










24年12月来自清华的论文“Doe-1: Closed-Loop Autonomous Driving with Large World Model”。
端到端自动驾驶因其从大量数据中学习的潜力而受到越来越多的关注。然而,大多数现有方法仍然是开环的,并且存在可扩展性弱、缺乏高阶交互和决策效率低下的问题。本文探索自动驾驶的闭环框架,并提出一个大型驾驶世界模型(Doe-1)用于统一感知、预测和规划。将自动驾驶制定为下一个token生成问题,并使用多模态tokens来完成不同的任务。具体而言,用自由格式的文本(即场景描述)进行感知,并使用图像tokens直接在 RGB 空间中生成未来预测。对于规划,用位置-觉察token化器将动作有效地编码为离散tokens。训练一个多模态Transformer,以端到端和统一的方式自回归生成感知、预测和规划tokens。在广泛使用的 nuScenes 数据集上进行的实验,证明 Doe-1 在各种任务中的有效性,包括视觉问答、动作条件视频生成和运动规划。
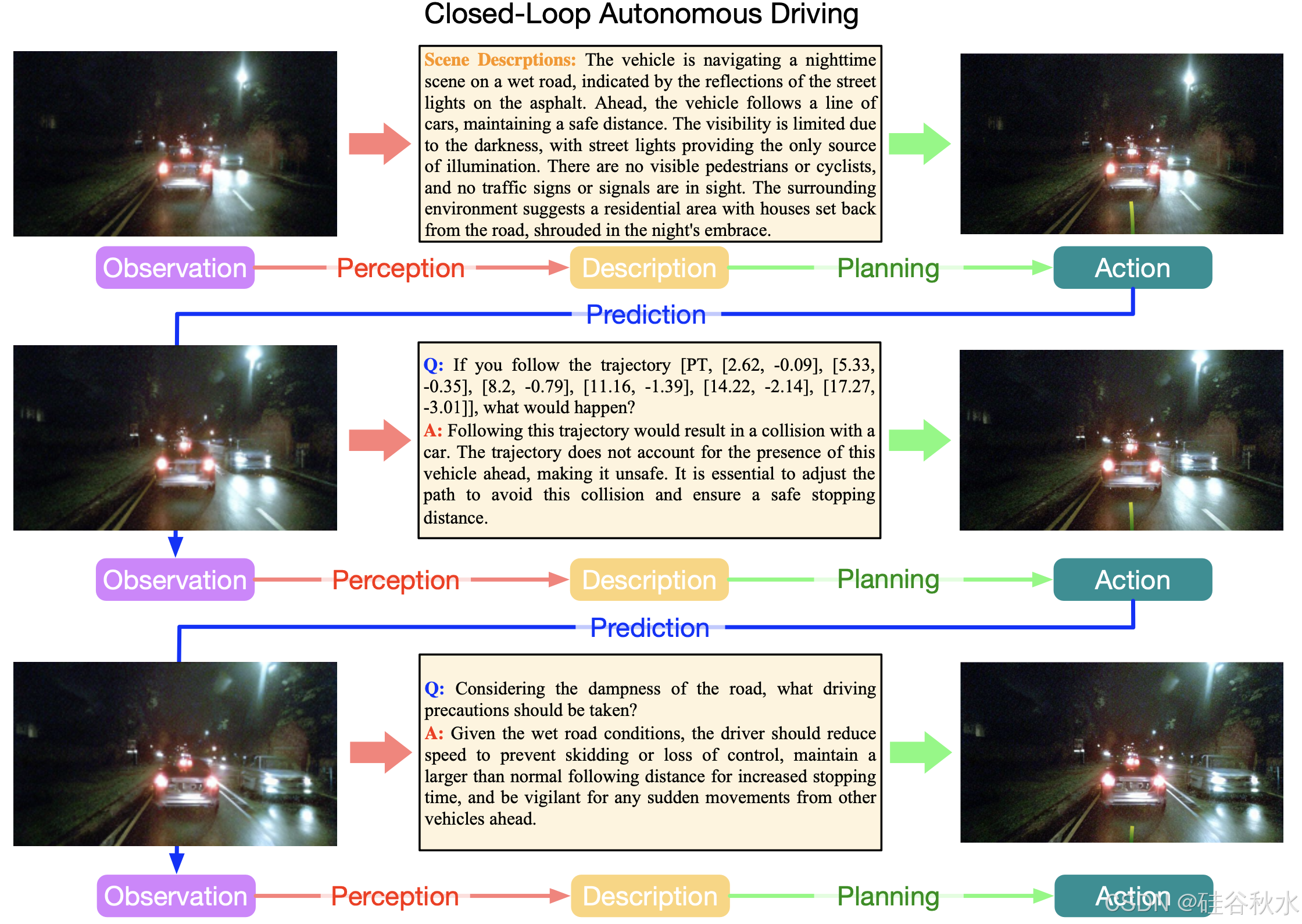
如图所示:在 nuScenes 上对闭环自动驾驶的 Doe-1 进行了可视化[11]。一个大型驾驶世界模型 (Doe-1) 实现统一的生成式闭环自动驾驶。将感知、预测和规划分别建模为观察→描述、描述→动作和动作→观察的转换。Doe-1 在统一的自回归生成框架中完成感知、规划和预测,并首次实现闭环端到端自动驾驶。
GPT 系列 [8, 9, 60] 的出现刺激了具有各种功能大模型的快速发展,包括语言建模 [2, 73, 74]、视觉理解 [3, 46, 47, 57] 和决策 [7, 37, 53]。大模型成功的关键是扩大模型大小和训练数据 [34]。在设计模型时,可扩展性主张较大的表征容量(例如,Transformers [17, 49, 75])而不是精心设计的归纳偏差(例如,卷积神经网络 [23, 29]),以提高性能的上限。
