






最近看了篇非常棒的文章,有点类似去年分享过的 Full Stack LLM Bootcamp[1]。光看作者就是巨星云集,Eugene Yan[2],Charles Frye(Full Stack Deep Learning 讲师之一),Hamel Husain[3],Jason Liu[4] 等人的分享、课程质量都非常之高。这篇文章整体读下来感觉把我过去一年看过的各种 LLM 应用开发相关主题都有所覆盖,有些地方连引用文献都一毛一样。所以我结合自己的一些笔记内容,快速记录了一些文章的核心观点,与大家好文共赏。
原文地址:https://applied-llms.org/
注意这里不是直接做翻译,原文的内容会更加完整。过程中会补充一些个人看法和其它信息。欢迎大家一起留言讨论。
1 战术
1.1 Prompting
一般应用开发都先从 prompt engineering 做起。一些常用的 prompting 技巧:
Few-shot + ICL
-
使用 n-shot 方法时,可以多选几个例子,n >= 5,几十个例子也可以。
-
有时候仅仅是输出格式的例子就足够了。
-
如果想让 LLM 调用工具,也最好给些例子。
CoT
-
让模型先输出思考过程,再给结果。而不是反过来。
-
Let’s think step by step 还不够,可以直接把具体步骤写出来。参考上次分享中 DSPy 中可以借助模型来生成 rationale。
RAG
-
除了给出 context 之外,还要告诉模型记得参考、引用这些例子。
-
我们在实践中也发现,有时候例子的作用是格式示范,而不是提供事实,需要小心区分。
结构化输入和输出
-
在于上下游程序集成时,基本是标准做法。很少会让 LLM 输出非结构化纯文本,除非是非常单一的撰写任务。
-
作者推荐的工具:当使用 LLM API SDK 时,用 instructor[5],使用 HuggingFace 来自托管模型时,使用 outlines[6]。
-
不同模型对于结构化语言有不同偏好,GPT 喜欢 Markdown 和 JSON,而 Claude 喜欢 XML(奇特的品味……)。甚至可以在调用 Claude 时提前把 tag 写好:
messages = [
{
"role": "user",
"content": """Extract the <name>, <size>, <price>, and <color> from this product description into your <response>.
<description>The SmartHome Mini is a compact smart home assistant available in black or white for only $49.99. At just 5 inches wide, it lets you control lights, thermostats, and other connected devices via voice or app—no matter where you place it in your home. This affordable little hub brings convenient hands-free control to your smart devices.
</description>"""
