









24年12月来自Cruise和美国东北大学的论文“VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision”。
人类驾驶员依靠常识推理来应对多样化和动态的现实世界场景。现有的端到端 (E2E) 自动驾驶 (AD) 模型通常经过优化,以模仿在数据中观察的驾驶模式,而不会捕捉到底层的推理过程。这个限制了它们处理具有挑战性的驾驶场景的能力。为了弥补这一差距, VLM-AD 利用视觉语言模型 (VLM) 作为老师,通过提供额外的监督来加强训练,这种监督结合了非结构化推理信息和结构化动作标签。这种监督增强了模型学习更丰富的特征表示能力,这些特征表示可以捕捉驾驶模式背后的原因。重要的是,该方法在推理过程中不需要 VLM,这使得它适用于实时部署。当与最先进的方法相结合时,VLM-AD 可以在 nuScenes 数据集上显着提高规划准确性并降低碰撞率。
如图所示:(a)传统端到端方法;(b)VLM-AD 在训练期间使用辅助文本预测任务增强任意端到端驾驶模型。这些任务从 VLM 中提取驾驶推理知识,以鼓励模型学习更丰富的表示,而无需在训练时微调 VLM 或在推理时需要 VLM。
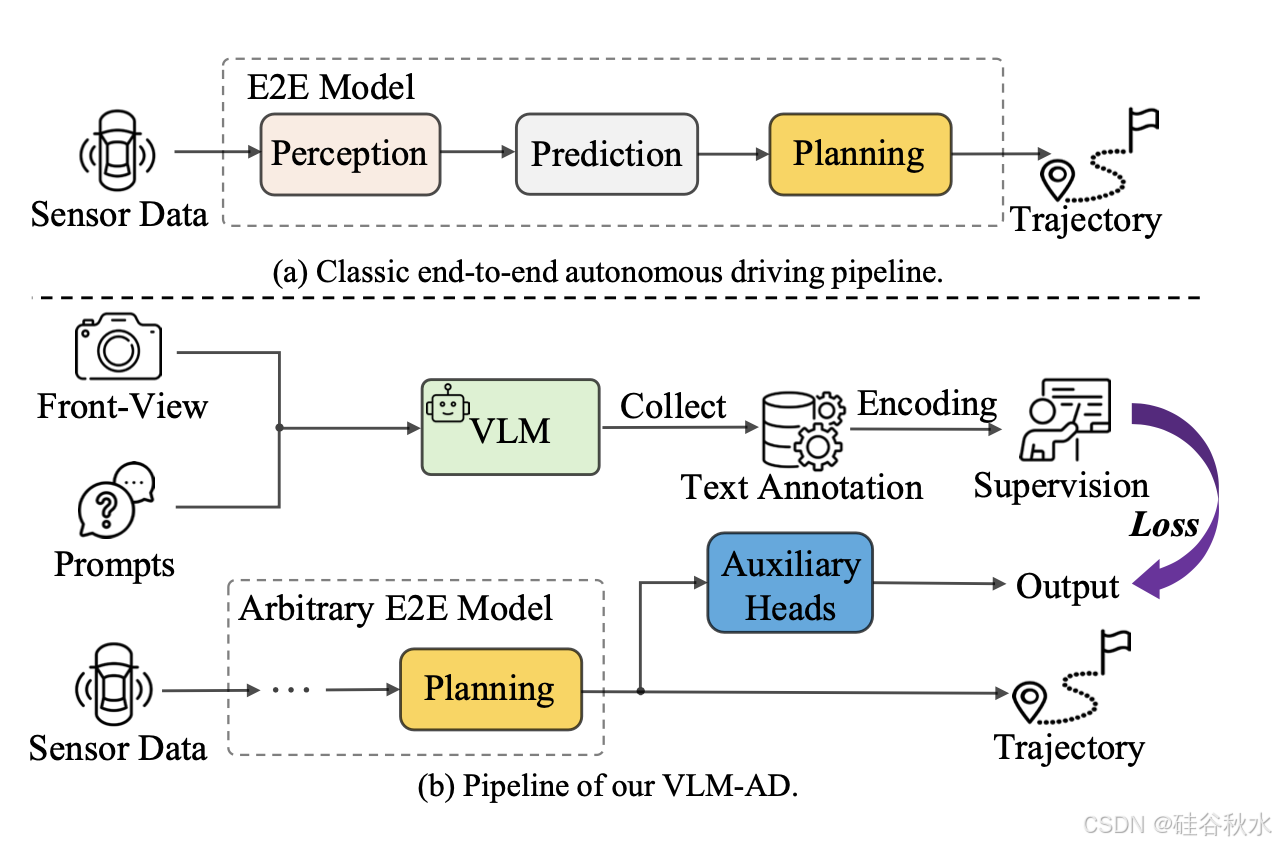
端到端自动驾驶 (AD) 将感知、预测和规划统一到一个框架中。这种整合旨在协调多个复杂任务,包括检测、跟踪、映射、预测和规划。最近的方法 [17、18、26] 通过使用传感器数据通过单一的整体模型生成规划的自车轨迹来解决这些挑战。尽管这些方法已经显示出有希望的结果,但它们的性能在具有挑战性的长尾事件中会下降 [5、7]。另一方面,人类驾驶员通常可以有效地处理这种情况,通过推理驾驶环境并相应地调整他们的行为。这凸显了当前 E2E 模型的训练差距,这些模型仅依赖于作为点序列的轨迹监督,缺乏学习丰富而鲁棒的特征表示以实现更好驾驶性能所必需的推理信息。
手动注释推理信息通常成本高昂、耗时,并且容易出现不一致和主观的结果,因此很难获得高质量和可扩展的注释。大型基础模型通过提供其推理能力来处理驾驶等复杂任务,从而提供了一种替代方案。