为了构建用于自动驾驶的大模型,一些方法直接应用大语言模型 (LLM) [13, 53, 65, 67] 或视觉-语言模型 (VLM) [62, 66, 71, 80, 81, 89, 98] 进行运动规划 [71] 或场景问答 [55, 79]。它们通常将输入与文本对齐(例如 Q-Former [39])并输出规划结果的语言描述 [53]。然而,众所周知,LLM 存在幻觉问题 [21, 42, 48],阻碍自动驾驶的可解释性和安全性。为了避免这种情况,其他人遵循经过充分测试的自动驾驶感知、预测和规划流程,并探索可扩展的端到端模型 [27, 28, 33, 72, 93, 100] 来共同完成它们。尽管前景光明,但大多数现有方法仍然是开环的,并且存在一些问题。1)可扩展性弱。它们使用手动设计的场景表示,无法为下游任务提供全面的信息。2)缺乏高阶交互。它们预测未来场景而不考虑规划的自车轨迹。3)决策效率低下。它们通常提前规划几步,但实际上只使用第一步来执行。
传统世界模型旨在根据自车智体动作预测场景的下一次观察[22,69]。大多数现有方法遵循此定义,并侧重于图像 [20,52,77,85,90]、LiDAR [35,36,54,86] 或3D占用 [78,99]空间中的受控生成。基于视觉的方法通常利用预训练图像扩散模型(例如Stable Diffusion[63])的功能,并根据驾驶场景对其进行微调,预测动作条件下的未来[19,40,82,91]。其他方法探索更多样化的架构(例如自回归Transformer [25,88,99]、GRU [5]或自动编码器 [1,92])来生成未来场景。然而,大多数方法不能直接应用于轨迹规划,通常用于计算奖励以使用强化学习训练另一个规划器 [20]。OccWorld [99] 概括了世界模型的概念,并预测了 3D 占用和自车的联合演化。尽管如此,它仍然需要预训练的感知模型来获得 3D 占用,并且受到其表示能力的限制。不同的是,提出的 Doe-1 采用一个闭环统一框架进行感知、预测和规划,作为广义的自动驾驶模型。