},
{
"role": "assistant",
"content": "<response><name>"
}
]
只做一件事
-
软件工程中强调单一职责原则,作者认为在 LLM 中每个 prompt 最好也能专注于一件事。个人感觉这里也还是需要靠经验来判断下。
-
GoDaddy 的分享[7] 中提到,大型的复杂的 prompt 用来处理模糊的对话理解并做任务分发(controller),小型的 prompt 则专注于完成某个具体的任务。
精心雕琢
-
作者建议像米开朗基罗那样,要雕琢每一个 prompt,去掉不必要的部分。我们在实践中也常常会回过头去精简 prompt,少一些输入 token 速度也能快一些……
-
把最终 prompt 放在空白页上仔细阅读是一种好办法。好的 prompt engineer 应该经常读读 prompt 记录(因为很多是动态构建出来的)。
-
其它的 prompting 基础技巧合集[8]。
1.2 RAG
RAG 实践
-
检索到内容的排序影响挺大的,可以实验下把内容顺序随机打乱看看对 RAG 最终输出影响有多大。
-
信息密度,详细程度也很重要。作者这里又举了 text-to-sql 的例子,看来这个场景很热门呀。
-
关键词检索很有用!Perplexity,Sourcegraph 的大佬都建议从传统的 BM25 这类检索方法开始。当然现在应该主流会是混合搜索,因为向量搜索也有其自身优势。
-
shortwave 的这个案例分享[9] 也很精彩。通过不同的工具调用路由到不同的知识库搜索。而且搜索过程也非常细致,结构化过滤条件(类似 self-query),关键词提取与检索,向量检索,业务规则,重排序等,跟我们的做法很类似。
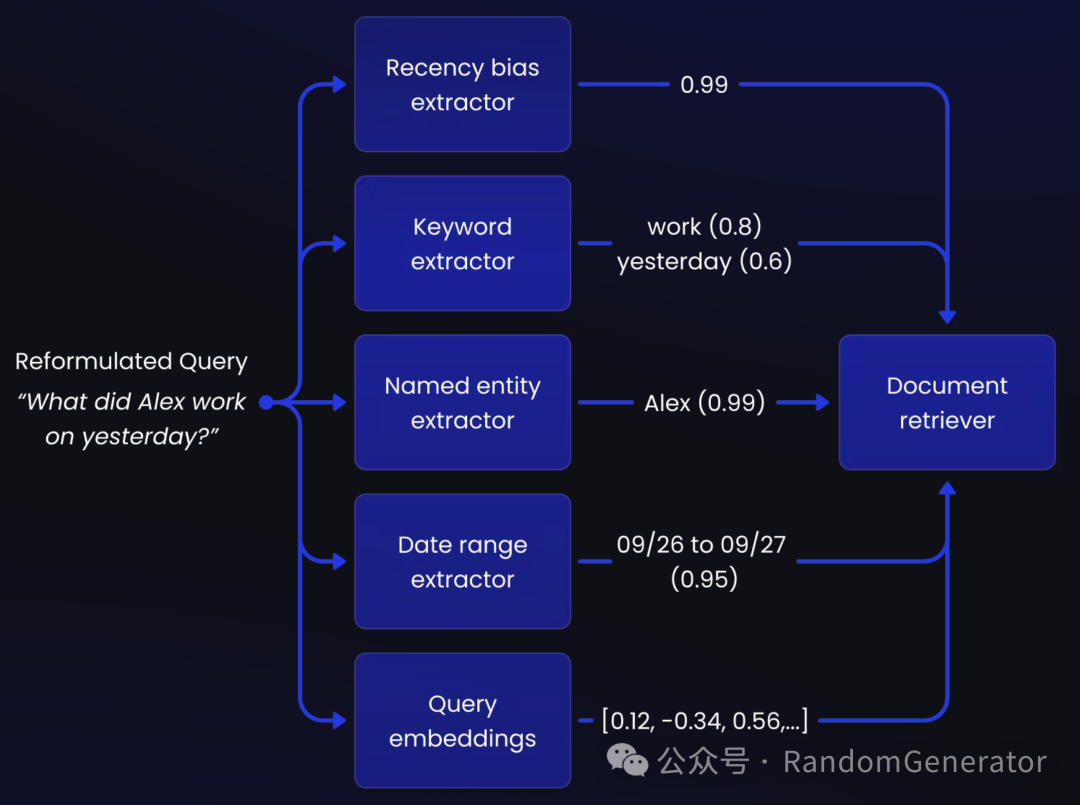
召回策略演示
与 fine-tune 对比
-
在引入新知识时,RAG 的效果往往比 fine-tune 好,OpenAI DevDay 上也分享了类似的观点,有两个研究也得出了类似的观点:研究 1[10],研究 2[11]。目前还没看到 fine-tune 能明显超过 RAG 的案例。
-
RAG 的可控性更强,包括针对检索数据源做权限控制,去除有问题的数据来源,保持实时更新等。
跟 long-context 模型的关系
-
某些场景下 long-context 的确比 RAG 有优势,比如做总结,多跳问答等复杂场景。
-
在 long-context 场景下如何证明模型的推理能力?这与上面提到的单一职责原则会有些冲突。
-
成本也是个问题,即使现在“内存”已经很大了,我们仍然离不开“硬盘”。
1.3 工作流优化
优先考虑确定性的 workflow
-
将复杂任务“分而治之”能大大提升最终结果的准确率。每个任务足够聚焦,然后通过结构化输出来便于做串联。
-
一些可以尝试的 pattern:
-
人工指定的计划步骤,也可以提供预定义计划模板来选择。
-
重写用户问题作为 agent 输入 prompt。
-
任务串联方式包括典型的 chains,DAG 和状态机(如 LangGraph)。
-
对计划进行验证。
-
优先采取确定性的 workflow。目前看让一群 agent“自由发挥”几乎无法达到可用性。
-
开发 agent workflow 比较厉害的人可能是那些有初级工程师管理经验的人,大家玩 CrewAI 应该也有这个感觉。
