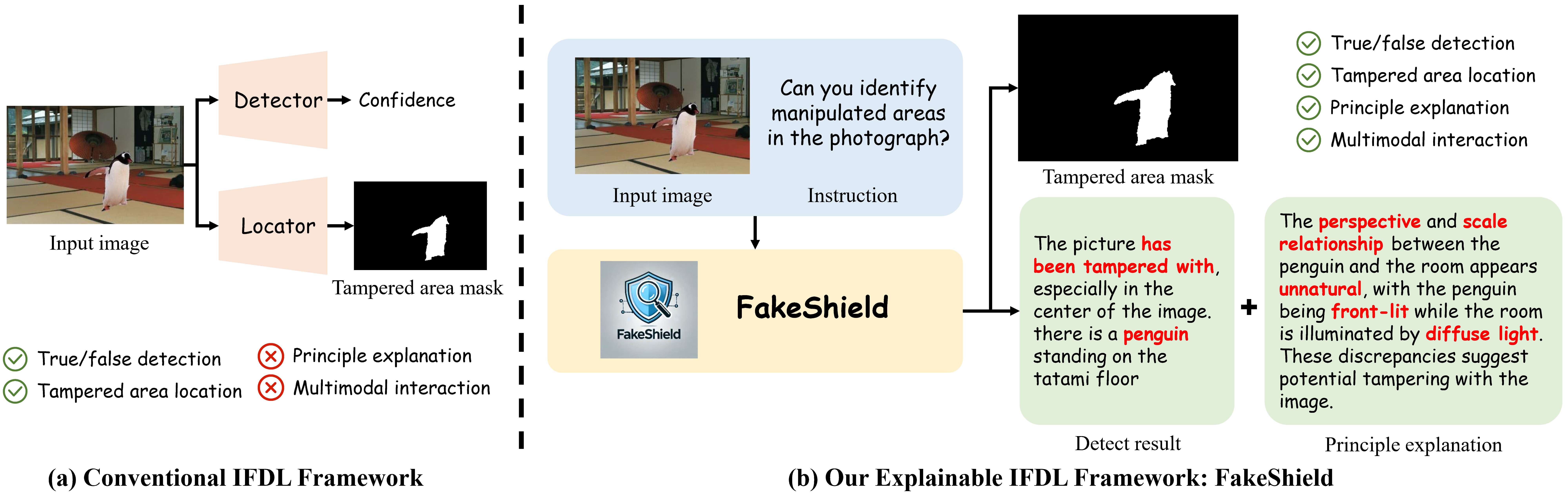
图1:(a)传统IFDL方法,(b)可解释的IFDL方法
MMTD-Set数据集构建:如图2所示,我们根据篡改方法,将篡改图片分为PhotoShop、DeepFake、AIGC-Editing三个数据域。基于现有的IFDL数据集,我们利用GPT-4o生成对于篡改图像的分析与描述,构建“图像-掩膜-描述”三元组,以支持模型的多模态训练。另外,针对不同篡改类型,我们设计了特定的描述提示,引导GPT关注不同的像素伪影和语义错误。
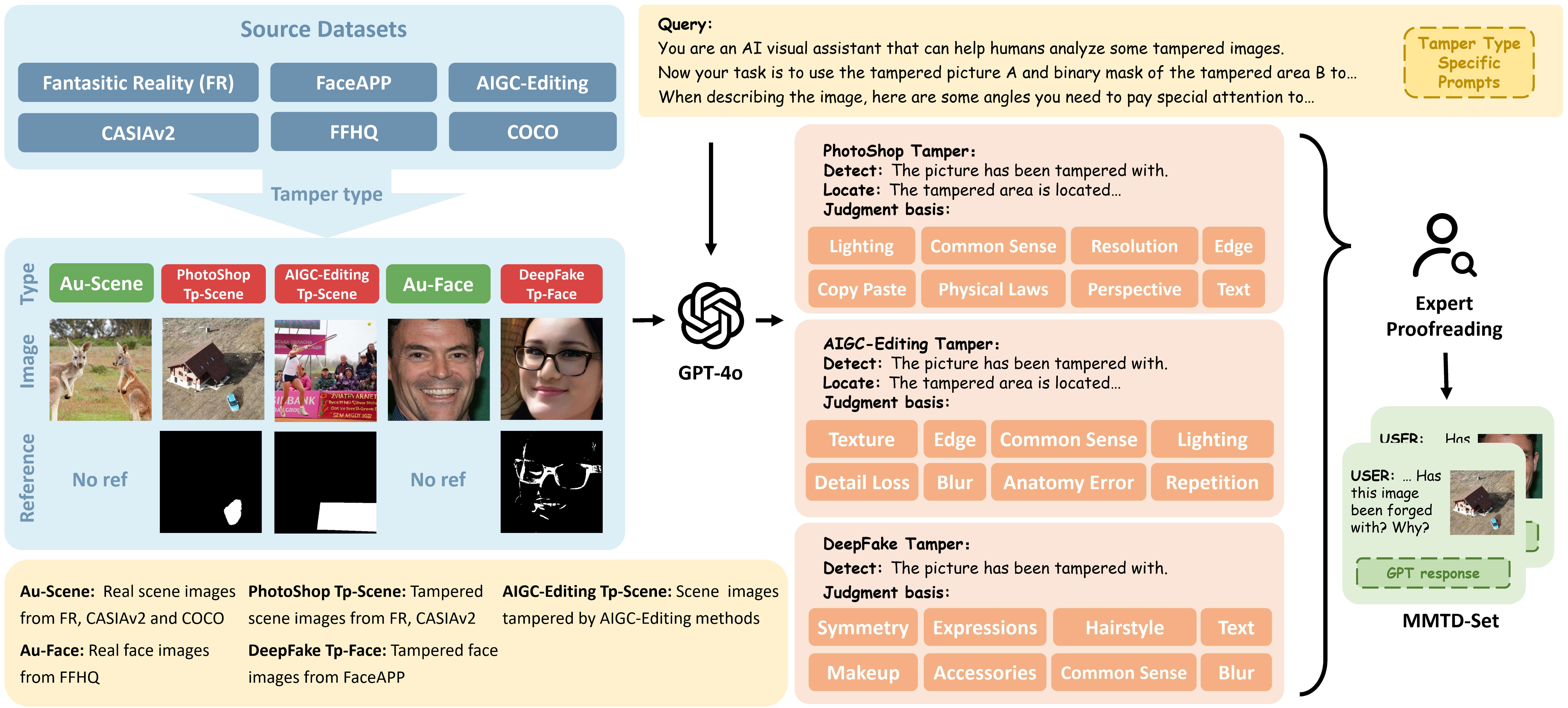
图2:MMTD-Set数据集构建过程
FakeShield框架:如图3所示,该框架包括域标签引导的可解释伪造检测模块(Domain Tag-guided Explainable Forgery Detection Module,DTE-FDM)和多模态伪造定位模块(Multi-modal Forgery Localization Module,MFLM)两个关键部分。DTE-FDM负责图像伪造检测与检测结果分析,利用数据域标签(domain tag)弥合不同伪造类型数据之间的数据域冲突,引导多模态大语言模型生成检测结果及判定依据。MFLM则使用DTE-FDM输出的对于篡改区域的描述作为视觉分割模型的Prompt,引导其精确定位篡改区域。

图3:FakeShield框架图