感知、预测和规划是自动驾驶中久经考验的流程,通常由单独的模块实现 [14, 30, 58, 64]。最近的方法探索了端到端设计,即联合训练所有模块,共同的目标是轨迹规划 [27, 28, 33, 72, 93, 100]。统一的框架使它们具有更大的扩展可行性和实现自动驾驶原生大模型的潜力。早期方法 [27, 28] 采用鸟瞰图作为场景表示,以在整个模型中传递信息。后续方法探索使用 3D 占用 [72, 99] 来获取更多细节,或使用稀疏查询 [68, 96] 来提高效率。然而,手动设计的场景表示,可能不是最佳的,并且诱导的归纳偏差限制了模型的能力,这对于扩大规模至关重要。它们还存在缺乏高阶交互和决策效率低下的问题。
本文提出第一个闭环自动驾驶模型 Doe-1,以实现更具可扩展性的自动驾驶,它使用自由格式的文本实现感知并直接在图像空间中预测未来,以减少信息丢失并扩大模型容量。
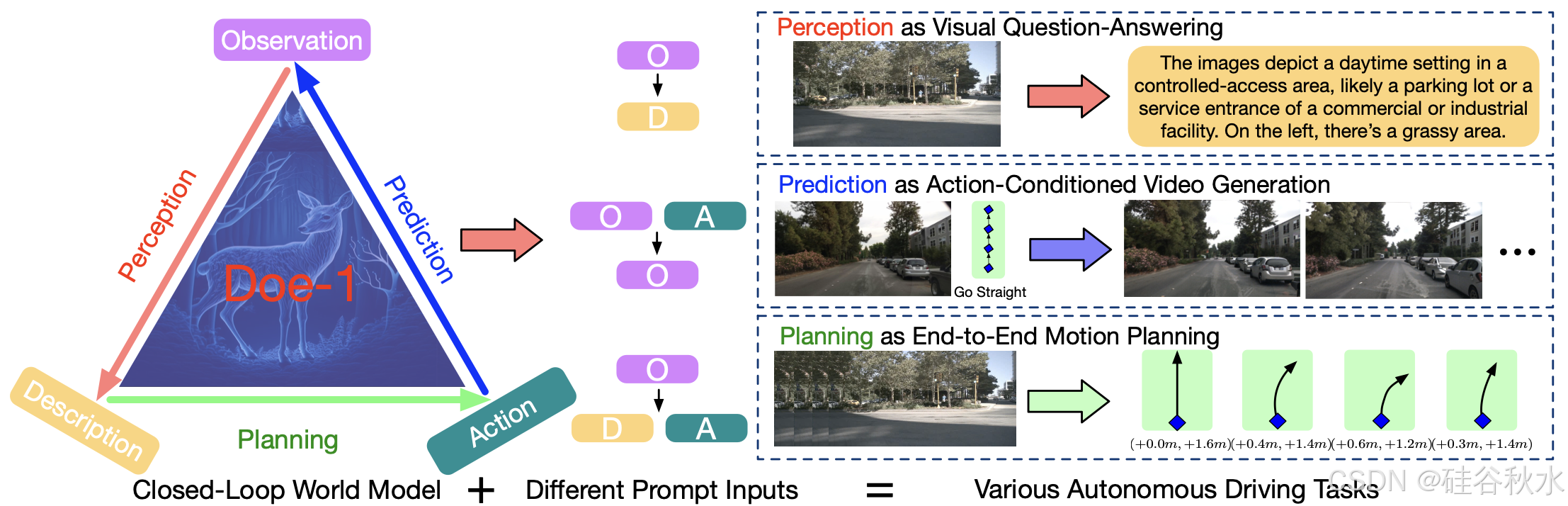
如图所示Doe-1 概述。将自动驾驶制定为统一的下一个token生成问题,并使用观察、描述和动作tokens来表示每个场景。无需额外微调,Doe-1 通过使用不同的输入提示来完成各种任务,包括视觉问答、受控图像生成和端到端运动规划。
自动驾驶是将人工智能应用于现实世界的一项长期任务,其旨在根据场景观察{o}为自身车辆规划未来的行动{a}。
最近的方法利用大语言模型 (LLM) 或视觉语言模型 (VLM) 的推理能力来提高规划结果的可解释性 [13, 55, 65, 67, 97]。它们通过直接转录 [65] 或可学习投影 [66] 将视觉特征与文本空间对齐。一些方法进一步使用额外的文本描述 d 作为辅助任务 [79],以进一步缓解大型模型的幻觉问题 [48]。
尽管如此,如果没有对场景的细粒度理解和预测,LLM/VLM 是否真正理解交通主体之间的 4D 动态和交互仍值得怀疑。
为了构建更值得信赖的自动驾驶系统,主流方法(包括现代端-到-端模型 [27、28、33、72、93、100])采用“分而治之”策略,将自动驾驶分解为顺序感知 f、预测 g 和规划 h。