-
收集更多的流程数据,来优化 prompt 和 fine-tune 模型也很重要。
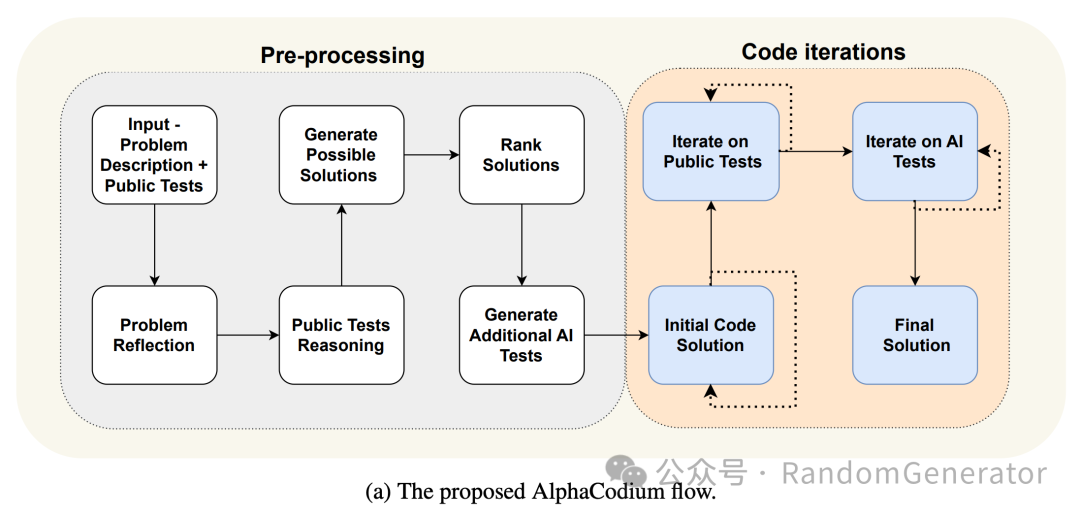
AlphaCodium 的 workflow
回复多样性
-
调整温度。
-
调整 prompt 中元素的顺序(如 few-shot examples 等)。
-
调整不同的 prompt 表达方式,例如让 LLM 回复中不要重复最近的输出。
缓存被低估了
-
根据业务场景来设计缓存策略,比如已经总结过的文章可以直接输出缓存。
-
用户输入时,提供自动完成、搜索建议等功能,可以提升缓存命中率。
何时进行 fine-tune
-
如果 prompting 做得很复杂仍然无法满足,可以尝试 fine-tune。尤其是让模型学习一些新的领域语言,以特定的风格进行回复的场景。
-
成功案例包括,Honeycomb[12] 通过 fine-tune 模型,更好地输出特定的语法和 DSL。Rechat 的 Lucy[13],需要 LLM 输出结构化与非结构化数据的结合,以便前端进行渲染。
-
有种很常见的做法是从比较强大模型(例如 GPT-4)中生成的内容作为训练数据来 fine-tune 一个相对较小的模型,可以参考这篇文章介绍 如何利用“合成数据”进行模型训练[14]。甚至可以 找一些并非领域直接相关的开源数据[15] 来帮助进行微调。
-
Fine-tune 时不一定只盯着可以私有化部署的小模型,也可以考虑 GPT-3.5 这种大模型,例如 Perplexity 和 CaseText 就做过这方面的尝试。
1.4 评估与监控
-
LLM 的评估很难,Jason Wei 在推特上透露,一些 OpenAI 的 manager 也会花时间来搞模型评估相关的具体工作[16]。Anthropic 也 系统性解释过 evaluation 的困难[17]。
-
应该针对 LLM 应用构建测试体系,作出各种 prompt,RAG,workflow 等方面的变动时都应该运行测试以保障变化符合预期。
-
类比软件工程中的单元测试,集成测试,端到端测试的金字塔,LLM 测试也可以考虑分级。比如数量最多,运行最频繁的也是单元测试(确定性评估),然后中间是依赖模型或者人工评估的测试,最后是真实部署中的 A/B 测试。成本不断提高,因此执行频率不断降低。
-
永远不要停止亲自查看 tracing 数据。
-
高质量的测试有助于 debugging 和收集高质量的数据。
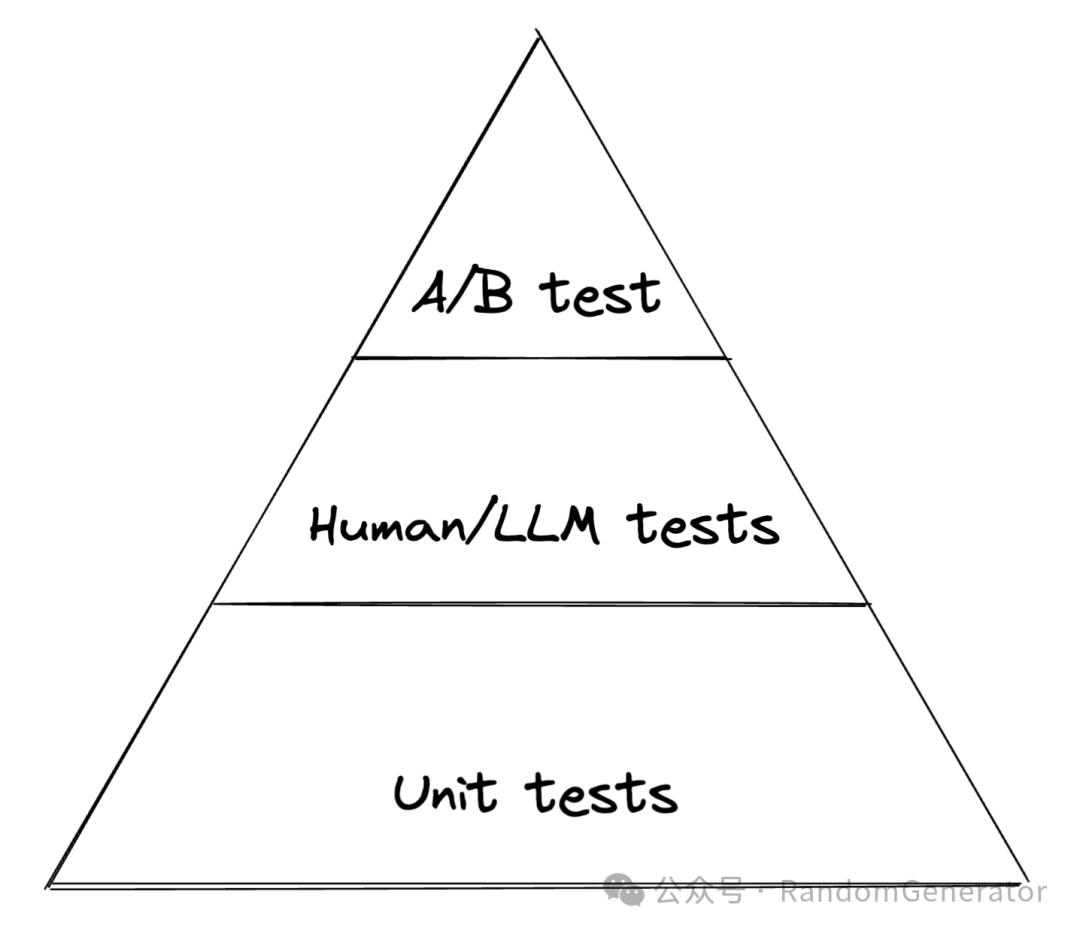
LLM 应用的“测试金字塔”
用 LLM 来做评估
-
LLM 不善于打分,所以最好把评估做成对比选项的形式,比如 A 和 B 哪个更好?
-
控制偏差。模型也会学到“不会就选 C”这样的统计规律,所以评估时可以改变顺序多做一次。
-
允许平局的情况。
-
可以加上 CoT 提升评估效果。
-
LLM 偏好更长的内容,所以对比时两者长度最好接近。
-
过程中可以反复与人类评估结果进行“校准”,迭代 prompt。
-
可以考虑 fine-tune 一个模型来做 evaluation。
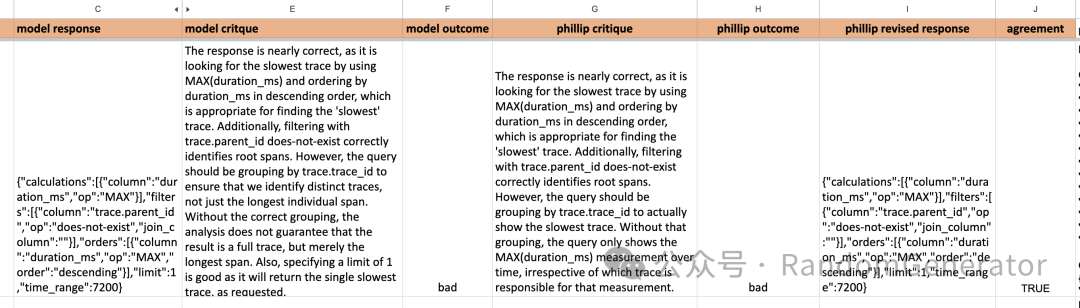
模型与人类“校准”
“实习生测试”
-
如果将 prompt 内容交给一个刚大学毕业的实习生,他/她能完成任务吗?需要多长时间?