在实验结果方面,我们从检测,定位,解释三个方面来评价FakeShield的效果,其在多个IFDL测试集中表现出优越性能,定量结果如表1,表2,表3所示,定位性能的定性结果如图4所示。
表1:FakeShield与主流IFDL方法的定位性能比较
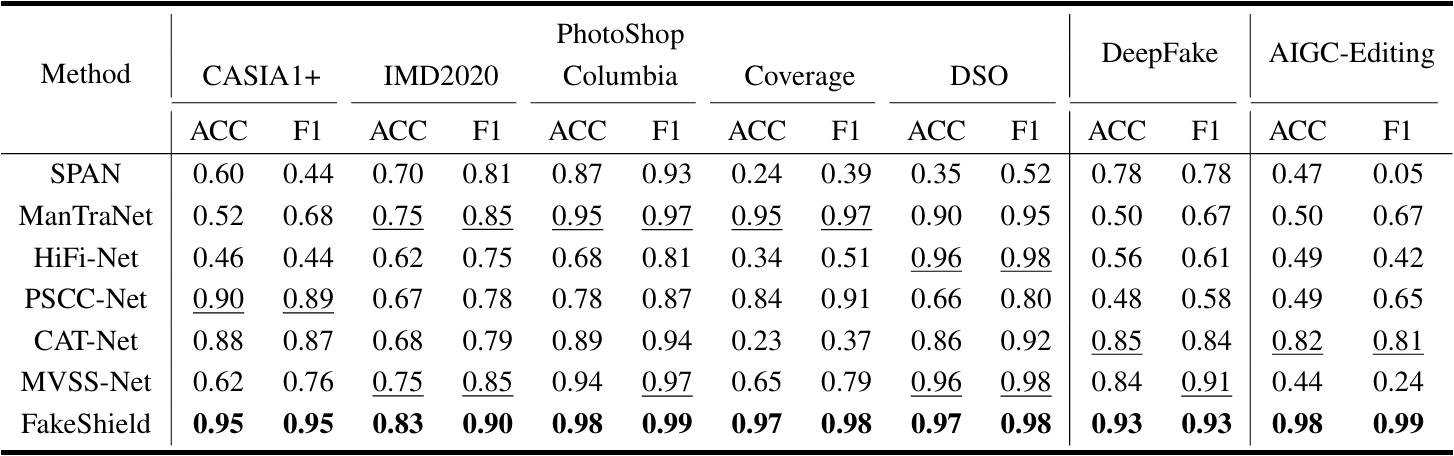
表2:FakeShield与主流通用MLLM方法的解释性能比较
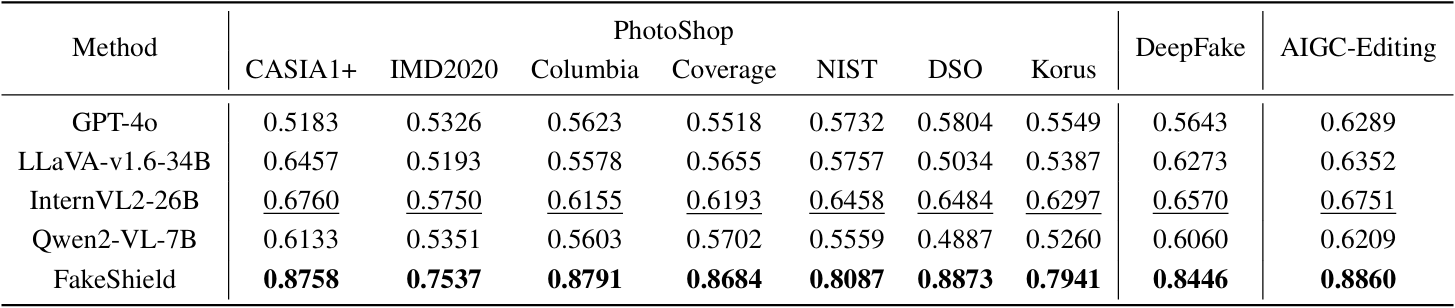
表3:FakeShield与主流IFDL方法的定位性能比较
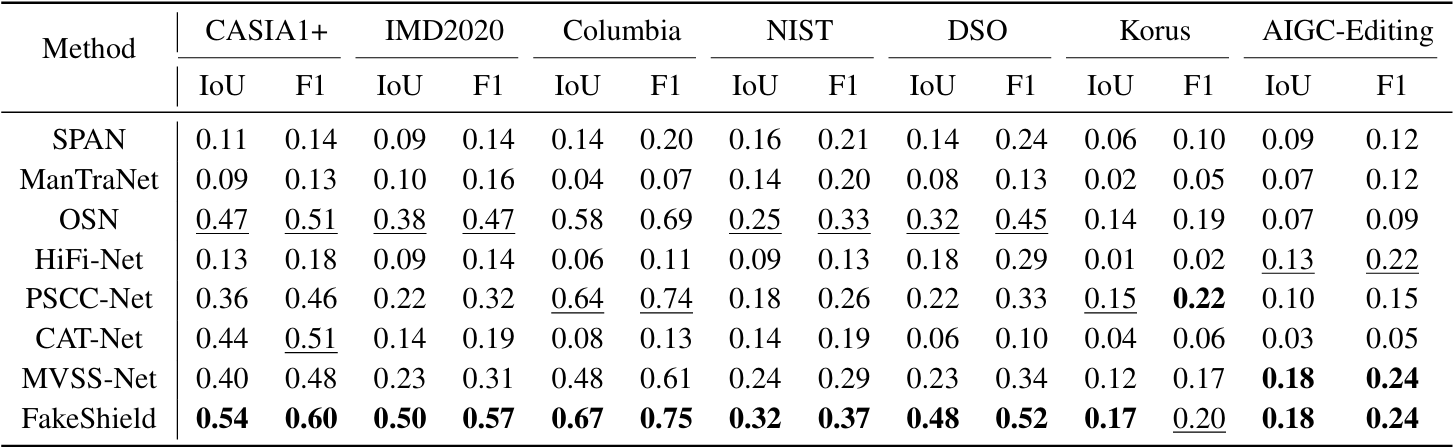

图4:FakeShield与主流IFDL方法的定位性能的定性比较
论文信息
Zhipei Xu, Xuanyu Zhang, Runyi Li, Zecheng Tang, Qing Huang, Jian Zhang*. FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models. arxiv preprint arxiv:2410.02761, 2024. (*张健为通讯作者)
相关链接
arxiv链接:https://arxiv.org/abs/2410.02761
论文网站:https://zhipeixu.github.io/projects/FakeShield/
项目网址:https://github.com/zhipeixu/FakeShield
实验室简介
视觉信息智能学习实验室(VILLA)由张健助理教授于2019年创立并负责,主要围绕“智能可控图像生成”这一前沿领域,深入开展高效图像重建、可控图像生成和精准图像编辑三个关键方向的研究。创立至今已在Nature子刊Communications Engineering、TPAMI、TIP、IJCV、SPM、CVPR、NeurIPS、ICCV、ICLR等高水平国际期刊和会议上发表论文90余篇。
近期工作包括无需GT自监督图像重建SCNet、超低采样率单光子压缩共焦显微成像DCCM、图像条件可控生成模型T2I-Adapter、全景视频生成模型360DVD、拖拽式细粒度图像编辑DragonDiffusion/DiffEditor、精确控制视频内容与运动的编辑ReVideo、面向3DGS动态场景重建与理解HiCoM/OpenGaussian、面向3DGS的隐写框架GS-Hider、面向AIGC内容篡改定位与版权保护的水印技术EditGuard/V2A-Mark等,欢迎关注!
更多信息可访问:
-
VILLA实验室主页(https://villa.jianzhang.tech/)
-
张健助理教授个人主页(https://jianzhang.tech/)



















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