场景表示 r 是 3D 空间中的一组连续特征(例如,鸟瞰图 [41, 43]、体素 [84]、三透视图 [30, 101]、3D 高斯 [31, 32, 87]、密集点 [18]),而场景描述 d 提供场景的高级精细描述(例如,检测到的边框、构造的地图)。d 的设计引入了对决策最重要因素的先验知识,从而可以提高模型的鲁棒性。
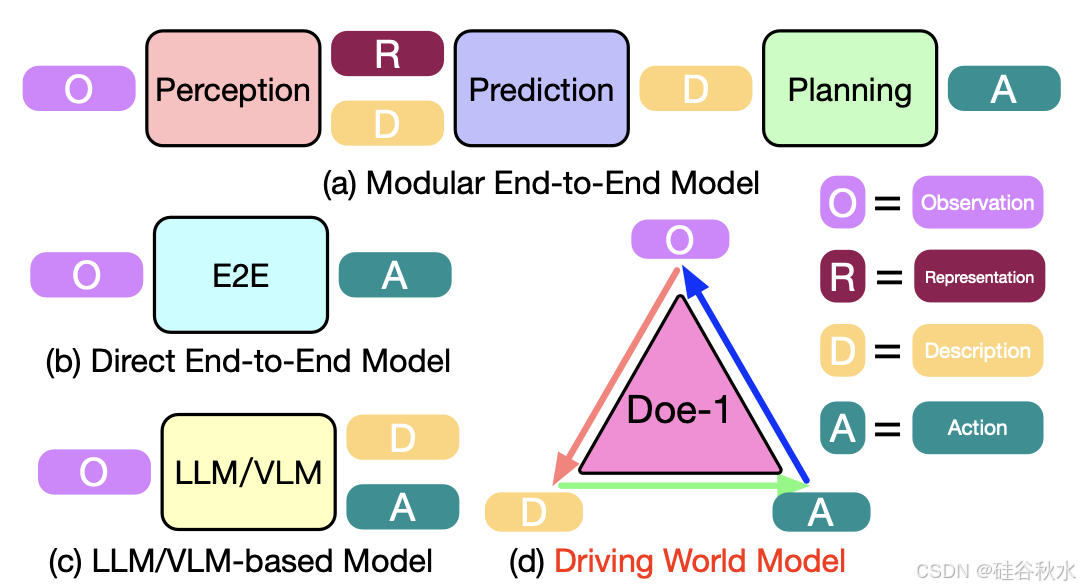
如图所示不同自动驾驶范式的比较。(a)模块化端-到-端模型按顺序执行感知、预测和规划,是自动驾驶最流行的流程。(b)直接端-到-端模型根据传感器输入直接输出规划的动作。(c)基于 LLM/VLM 的模型利用 LLM/VLM 的推理能力来输出动作。(d)提出的驾驶世界模型 (Doe-1) 预测观察、描述和动作之间的演变,以实现闭环端-到-端自动驾驶。
大型驾驶世界模型 Doe-1 将自动驾驶视为多模态状态的自回归世界演化。使用自注意机制,Doe-1 可以直接访问观察结果,并从观察空间预测未来场景的演变,而无需中间场景表示。Doe-1 以自车行动为条件进行预测。通过自回归生成,Doe-1 可以预测多步未来,但每次只进行即时规划。
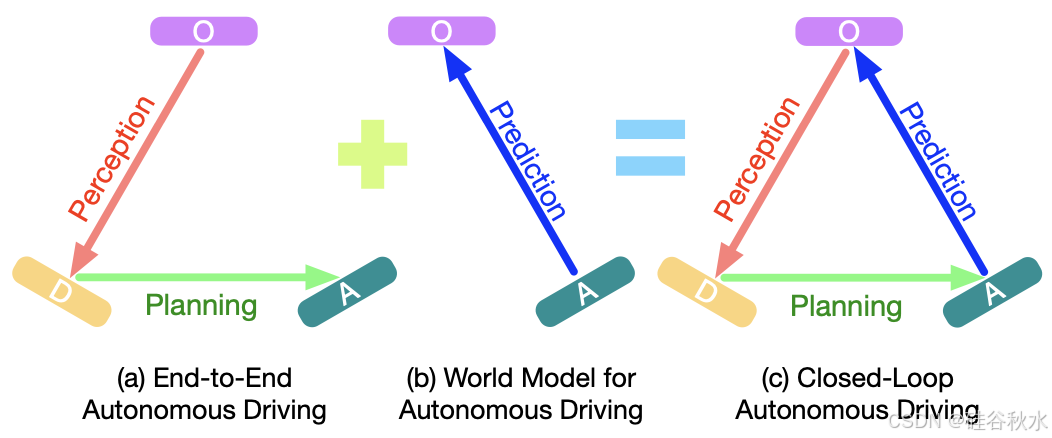
如图所示所提出的闭环自动驾驶范式的说明。(a)现有的端-到-端自动驾驶方法(例如 UniAD [28]、GenAD [100])通常首先进行感知,然后根据感知的描述做出决策。(b)现有的自动驾驶世界模型(例如 DriveDreamer [82]、OccWorld [99])根据当前动作预测未来的观察结果。(c)闭环自动驾驶将这两种范式结合起来,构建一个闭环。
