










24年6月来自斯坦福大学的论文“HumanPlus: Humanoid Shadowing and Imitation from Humans“。
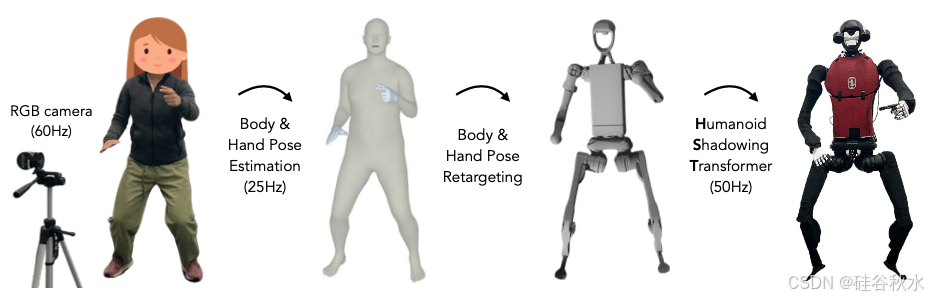
制造与人类外形相似的机器人,其关键点之一是,可以利用大量的人类数据进行训练。然而,由于人形机器人感知和控制的复杂性,还有形态和驱动方面人形机器人与人类之间仍然存在的物理差距,以及人形机器人缺乏从自我中心视觉中学习自主技能的数据流水线,因此在实践中仍然具有挑战性。本文介绍一个全栈系统,供人形机器人从人类数据中学习运动和自主技能。首先使用现有的 40 小时人体运动数据集,通过强化学习在模拟中训练低级策略。该策略迁移到现实世界,并允许人形机器人仅使用 RGB 摄像头实时跟踪人体和手部运动,即跟随(shadowing)。通过跟随,人类操作员可以遥控人形机器人来收集全身数据,学习现实世界中的不同任务。然后,用收集的数据进行监督行为克隆,用自我中心视觉去训练技能策略,使人形机器人能够通过模仿人类技能自主完成不同的任务。在定制的 33 自由度 180 厘米高人形机器人上演示该系统,通过最多 40 次演示,机器人可以自主完成穿鞋站立和行走、从仓库货架上卸下物品、折叠运动衫、重新摆放物品、打字和问候其他机器人等任务,成功率达到 60-100%。
人形机器人因其与人类相似的外形而一直受到机器人界的关注。由于周围的环境、任务和工具都是基于人类形态构建和设计的,因此人形机器人是通用机器人的天然硬件平台,可以潜在地解决人类可以完成的所有任务。人形机器人的类人形态,也提供了一个独特的机会,可以利用大量可用于训练的人类运动和技能数据,绕过机器人数据的稀缺性。通过模仿人类,人形机器人可以潜在地利用人类所展现的丰富技能和动作,为实现通用机器人智能提供了一条有希望的途径。
然而,在实践中,人形机器人从人类数据中学习仍然具有挑战性。人形机器人的复杂动态和高维状态和动作空间给感知和控制都带来了困难。传统方法,例如将问题解耦为感知、规划和跟踪,以及分别模块化手臂和腿部的控制 [10, 10, 23, 40],设计起来可能非常耗时,而且范围有限,因此很难扩展到人形机器人预计将要执行的各种任务和环境。此外,尽管人形机器人与其他形式的机器人相比与人类非常相似,但人形机器人与人类在形态和驱动方面仍然存在物理差异,包括自由度数、连杆长度、身高、体重、视觉参数和机制,以及驱动强度和响应能力,这给人形机器人有效使用和学习人类数据带来了障碍。
缺乏现成的集成硬件平台,进一步加剧了这一问题。此外,缺乏用于人形机器人全身遥控操作的可访问数据流水线,无法利用模仿学习作为工具来教人形机器人任意技能。多家公司开发的人形机器人已经展示了这种数据流水线的潜力以及随后从收集的数据中进行模仿学习的能力,但细节未公开,其系统的自主演示仅限于几个任务。之前的研究使用动作捕捉系统、第一人称视角 (FPV) 虚拟现实 (VR) 耳机和外骨骼(exoskeletons)来遥控人形机器人 [17, 20, 38, 59],这些系统价格昂贵且操作位置受限。