最近的方法 [4, 13, 20, 27, 39, 40, 51, 54, 55, 61] 已将大型基础模型(如大语言模型 (LLM) [12, 44, 52] 和视觉语言模型 (VLM) [31, 32, 36, 45])直接集成到 AD 系统中,以利用其推理能力。然而,这些方法需要进行大量微调才能将基于语言的输出转换为精确的数值结果,例如规划轨迹或控制信号。此外,这些方法在推理过程中依赖大型基础模型,这大大增加了训练成本和推理时间,使得这些方法不适用于实际应用。鉴于人工注释的局限性以及将大型基础模型直接集成到驾驶系统中的挑战,提出以下问题:大型基础模型(如 VLM)是否可以生成基于推理的文本信息来增强自动驾驶模型,而无需在推理时进行集成?
端到端自动驾驶。端到端自动驾驶系统联合训练所有模块以实现统一目标,从而减少整个流程中的信息丢失。ST-P3 [17] 和 UniAD [18] 等统一框架提出了基于视觉的端到端 AD 系统,将感知、预测和规划统一起来。这些模型在开环 nuScenes 数据集 [3] 上取得了最佳效果。后续研究,如 VAD [26] 和 VADv2 [6],引入了一种矢量化编码方法,用于高效场景表示,并扩展到 CARLA [14] 上的闭环模拟。最近开发了 Ego-MLP [62]、BEV-Planner [35] 和 PARA-Drive [58] 等方法,以探索模块化堆栈中的自我状态和新颖的设计空间,以进一步提高驾驶性能。虽然 E2E 驾驶模型在 E2E 驾驶方法的开发中显示出良好的效果,但它们主要针对模拟数据中的驾驶模式进行了优化,而没有捕捉到底层的推理过程。这种限制主要是由于现有数据集中缺乏推理信息。因此,这些方法无法获得更深层次的推理知识,这可能会限制它们在具有挑战性的场景中的表现。
自动驾驶的基础模型。基础模型,包括大语言模型 (LLM) 和视觉语言模型 (VLM),越来越多地应用于自动驾驶,以利用其先进的推理能力。GPT-Driver [39] 和 Driving-with- LLMs [4] 使用 LLM 提供带有解释的行动建议,从而提高决策透明度。最近的一种方法 [11] 利用 LLM 来评估车道占用率和安全性,从而实现更像人类的直观场景理解。然而,基于 LLM 的方法主要依赖于语言输入,这限制了它们整合驾驶所必需的丰富视觉特征的潜力。