Doe-1 的整体框架如图所示。用 Chameleon 架构 [70] 作为统一的多模态自回归模型来生成预测。按照预测步骤,将观测 o、描述 d 和动作 a token 化为离散空间并简单地连接成序列,其中 (h, w) 是观测图像的形状,l 是字符串 d 的长度,p 是使得 a 包含二维空间中 p 个运动参数的运动数量。使用过去的序列作为提示,统一模型将迭代地预测下一个token。具体而言,给定token化的观测 Ti/o、高级描述 Ti/d 和从时间 i 开始的动作 T^i/a(其中 0 ≤ i ≤ t),该模型给出时间 t + 1 的预测token。然后从预测的tokens中解码出 o/t+1 、 d/t+1 、 a/t+1 。为了将序列 {o/i , d/i , a/i } 编码为离散tokens,使用了观察token化器、描述token化器和动作token化器。
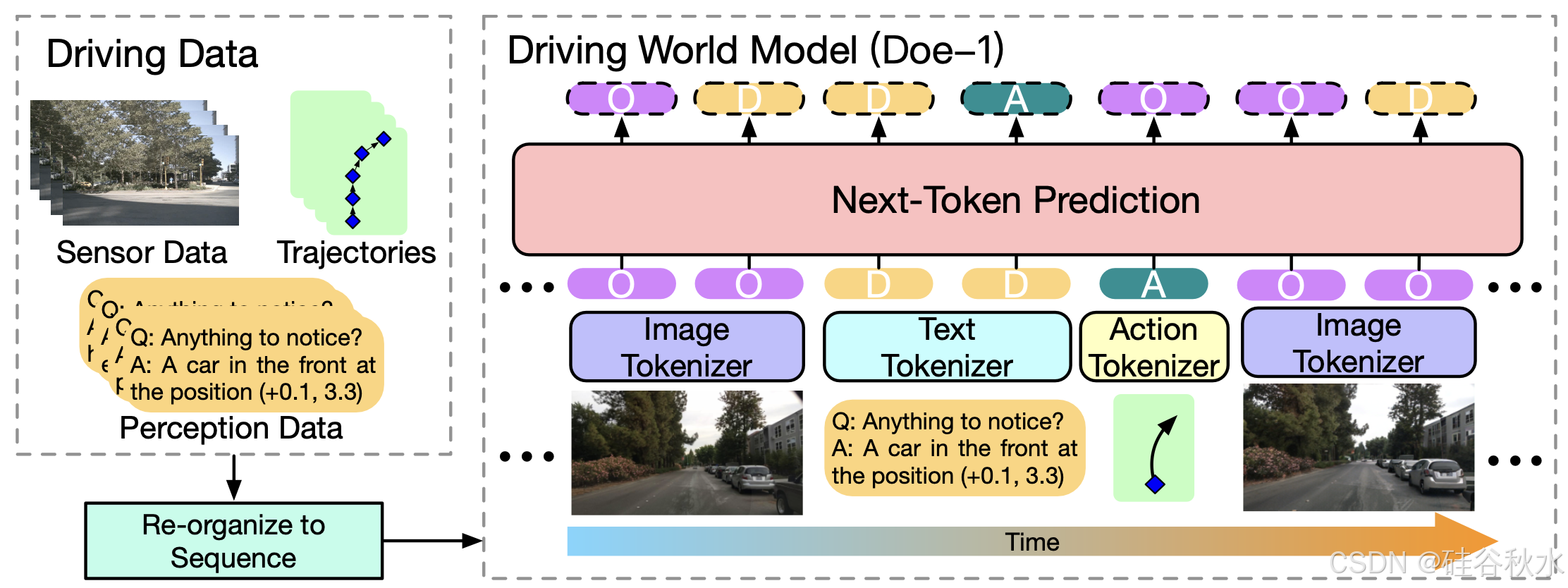
观察token化器。观察是 RGB 空间中的图像。为了将图像 o 映射到离散空间中的tokens T/o,用来自 Lumina-mGPT [45] 的预训练图像token化器,它将图像编码为来自大小为 8192 码本的 1024 个离散tokens,并添加特殊tokens来指示图像的形状。
描述token化器。在交互场景中,描述 d 位于字符空间中,l 表示字符串 d 的长度。用来自 Chameleon [70] 的 BPE token化器将描述文本编码到离散空间中。
将浮点数作为文本处理,会丧失其在欧氏空间中原有的度量属性。对于描述文本中的浮点数序列(比如自车到某目标的距离),将其四舍五入到0.02米的分辨率,然后将离散化的浮点数依次映射到4000个离散tokens中。为了在嵌入后保持数字原有的度量属性,用正弦位置编码作为这些token的嵌入特征,保证差异较小的浮点数在高维空间嵌入后仍能保持较小的距离。位置嵌入被设置为不可学习,以确保在训练阶段未见过的浮点数在嵌入空间中仍然对齐。
动作token化器。运动 z 表示车辆在两帧之间的运动,定义为三元素数组 z = (d/x, d/y, θ),包含沿两个水平轴和偏航角的位移,模型给出的动作 a 连接 p 个连续移动以表示接下来 p 帧的未来轨迹。要将动作编码为离散tokens,用类似于上述的位置编码,并简单地调整缩放常数。特殊token作为锚点插入动作的开始和结束。