如图所示一个人形机器人全栈系统,从人类数据中学习动作和自主技能。系统使机器人能够模仿人类操作员快速多样的动作,包括拳击和打乒乓球,并学习穿鞋、叠衣服和跳高等自主技能。

人形机器人具有33个自由度,包括两个6自由度的手、两个1自由度的手腕和一个19自由度的身体(两个4自由度的手臂、两个5自由度的腿和一个1自由度的腰部),如图所示。

该系统建立在Unitree H1机器人的基础上。每条手臂都集成了一个Inspire-Robots RH56DFX手,通过定制的手腕连接。每个手腕都有一个Dynamixel伺服器和两个推力轴承。手和手腕均通过串行通信控制。机器人头部安装有两个RGB网络摄像头(Razer Kiyo Pro),向下倾斜50度,瞳孔距离为160毫米。手指可以施加高达10N的力,而手臂可以承受高达7.5公斤的物品。腿部的电机在运行过程中可以产生高达360Nm的瞬时扭矩。上图右提供了机器人的其他技术规格。
用基于光学标记(marker)的公开人体运动数据集 AMASS [49] 来训练低层人形跟随 Transformer。AMASS 数据集汇总了来自多个人体运动数据集的数据,包含 40 小时的人体运动数据,涉及各种任务,由 11,000 多个独特的运动序列组成。为了确保运动数据的质量,应用基于 [48] 中过滤过程。人体和手部运动使用 SMPL-X [57] 模型进行参数化,该模型包括 22 个身体和 30 个手部 3-DoF 球形关节、三维全局平移变换和三维全局旋转变换。
类人身体具有 SMPL-X 身体自由度的一个子集,仅由 19 个旋转关节组成。为了重新定位身体姿势,将相应的欧拉角从 SMPL-X 复制到类人模型中,即臀部、膝盖、脚踝、躯干、肩膀和肘部。每个人形臀部和肩部关节都由 3 个正交旋转关节组成,因此可以看作一个球形关节。类人机械手有 6 个自由度:食指、中指、无名指和小指各有 1 个自由度,拇指有 2 个自由度。为了重新定位手部姿势,用中间关节的旋转来映射每个手指相应的欧拉角。为了计算 1-DoF 腕角,用前臂和手全局方向之间的相对旋转。
为了估计现实世界中的人体运动以进行跟随处理,采用WHAM[81]方法,使用单个 RGB 摄像头实时联合估计人体姿势和全局变换。WHAM 使用 SMPL-X 进行人体姿势参数化。如图所示,用上述方法执行实时人对人形身体重定位。身体姿势估计和重定位在 NVIDIA RTX4090 GPU 上以 25 fps 的速度运行。
用 HaMeR [58](一种基于 Transformer 的手势估计器,使用单个 RGB 摄像头)进行实时手势估计。HaMeR 用 MANO [72] 手部模型预测手势、摄像头参数和形状参数。用上述方法执行实时人对人形的手部重定向。手势估计和重定向在 NVIDIA RTX4090 GPU 上以 10 fps 的速度运行。
将低层策略人形跟随 Transformer 制定为仅解码器的Transformer,如图所示。
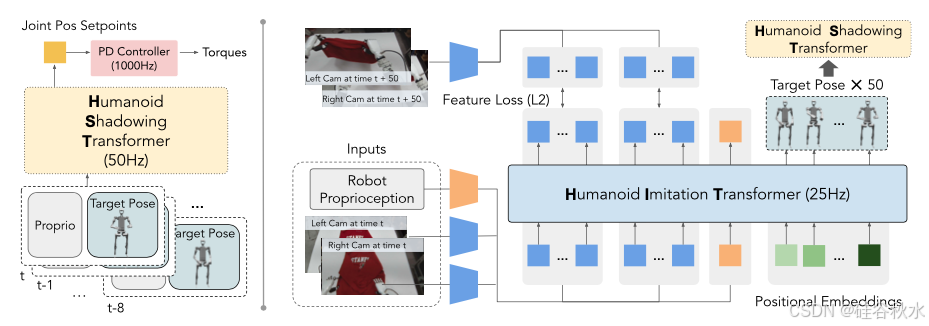