-
无法完成可能代表 prompt 不够完善,任务太难。时间太长可能表面我们需要拆解这个 prompt 到更小的子任务。
-
让模型给出解释可以帮助做误差分析。
过度强调某些评估会带来危害
-
当前的大海捞针测试设计有些片面,更多在考察模型“死记硬背”甚至是关注不相干细节的能力,而不像真实场景那样需要在 long-context 中做理解和推理。Observable 做了一个 更接近真实场景的大海捞针测试[18]。
-
其它评估也有类似风险。例如在总结场景中,过度强调事实性可能导致回复的内容不具体/不相关,而强调写作风格可能导致事实性问题。
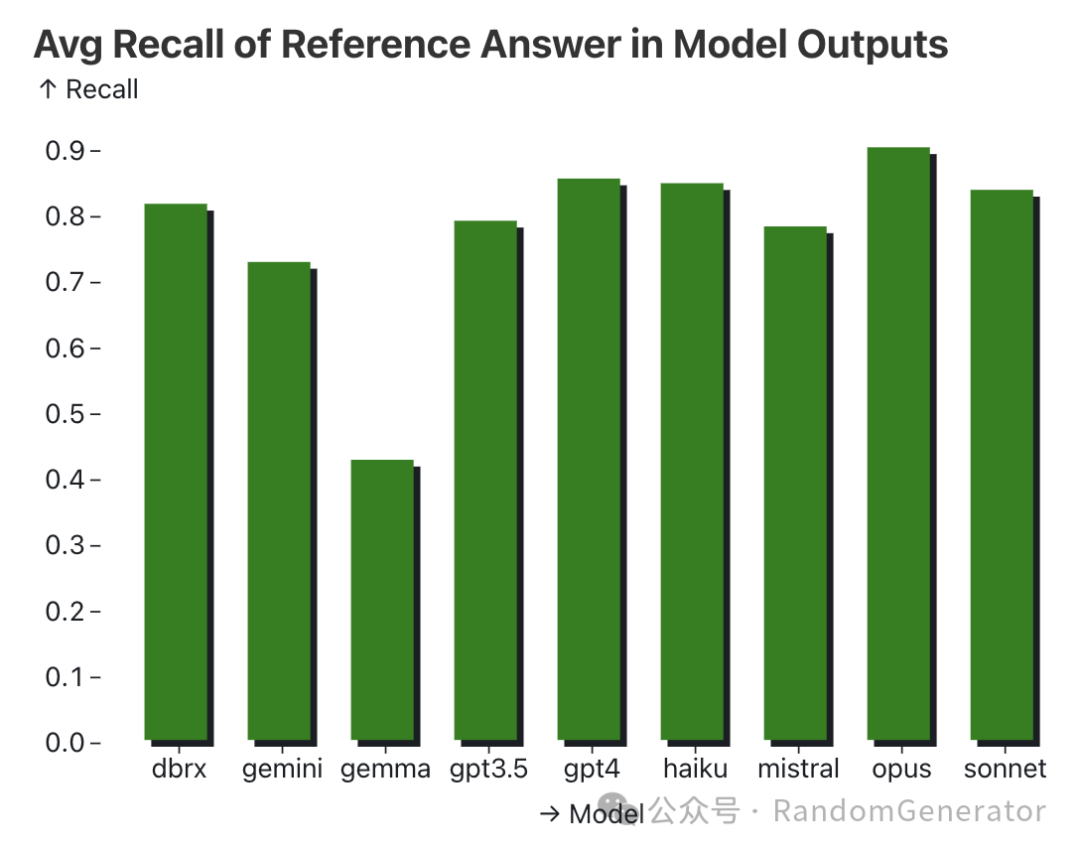
基于病人与医生对话记录制作的大海捞针测试
二元任务的打标简化
-
Doordash 的例子[19] 中构建了一棵是非问题树。
-
收集成对比较的人工打标数据每单位成本为 3.5 美元,人工写回复的成本则为 25 美元。来源[20]
-
怎么写打标指导[21] 也很有学问……Google 的打标指导文档足足有 160 多页。
与“护栏”的关系
-
如果你的 eval 不依赖“参考答案”,那么它也可以被用作“护栏”。可以参考 这篇文章里提到的各种 eval 方法[22]。
-
提示 LLM 不知道的时候返回“N/A”,“unknown”的这种方法只是代表了 log probs 的输出,而不一定代表模型的真实情况。还是需要在应用中根据情况加入各种检查机制。
-
目前大模型发生幻觉的 baseline 概率大概是 5%到 10%,要降到 2%以下很困难。主要通过 prompting 优化,事实性检查护栏来降低这个概率。
2 运营
2.1 数据
-
就跟传统的机器学习工程师一样,LLM 应用工程师需要持续关注模型的输入和输出数据情况。每周花几个小时肉眼去看就是个很好的开始,甚至是不可替代的。
-
各种 MLOps 领域的数据漂移检测方法也都可以借鉴,例如可以借助模型来做数据的无监督聚类,或者构建有监督模型来“预测”两组数据的标签(dev vs. prod,过去 vs. 现在),挖掘是否产生漂移和背后的原因。如 ft-drift[23] 这个项目,通过训练一个模型来做二分类,找出 training 和 serving 两部分数据中是否有数据漂移问题。
-
由于 LLM 本身输入输出的复杂性,我们需要思考一些特定的检查,例如对格式和内容分别检查,对 LLM 输出确定性的检查,甚至包括各种评估标准的持续迭代。

经典的数据漂移探测方法
2.2 使用模型
结构化输出
-
当前大模型典型的应用原则:在接收的内容上保持自由(可以是任意形式的文本),在输出的内容上保持保守(结构化,机器可读的)。
-
结构化输出的“事实标准”:如果使用 LLM API,选择 instructor;如果使用自托管模型,选择 outlines。
跨模型迁移
-
