










24年4月复旦大学的论文“From Persona to Personalization: A Survey on Role-Playing Language Agents”。
大语言模型 (LLM) 的最新进展极大地促进角色扮演语言智体(RPLA) 的兴起,即旨在模拟指定角色的专门AI系统。 通过利用LLM的多种高级能力,包括情境学习、指令遵循和社交智能,RPLA 实现了卓越的人类相似感和生动的角色扮演性能。 RPLA 可以模仿各种角色,从历史人物、虚构人物到现实生活中的个人。 因此,它们催生了许多AI应用,例如情感伴侣、互动视频游戏、个性化助理和copilot以及数字克隆。
本综述对该领域进行了全面的调查,阐述了 RPLA 与前沿LLM技术相结合的演变和最新进展。 将角色分为三种类型:1)人口统计角色,利用统计刻板印象; 2)人物角色,重点关注知名人物; 3) 个性化角色,通过持续的用户交互进行定制以提供个性化服务。 全文首先全面概述当前 RPLA 的方法,然后详细介绍每种角色类型,涵盖相应的数据源、智体构建和评估。 然后,讨论 RPLA 的基本风险、现有局限性和未来前景。 此外,还对AI应用中的 RPLA 进行了简要回顾,这反映了塑造和推动 RPLA 研究的实际用户需求。
如图所示RPLA 的各种角色类型概述。 角色的三种类型:1)人口统计角色,2)人物角色,3)个性化角色。 图中展示它们的定义、数据源、示例、用例和相应的应用程序。

AI界长期以来一直追求“智体”的概念,接近人类的智能和自主性。 传统的符号智体(Bernstein,2001;Küngas,2004)和强化学习智体(Fachantidis,2017;Florensa,2018)主要根据规则或预先定义的奖励来优化其行为。 语言智体的研究主要集中在知识有限的受限环境中训练,这与人类学习过程的复杂性和多样性不同。 然而,此类智体很难模仿复杂的类人行为,特别是在开放域环境中(Mnih,2015;Lillicrap,2015;Schulman,2017;Haarnoja,2017)。 最近,LLM在实现人类水平的智能方面表现出了非凡的能力和巨大的潜力,这引发了针对基于LLM的语言智体研究兴起(Sclar,2023;Chalamalasetti,2023;Liu,2023d;Xie,2024a)。 该领域的研究主要涉及为LLM配备必要的类人能力,例如规划、工具使用和记忆(Weng,2023),这对于开发具有拟人认知和能力的高级 RPLA 至关重要。
规划模块。在许多现实场景中,智体需要制定长期规划来解决复杂的任务(Rana et al., 2023; Yuan et al., 2023)。 当面对这些任务时,LLM驱动的智体可以将复杂的任务分解为子任务,并采用各种规划策略,例如CoT(Wei,2022b)和ReAct(Yao,2023b),自适应地规划下一个任务环境反馈的行动(Wang et al., 2023a;Gotts et al., 2003;Wang et al., 2023j;Song et al., 2023;Zhang et al., 2024b)。 对于 RPLA,这些自适应规划策略使它们能够模拟复杂环境中的现实和动态交互,例如游戏(Wang,2023a)和社交模拟(Park,2023)。