VLM 通过整合语言和视觉进行多模态推理来解决这一差距,支持场景理解 [10, 21, 42, 49] 和数据生成 [24, 56, 64] 等任务。VLM 还用于统一导航和规划 [15, 29, 51, 53] 以及端到端自动驾驶 [27, 40, 55, 61]。然而,现有的基于 VLM 的方法通常需要大量特定领域的微调,这会显著增加计算成本和推理延迟。与我们在端到端自动驾驶中的方法密切相关,VLP [40] 将真值轨迹和边框标签转换为文本特征以进行对比学习,但它不会引入现有监督标签之外的信息。
多任务学习。多任务学习 (MTL) 通过单独的分支或头部使用共享表示联合执行多个相关任务。这种方法利用共享领域知识,增强特征鲁棒性和泛化能力,使其非常适合端到端自动驾驶。在 AD 系统中,通常采用辅助任务,例如语义分割 [9, 19, 23, 33, 60]、深度估计 [33, 60]、高清制图和 BEV 分割 [8, 25, 47, 48, 63] 来提取后续对象的有意义的感知表示。除了视觉任务之外,其他方法 [22, 59] 还可以预测额外的交通信号灯状态或控制信号,以提高驾驶性能。
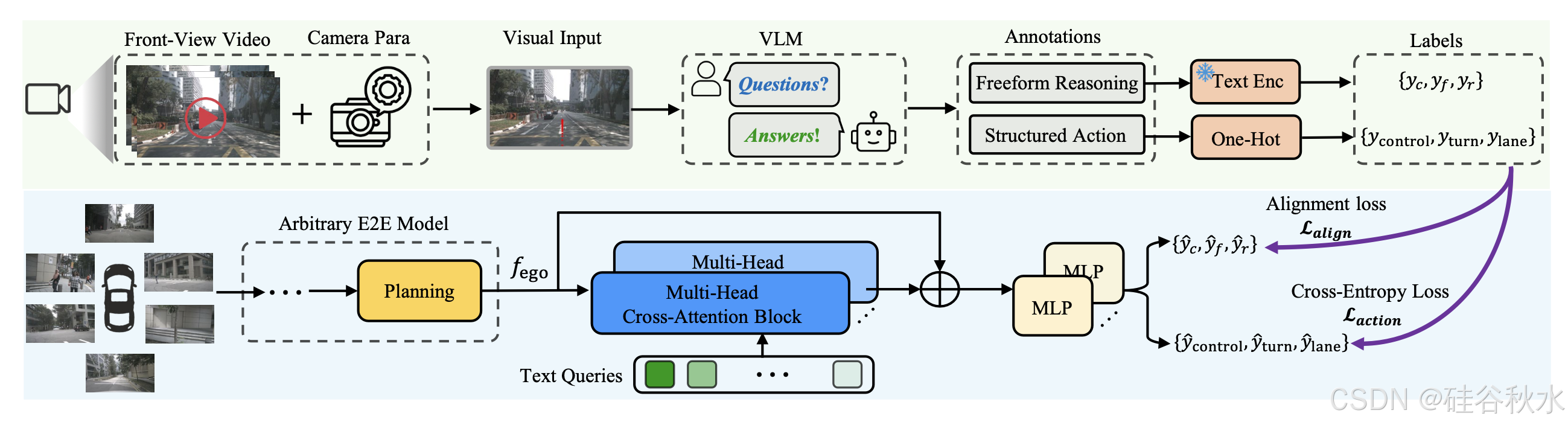
如图所示概述 VLM-AD 框架,该框架由两个主要组件组成。第一个是注释分支,利用 VLM 生成附加信息,创建作为监督的补充数据集。第二个组件是辅助头,旨在与这种额外的监督保持一致,并且可以有效地集成到规划模块之后任何 E2E 模型中。
VLM 文本注释
如图所示说明了注释过程,其中利用 VLM 作为老师,用附加信息丰富数据集,利用其从视觉输入推理的能力来加深 E2E 模型对驾驶行为的理解。注释过程可以定义为:A = M(P, V),其中 M(·) 表示 VLM 模型,P 表示语言提示,V 是视觉输入,A 是模型的自然语言输出,作为数据集的注释。目标是提供从自车的摄像头捕获图像以及专门制作的提示,以利用其广泛的世界知识从 VLM 获得详细的信息响应。

在工作中,用 GPT-4o [2],一种在互联网规模数据上训练的高性能 VLM,来自动注释数据集。GPT-4o 可以解释场景,生成合适的基于推理响应,并在复杂场景中准确识别自车的行为。
为了最大限度地发挥 VLM 的推理能力,在提出具体问题之前提供详细的上下文描述作为初步指导。具体来说,上下文和问题定义如下:
C/1:这是自车的前视图。红线表示未来轨迹,没有线表示停止或减速。解释推理时,请关注摄像头图像和周围环境,而不是参考绘制的轨迹。