在每个时间步骤,策略的输入是人形本体感觉和人形目标姿势。人形本体感觉包含根状态(滚动、俯仰和基准角速度)、关节位置、关节速度和最后动作。人形目标姿势由目标前向和横向速度、目标滚动和俯仰、目标偏航(yaw)速度和目标关节角度组成,并从处理后AMASS 数据集中采样的人体姿势重定位。该策略的输出是人形身体关节 19 维关节位置的设定点,随后使用 1000Hz PD 控制器将其转换为扭矩。目标手关节角度直接传递给 PD 控制器。低层策略以 50Hz 的频率运行,上下文长度为 8,因此它可以根据观察历史适应不同的环境 [67]。
在仿真中采用PPO训练该模型,之后将其零样本部署到现实世界中的人形机器人上,进行实时跟随。本体感受观测仅使用机载传感器(包括 IMU 和关节编码器)进行测量。用单个 RGB 摄像头实时估计人体和手部姿势,并将人体姿势重定位到人形机器人目标姿势。人类操作员站在人形机器人附近,将他们的实时全身运动投影到人形机器人身上,并使用视线观察人形机器人的环境和行为,确保遥操作系统反应灵敏。当人形机器人坐下时,直接将目标姿势发送给 PD 控制器,因为不需要策略来补偿重力,而且模拟具有丰富接触的坐姿具有挑战性。在遥控操作时,人形机器人通过双目 RGB 摄像头收集自我中心视觉数据。通过跟随技术,为各种现实世界任务提供高效的数据收集流水线,从而解决了真实 RGB 渲染、准确软目标模拟和模拟中多样化任务规范的挑战。
通过在各种任务上进行演示,模仿学习在学习自主机器人技能方面表现出了巨大的成功 [5, 11, 15, 25, 104]。鉴于通过跟踪收集的真实世界数据,我们将相同的方法应用于人形机器人以训练技能策略。我们进行了一些修改,以便在有限的板载计算下实现更快的推理,并在双目感知和高自由度控制下实现高效的模仿学习。
在工作中修改 Action Chunking Transformer (ACT)[104],删除其编码器-解码器架构,开发仅用于解码器的人形模仿Transformer (HIT) 用于技能策略,如上图右侧所示。HIT 将来自两个以自我为中心 RGB 摄像头的当前图像特征、本体感觉和固定位置嵌入作为输入进行处理。这些图像特征使用预训练的 ResNet 编码器进行编码。由于其仅解码器的设计,HIT 通过基于输入的固定位置嵌入预测 50 个目标姿势块来运行,并且它可以预测与各自输入位置的图像特征相对应的tokens。在这些预测的图像特征上加入 L2 特征损失,迫使 Transformer 在执行真值目标姿势序列后预测未来状态的对应图像特征tokens。这种方法使 HIT 能够有效地将目标姿势预测与前向动态预测相结合。通过对图像特征使用前向动态预测,该方法正则化图像特征空间来提高性能,防止基于视觉的技能策略忽略图像特征和过拟合本体感觉。在部署期间,HIT 以 25Hz 的频率在机上运行,将预测的目标位置异步发送到低层人形跟随 Transformer,同时丢弃预测的未来图像特征tokens。

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