不同模型版本之间的表现差异可能也会很大。默认应该固定模型版本,在升级版本时进行深入的评估并对影响做相应修改,如 Voiceflow 分享的案例[24]。
-
构建可靠的自动化评估流程。
-
使用 shadow pipeline,灰度发布等方法来评估线上影响。
选择能完成工作的最小模型
-
可以使用最强的模型验证技术可行性,后续尝试较小的模型能否达到类似效果。
-
小模型的延迟和成本都更低,能力上的弱点或许可以通过 CoT,few-shot,ensemble 等方法来弥补。例如有人分享了 Haiku 上使用 10 个左右样例就能打败 Opus 的 zero-shot 表现[25]。
-
甚至可以考虑一些更小的模型,如 T5,DistilBART 等。
2.3 产品
UX 设计的重要性
-
尽早引入设计师,并保持沟通合作。如果有 AI 产品,chatbot 相关经验的就更好了。之前我们也分享过 Midjourney,Github Copilot,Perplexity 等产品设计上的出色之处,对于用户体验的保障和产品获得成功至关重要。
-
一些 AI 产品的设计 patterns[26],例如复用软件中已有的输入框,斜杠唤出命令,将常见的 prompt 转化为按钮或选项,提供使用建议,重写用户问题,可以对 context 内容作出选择,使用户能够轻松完成校验和检查等。
-
设计 human-in-the-loop 的交互体验,不但对用户友好,更重要的是可以获得高质量的反馈数据。这是一个核心问题。
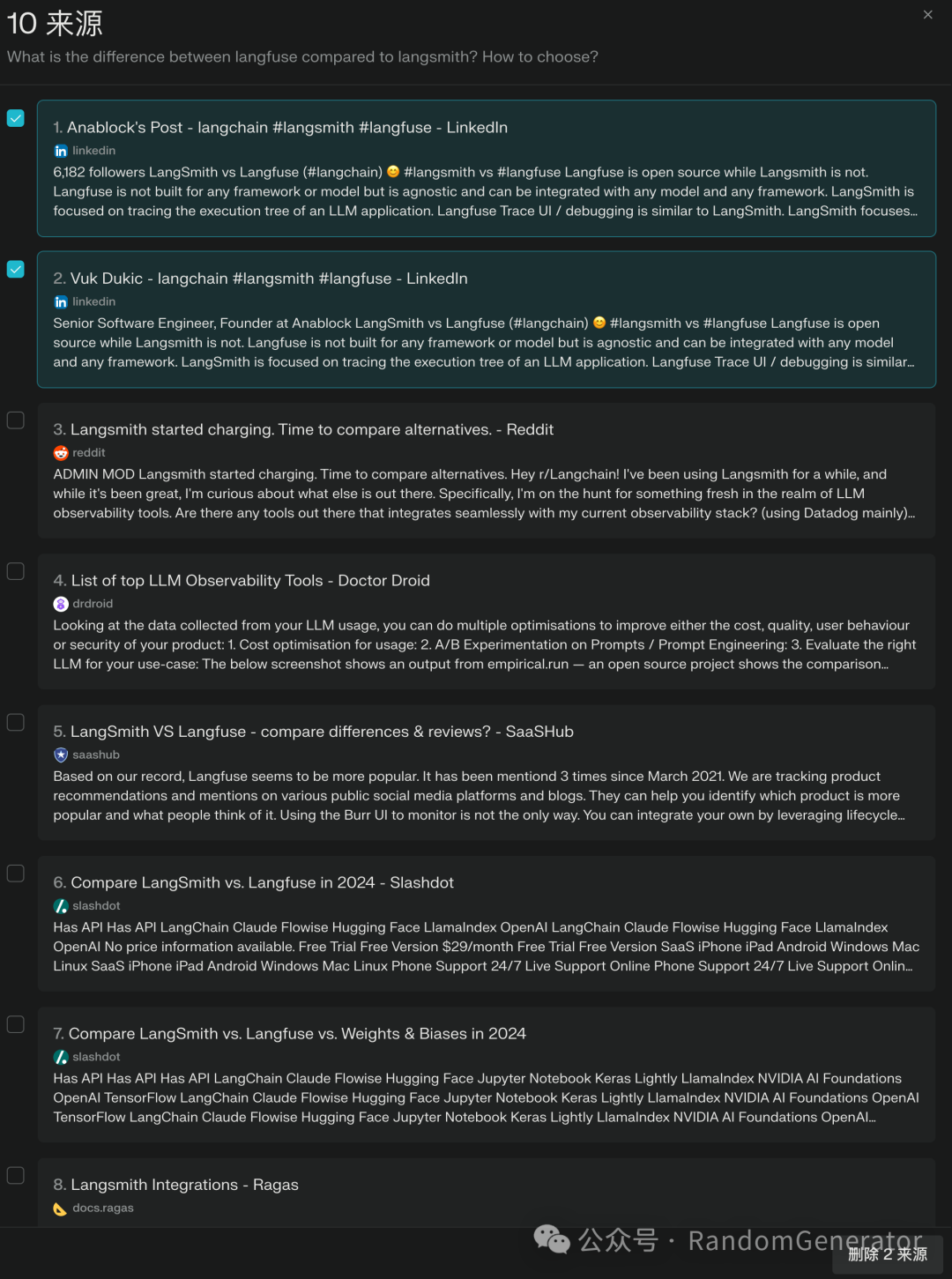
Perplexity 中支持的 context 控制
需求层次优先级
-
当我们开始考虑将 demo 产品逐渐投入生产时,会遇到一系列需求,包括:可靠性,无害性,事实一致性,实用性,可扩展性,成本,延迟,安全,隐私等。我们不可能同时满足这些要求,因此必须要思考和设定优先级。
-
不同使用场景的优先级肯定是不一样的,比如用在医疗领域和用在普通的推荐系统。如果担心风险,可以优先考虑面向企业内部应用的产品,接受度会更高。
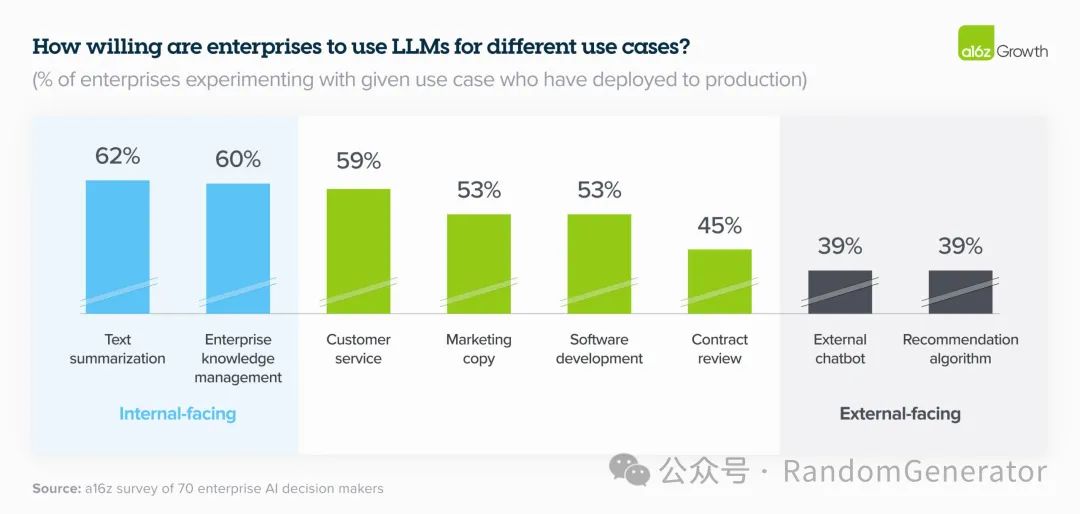
企业内部 LLM 应用接受度更高
2.4 团队和角色
LLM 应用的兴起带来了一些新的岗位角色需求,从早期的 prompt engineer 到后来的 AI engineer,作者在这部分讨论了相关的角色和职责分工。
关注过程而不是工具
-
目前有很多 LLM 应用的开发工具和框架,在这篇文章中,作者 讨论了 Guardrails, Guidance, LangChain, Instructor, DSPy 等相关工具[27],他认为如果你没有深入了解解决相关问题的方法和流程,那么这些工具反而会带来不必要的技术债务。
-
更好的做法是像 Who Validates the Validators?[28] 这篇文章中那样,指导用户整个流程的最佳实践。当用户理解其背后的工作方式后,可以自由选择或打造相关的工具来进行开发。