工具使用模块。尽管LLM在各种任务中表现出色,但可能在需要广泛专业知识和经历幻觉问题的领域遇到困难(Gou,2023;Chen,2023e;Wang,2023f)。 为了应对这些挑战,智体可以应用外部工具来执行行动(Shen et al., 2023b; Lu et al., 2023; Schick et al., 2023; Parisi et al., 2022; Yang et al., 2023b; Yuan,2024a)。 这些工具包括现实世界的 API(Patil,2023;Li,2023g;Qin,2023;Xu,2023b;Shen,2023c)、知识库(Zhuang,2024; Hsieh et al., 2023)、外部模型 (Bran et al., 2023; Ruan et al., 2023) 以及针对特定应用的定制操作 (Wang et al., 2023a; Zhu et al., 2023b) )。 对于 RPLA,这些工具通常使它们能够与环境交互,例如游戏或软件应用程序。 外部工具的集成增强了角色扮演和生成智体,使它们能够执行超出其固有能力的操作和访问信息。 这有利于更准确、更适合上下文的交互,特别是在专门或复杂的场景中,从而显着提高用户参与中响应的质量和有效性。
记忆机制。记忆机制存储智体的配置文件以及环境信息,帮助智体将来采取行动。个人资料通常包括基本信息(年龄、性别、职业)、心理特征(反映个性)和社会关系(Wang et al., 2023c; Park et al., 2023;Qian et al., 2023),可以是手动创建(Caron & Srivastava, 2022;Zhang et al., 2023a;Pan & Zeng, 2023;Huang et al., 2023b;Karra et al., 2022;Safdari et al., 2023)或从模型生成(Wang et al., 2023c)。 该模块使智体能够积累经验、发展并一致有效地采取行动(Park et al., 2023)。 语言智体借鉴了人类记忆的认知科学研究,人类记忆从感觉记忆发展到短期记忆,然后发展到长期记忆(Atkinson & Shiffrin,1968;Craik & Jennings,1992)。 短期记忆被视为 Transformer 架构约束窗口内的信息输入(Fischer,2023;Rana,2023;Wang,2023j;Zhu,2023a)。 相比之下,长期记忆通常保留在外部向量库中(Qian et al., 2023;Zhong et al., 2023;Zhu et al., 2023b;Lin et al., 2023;Xie et al., 2023; Wu et al., 2024b) 或自然语言数据库 (Shinn et al., 2023; Modarressi et al., 2023),智体可以根据需要做快速查询和检索信息。 与普通的LLM相比,语言智体需要在不断变化的环境中学习和执行任务。 对于 RPLA,记忆机制发挥着关键作用,使这些智体能够随着时间的推移保持交互的连续性和上下文。 通过存储和检索用户特定的数据和环境背景,智体可以提供更加个性化和相关的响应,从而增强用户在不同场景中的体验和参与度。
如图所示是RPLA研究方法的分类:
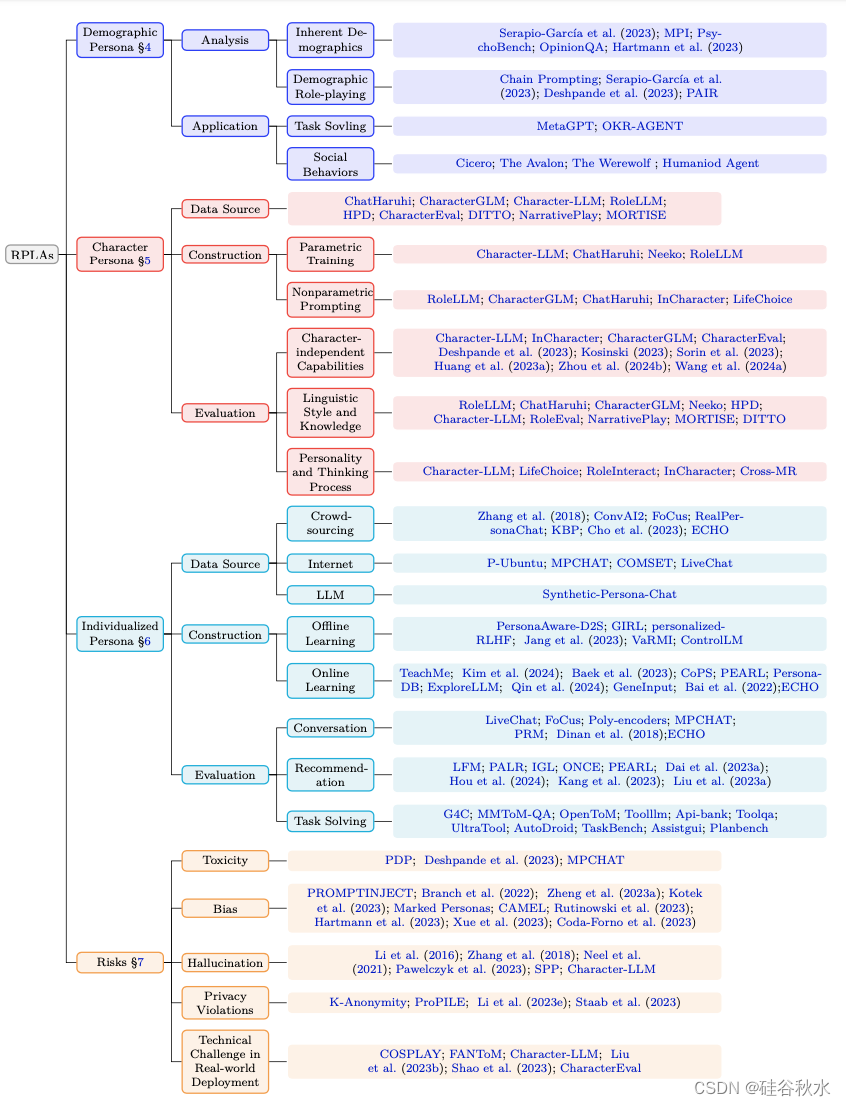
分配有人口统计角色的 RPLA 预计会显示特定人群的独特特征。 在此背景下,人口统计数据捕获了与具有共同特征的群体相关的典型特征,例如职业角色(例如数学家)、爱好或兴趣(例如棒球爱好者)和性格类型(例如Myers-Briggs- RPLA 中的这些表示融合了代表人口原型的语言风格、专业知识和行为细微差别。