生成式架构。通过调整多模态生成,可以轻松扩展统一模型。对于任何模态,该模型都遵循统一的自回归范式。在预测动作时,模型通过基于前一个token序列 T 给出 p(a/t|T) 来同时为多个未来帧生成多个运动预测,并且 a/t 将影响后续tokens的预测。为了避免不同帧预测之间误差的积累,在生成预测 a 时,掩码生成的最后 p-1 个运动预测,并保留第一个预测以提供生成后续观测的参考。
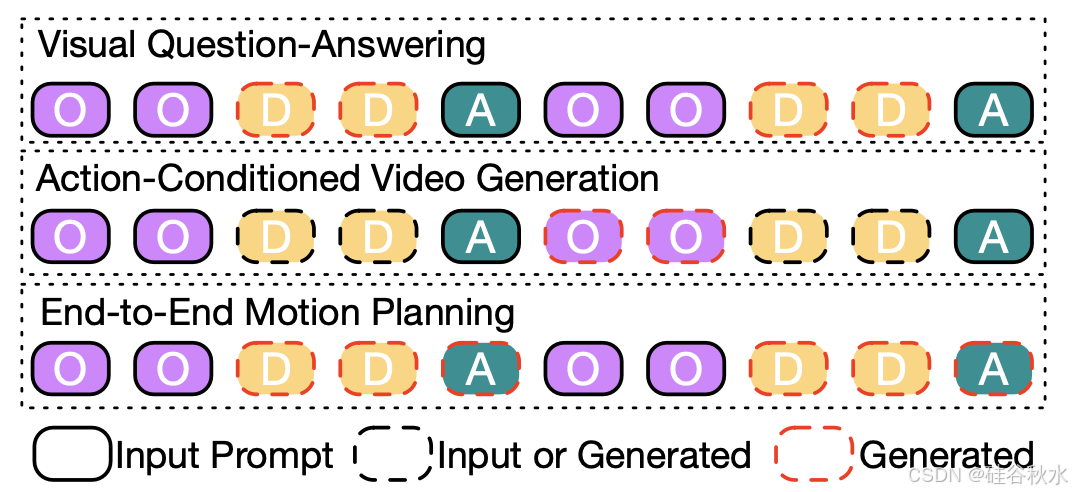
如图所示 Doe-1 应用于不同任务的不同提示设置。对于视觉问答,用观察tokens作为提示输入并生成描述tokens。对于动作条件视频生成,用当前帧的观察和动作tokens作为输入并生成下一帧的观察tokens。对于端到端运动规划,用观察tokens作为提示来生成描述和动作tokens。
使用预训练的 Lumina-mGPT 7B [45] 来初始化模型,并在 BDD100k [94] 数据集上对模型进行 5 个 epoch 的微调,以提高驾驶场景图像的条件图像生成能力。将分辨率为 672 × 384 的图像作为输入,并且只采用来自摄像头的图像。动作token化器的分辨率设置为 0.02m,其中位移的缩放因子设置为 10000,偏航角的缩放因子设置为 1000。
对于训练,用带有余弦学习率调度程序的 AdamW [50] 优化器。初始学习率设置为 1 × 10−5,权重衰减为 0.1。为了强调动作预测的准确性,将输入序列中动作tokens的损失权重增加 5 倍。应用权重为 1 × 10−5 的 Z-损失来稳定训练。在 8 个 A100 GPU 上对模型进行 16 个epochs的训练,总批次大小为 24。

















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