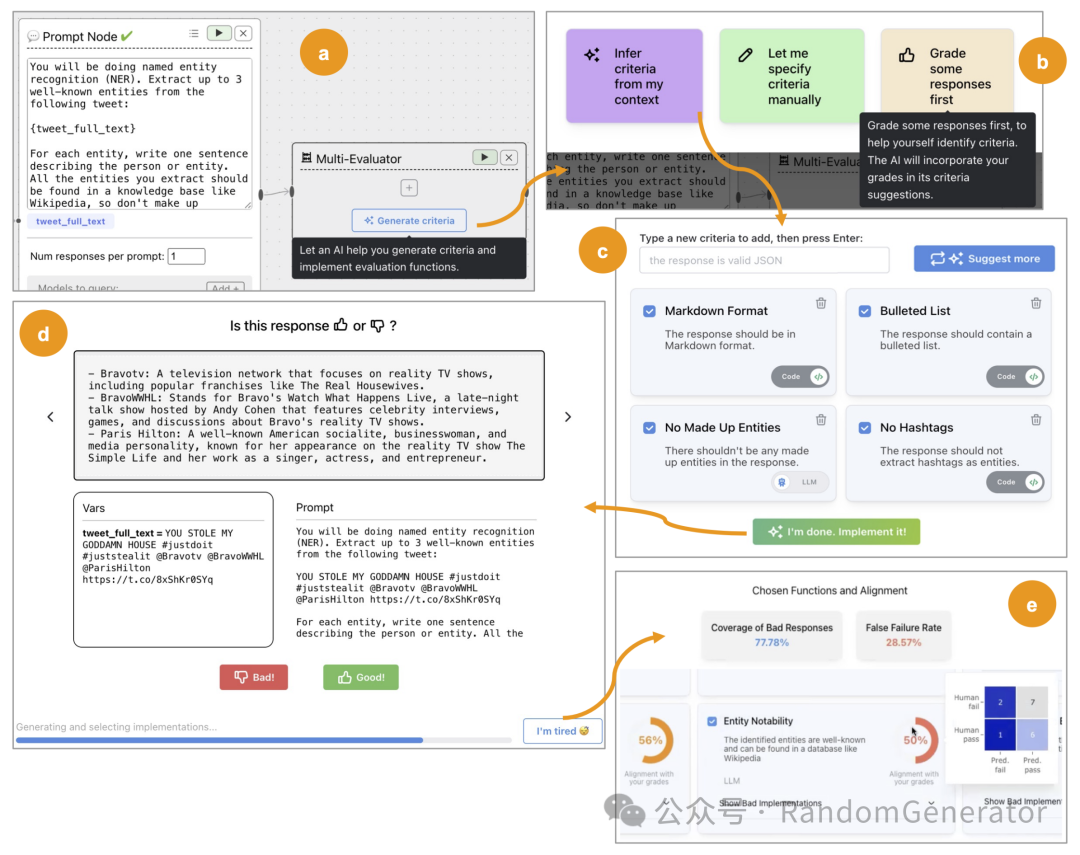
EvalGen 中的 LLM 评估最佳实践
不断尝试
-
机器学习类产品与普通软件产品不同,它天生具有不确定性,需要大量的实验和迭代,所以文中也反复提到了 evaluation 的重要性。
-
相比之前的机器学习来说,基于 LLM 来做实验门槛更低了。只要学习一下 prompting 技术,每个人都可以自己做尝试。
-
产品和项目 planning 阶段不要低估实验所需投入的时间和资源。哪怕初步看起来一个 prompt 就可以解决的问题,实际场景中都可能有千奇百怪的 case 需要处理。
-
培养企业内各种人员都能够理解和尝试 LLM 技术。比如可以做基础的原理科普,prompting 技术培训,以及举办 Hackathon 等。
光有 AI Engineer 是不够的
-
类比当年的经典文章 Hidden Technical Debt in Machine Learning Systems[29],机器学习系统中,ML code 只占了很小的一部分。
-
早期产品打造、原型验证阶段,AI engineer 可能会比较重要。
-
随着逐渐走向生产环境,你需要系统检测,数据收集等工作,这时候可能需要引入平台工程师,数据工程师等角色。
-
后续不断优化 AI 系统过程中,可能需要做模型训练优化,RAG 检索优化等工作,这时候可能需要引入 ML engineer。但要注意不要过早引入这个角色。
-
领域专家,产品经理和设计师等角色需要贯穿始终。
3 战略
3.1 No GPUs before PMF
简单的 API“套壳”产品是不够的,但一上来就买很多卡也是一种典型的战略错误(注意本文说的都是 LLM 应用产品)。
从头开始训练几乎没有意义
-
BloombergGPT[30],通过 9 名全职员工在 363B tokens 上训练的“领域大模型”,但在 半年内其任务表现就已经被 GPT-3.5 超过了[31]。像 llama3 这样的开源模型迭代速度,可能也基本达到了很多深入做 pre-train 的闭源大模型公司的水平。如果每 6 个月辛苦训练出来的模型都会被新一代模型能力“淹没”,这样持续的人力算力投入对大多数公司来说无法负担。
-
当然也有例外,例如 Replit 的 code 模型[32],针对代码领域做训练,模型规格能保持在比较小的水平,并超越像 CodeLlama 7B 这样更大的模型。
只在有绝对必要的情况下做 fine-tune
-
作者认为很多团队做 fine-tune 是 FOMO 驱动,而不是清晰的战略思维驱动的。
-
大多数一开始做了 fine-tune 的团队,都没有找到 PMF,且后悔当初的决定。
-
思考一个问题:如果大模型供应商无法轻松获取大量的数据(他们可是雇佣了很多人来专门做打标的),那么你的团队是如何获取这方面的数据的?