这些 RPLA 旨在模仿特定人群如何处理并参与信息和沟通渠道,反映其独特的语言偏好、特定领域的词汇和独特的观点。 这种转变旨在将 RPLA 广泛而灵活的功能转化为复杂的虚拟表示,反映人口的智力微妙性、个人倾向和社会复杂性。 通过体现特定群体,人口统计RPLA可以增强其在某些领域的能力,也可以利用代表不同人口统计的多种RPLA进行社会实验、完成更复杂的任务等。
人物主要是故事被公众广泛认可的知名人物,包括名人、历史人物和虚构人物(例如Monkey D. Luffy 和 Hermione Granger)。 有时,它们还包括个人创建的原创角色(Zhou et al., 2023a)。 人物 RPLA 最近已成为LLM应用的一个蓬勃发展的领域(例如,Character.ai),因此也引起了广泛的研究兴趣(Shao,2023;Wang,2023g;2024c)。
对于人物 RPLA 来说,有效角色扮演的基本要求是LLM理解角色的能力。 早期研究研究了语言模型的字符理解,涉及将概述字符特征的描述与其角色(即字符预测)和个性(即个性理解)联系起来:1)字符预测主要侧重于从提供的文本中识别字符。 这包括共参解析(Li et al., 2023c)、关系理解(Zhao et al., 2024)和字符识别(Brahman et al., 2021;Yu et al., 2022;Li et al., 2023c;Zhao,2024)。 此外,一些研究调查语言模型是否可以预测角色的未来行为,基于以下因素:2)个性理解旨在从对话和行为中解码角色特征,包括预测所描述的特征(Yu et al., 2023)和生成角色描述(Brahman,2021)。
近年来,LLM在语言理解和生成方面表现出了强大的能力,极大地推动了RPLA的发展。 因此,这个方向的研究重点转向应用和推广LLM来忠实地再现人物,包括它们的语言风格(Wang et al., 2023g; Zhou et al., 2023a; Li et al., 2023a; Wang et al. 2023g)、知识(Li et al., 2023a;Shao et al., 2023;Zhou et al., 2023a;Chen et al., 2023c;Zhao et al., 2023a;Wang et al., 2023g)、人格 (Shao et al.,2023;Wang et al.,2024c),甚至决策(Zhao et al.,2023a;Xu et al.,2024b)。
个性化定制LLM以满足个人的独特需求、经验和偏好,这在现代AI应用中变得越来越重要(Salemi,2024)。 该领域的研究旨在提供个性化服务,适应个人用户的偏好甚至反映他们的行为(Chen et al., 2023b)。 当这样的个性化系统试图封装这些条目时,它本质上是在进行角色扮演,模仿个人。 这一过程塑造了 RPLA 的个性化角色(Salemi,2024),通常体现为个人的数字克隆或个人助理。
个性化 RPLA 的应用分为三层,从对话(Gao,2023b;Ahn,2023)到推荐(Chen,2023b;Yang, 2023a),到自主智体来解决更复杂的任务(Li et al., 2024d)。
- 对话:个性化 RPLA 的早期研究主要集中在通过学习和整合用户角色来实现个性化对话(Cho,2022;Zhou,2023c;Ng,2024),将风格特征与用户角色相结合。 用户偏好以提高参与度(Zheng,2021;Wang)。随着法学硕士的出现和发展,个性化的RPLA变得能够处理日益复杂和全面的任务,获得复杂任务规划和工具学习的能力,以自动完成个性化服务。