从使用 API 开始,但也不必害怕自托管
-
使用 API 快速构建产品验证价值。
-
医疗保险、金融等受监管行业可能必须进行自托管部署。
-
自托管和 fine-tune 的优势包括更好的数据隐私,自主控制权,减少速率限制,降低成本[33] 等。
3.2 迭代出伟大的产品
模型本身不是产品
-
模型的本身演进非常快,更好的推理能力,更长的 context,更快的速度和更低的价格。这表明模型可能是整个系统中“最不耐用”的组件。
-
集中精力在提供持久价值的事情上,如 evaluation,模型护栏,缓存,构建数据飞轮等。
-
要小心思考模型供应商会着手解决的问题,例如结构化输出能力(OAI 的 json mode)。这里可以采取一些“战略性拖延”。
从小事做起建立信任
- 即使是 RAG 这种相对成熟的用例,也需要深入一个小的垂直领域,打造最好的产品体验以建立信任。
LLMOps
-
DevOps 的核心是缩短从代码提交到反馈获取的时间,以便促进改进的累积而不是错误的累积。
-
LLMOps 也是类似,通过 evaluation 来连接线上监控与持续开发改进。
-
这方面的产品很多,包括 LangSmith, Log10, LangFuse, W&B Weave, HoneyHive 等等。
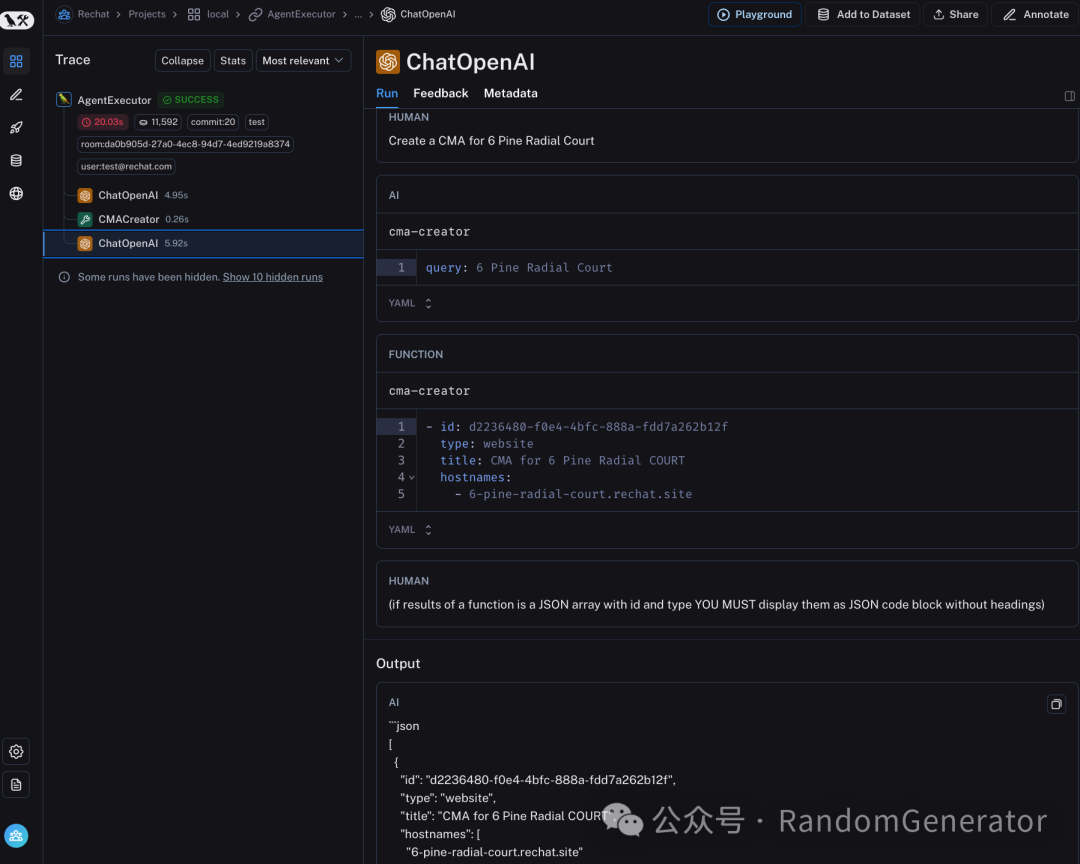
LangSmith 产品截图
Build vs. Buy
-
不要构建一些通用的 LLM 功能。作者举例包括:text-to-SQL,chat with documents,将公司知识库与客服机器人集成等。
-
个人理解这里的意思是要看自己产品的核心功能是什么。比如 Notion 中增加 chat with notes 的功能就比较合理,但如果我们只是 Notion 的用户,就没有必要去开发 chat with Notion 的功能。
AI-in-the-loop,人类还是中心
-
目前的 LLM 应用产品都还非常脆弱,需要各种护栏,但仍然具有很大的不确定性。所以像 Github Copilot 那样以人类为中心的运作模式还是成功产品的绝对主流。
-
从这个角度出发能设计出更好,更有用,低风险的产品。
3.3 从提示、评估和数据收集开始
如果想构建一个 LLM 应用产品,推荐的路线图应该是怎么样的?
从 prompt 开始
-
先从最强的模型+prompt 开始做 demo 验证。只有 prompt 无法满足时再考虑 fine-tune。
-
Fine-tune 还能满足很多非功能性需求,如数据隐私、完全控制、成本等。但要注意同样的隐私条款不会阻碍你使用用户数据来 fine-tune。
构建评估,启动数据飞轮
-
再次强调 evaluation 的重要性,从一开始就要着手构建。这是战略投资,而不仅仅是运营成本。
-
公开榜单、指标等只能作为参考,真正有效的评估还是需要根据自己的产品场景来设计。
-
通过有效地收集真实用户反馈来构建数据飞轮。逻辑上比较直观,人工评估模型效果/发现缺陷 -> 用打标过的数据来改进 prompt 或 fine-tune 模型 -> 不断重复。但这个飞轮的效率高低还是非常取决于巧妙的设计的,默认的点赞点踩的方式很难收集到大量高质量信息。
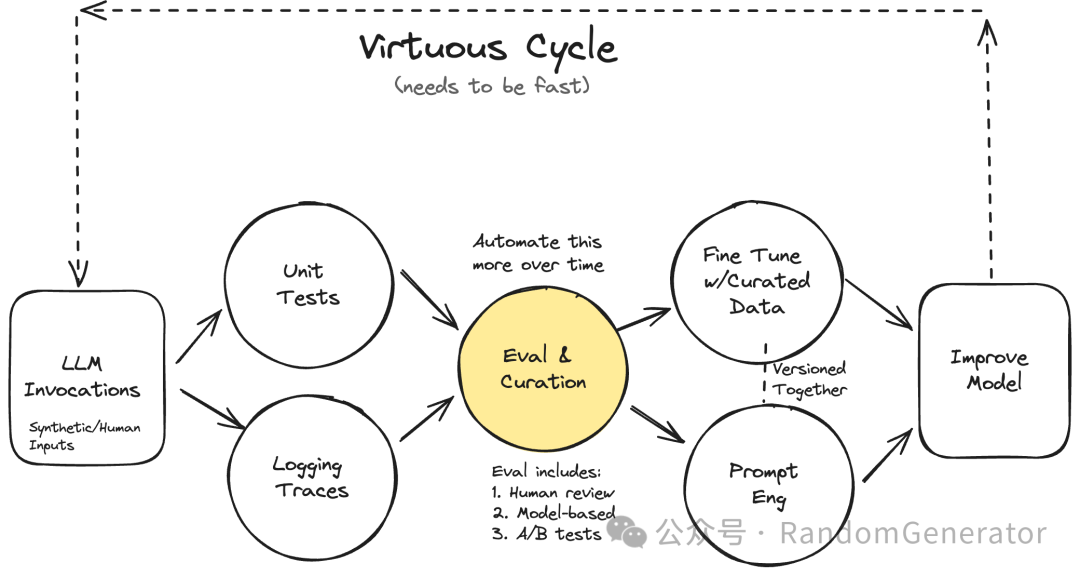
LLM 应用数据飞轮的一种阐述
3.4 低成本认知的趋势
-
从 OpenAI 的 davinci 模型推出到现在的 4 年里,同等能力模型每百万 tokens 的成本已经从 20 美元降低至不到 10 美分。另一个例子是 text-davinci-003 跟当前的 LLaMA3 8B 模型的能力接近,但成本也从 22 年 11 月的每百万 tokens 20 美元降低到 24 年 5 月的 20 美分。差不多是 18 个月 100 倍的差距,而摩尔定律只是每 18 个月 2 倍。
-
如果保持这个趋势发展,那么我们有理由相信,当前完全无法实现,或者开销巨大的应用,可能不久之后就会成为日常。我们在构建我们的系统和组织时,应该考虑到这个趋势。
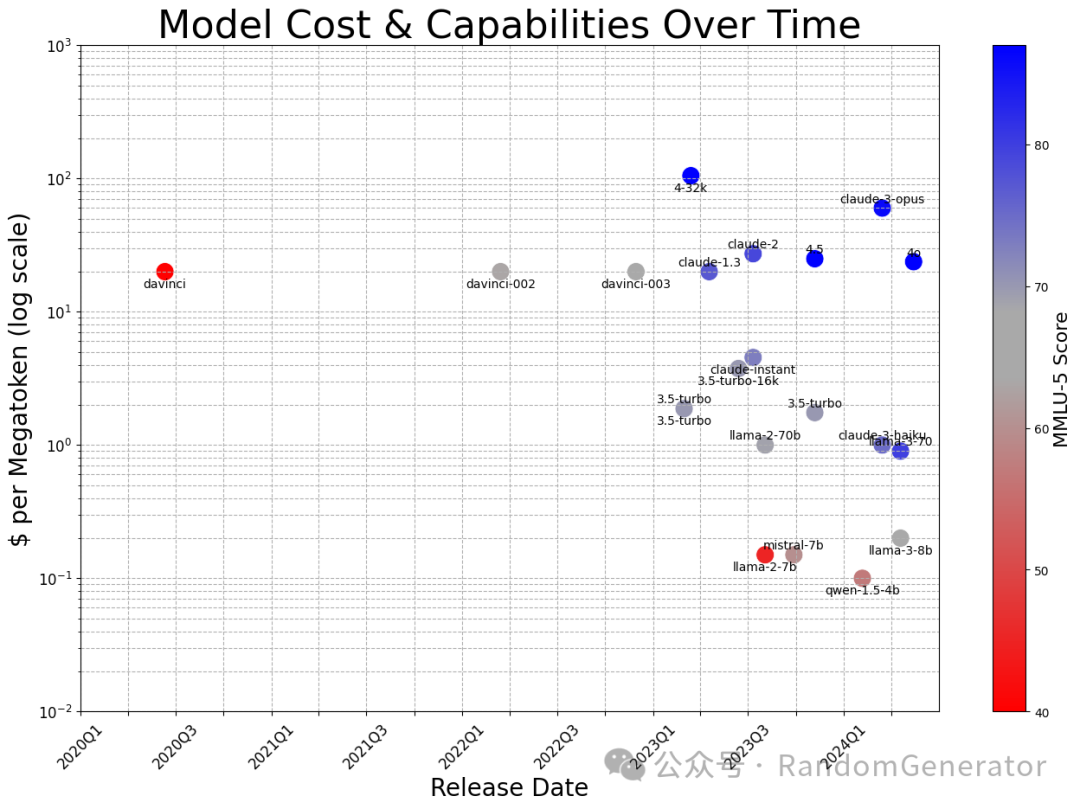
模型价格、能力的变化趋势
4 期待从 1 到 N 的 LLM 应用
作者举自动驾驶的例子,1988 年第一辆车由神经网络来驾驶[34],但直到 25 年后 Andrej Karpathy 才第一次在 Waymo 上体验 demo 自动驾驶。再过了 10 年,这家公司才获得了正式的无人驾驶许可证。
LLM 的应用落地需要多久呢?这需要我们从业者给出答案了 😃
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