- 推荐:基于LLM的会话推荐系统(Chen et al., 2023b; Yang et al., 2023a; Wu et al., 2023)已被广泛认为是下一代推荐系统(Lian et al., 2024),通过多轮对话支持用户实现推荐相关目标(Jannach et al., 2021)。与传统的推荐相比,这些方法以其坚实的基础模型、自然语言交互以及简单、典型的非参数进化而脱颖而出(Sallam,2023;Abbasian,2023)。
- 任务解决:此外,个性化 RPLA 在解决更复杂的任务方面变得越来越有能力(Yao,2023a;Significant-Gravitas,2023),例如编码(Microsoft,2024)、旅行计划(Xie,2024a) )和研究调查(Wang,2024b),通常与各种外部软件交互。 它们是基于 LLM的自主智体,与个人数据、设备和服务深度集成(Dong,2023;Li,2024d)。 他们拥有比 Siri(Apple,2024)等早期更先进的个人助理,后者难以应对复杂的用户请求。
为了构建准确捕捉和描绘个性化角色的个性化 RPLA,该过程通常包括两个关键步骤:1) 角色数据收集,收集必要的数据来塑造个性化角色;2) 角色建模,这些个人角色使用收集的数据创建表征模型。 对于角色数据收集,不同应用程序和任务中的数据在格式、内容和模式上可能存在很大差异。 这些数据分为三种类型:个人资料、交互和领域知识。 对于角色建模,挑战是从未处理的角色数据中体现预期的角色,这些数据通常是大量、稀疏和嘈杂的。
尽管LLM取得了进步,个性化 RPLA 仍然面临一些挑战,包括处理长输入和巨大的搜索空间(Chen,2023b;Abbasian,2023),利用稀疏、冗长和嘈杂的用户交互数据(Zhou, 2024c)、学习特定域知识以理解用户配置文件 (Zhang et al., 2023c)、理解多模态上下文 (Dong et al., 2023)、确保隐私和道德标准 (Benary et al., 2023; Eapen & Adhithyan),并优化响应时间无缝集成到实时应用程序中。
虽然 RPLA 越来越多地部署在现实世界的应用中,但如果处理不当,潜在的隐患可能会导致严重问题。 与当前 RPLA 相关的风险,涵盖以下领域:1) 毒性,2) 偏见,3) 幻觉,4) 隐私侵犯,以及 5) 现实部署中的技术挑战。
未来的研究方向:
- 用于决策的因果数据分析:角色扮演决策必须出于合理的原因而做出,这需要模型超越对可观察行为的简单模仿,包括对其潜在因果关系的理解。 从相互交织的经验中提取和确认因果因素的复杂性带来了重大挑战,需要先进的分析和更深入的数据解释策略,以使 RPLA 能够做出明智的决策。
- 改进决策:决策过程不仅仅是复制历史,而是量身定制以确保个别情况的最佳结果。 这包括表现出先进(如果不是超人)智慧的决策、避免错误或在艰难的困境中做出最佳选择。 此类机构要求 RPLA 和底层LLM能够全面收集和利用与其角色相关的背景和复杂性。
- RPLA 作为个人决策的个人助理:RPLA 未来发展为综合个人助理标志着重大转变。 这些系统可以管理互联网行为的各个方面,从定制购物和个性化旅行计划到新一代推荐系统。 通过整合图像和视频等多模态数据处理,并与先进的可视化技术相结合,RPLA 可以显着提高日常任务的个性化和效率。
- 通过自主角色扮演进行社会模拟:利用 RPLA 进行社会模拟可以在不同场景中进行精细实验研究心理和社会行为,从而显着扩展其应用。 通过扮演各种角色,RPLA 可以作为多功能测试目标,探索不同人格特质对社交智力的影响,为人类行为和互动动态提供有价值的见解。

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