Q/1-1:请描述自车当前的动作。
Q/1-2:请预测自车的未来动作。
Q/1-3:请解释当前和未来行动的推理。
完整的输入提示定义为 P/1 = [C/1, Q/1],其中 Q1 表示问题集,Q/1 = {Q/1-1, Q/1-2, Q/1-3}。这些开放式问题产生了自由形式的文本注释,描述了自车的当前状态、预期的未来行动以及 VLM 知识背后的推理。
为了检验方法的灵活性,以结构化格式定义第二种类型的问题。具体来说,创建三个不同的动作集,并提示 VLM 从这些预定义选项中选择答案。这能够为每个问题获得单个动作注释。具体来说,上下文和问题定义如下:
C/2:这是自车的前视图。红线表示未来轨迹,没有线表示停止或减速。
Q/2-1:请从控制动作列表中描述自车的动作:{直行、慢行、停止、倒车}。
Q/2-2:请从转弯动作列表中描述自车的动作:{左转、右转、掉头、无}。
Q/2-3:请从车道动作列表中描述自车的动作:{向左变道、向右变道、并入左车道、并入右车道、无}。
完整的输入提示定义为 P/2 = [C/2, Q/2],其中 Q/2 表示结构化动作问题集,Q/2 = {Q/2−1, Q/2−2, Q/2−3}。这样,可以从 VLM 中获得三个具体动作。与自由格式文本注释相比,结构化注释的一个主要优点是它们可用于监督 E2E 驾驶模型以预测人类可解释的动作。
辅助头
通常,数据驱动的端到端自动驾驶方法 [18, 26] 专注于总结可学习的自车特征 f/ego 以产生规划结果,这对于生成可靠且准确的规划轨迹至关重要。此可学习的自车特征通过不同的网络从上游模块汇总有关自车的所有相关信息。在方法中,开发了使用此自车特征作为输入的辅助头,使模型能够从 VLM 的响应中提取知识。
注释编码。使用 Q/1 问题,获得三个文本响应,表示为 A/1 = {A/c,A/f,A/r},分别表示当前动作、未来动作预测和推理的描述。使用 Q/2 问题,从预定义集合中获得三个动作,表示为 A/2 = {A/control,A/turn,A/lane},分别对应于控制动作、转弯动作和车道动作。为了将这些注释转换为监督信号,应用两种不同的方法来生成两种相应的标签类型,有效地将它们作为监督集成到端到端自动驾驶流水线中。
对于 Q/1 中的自由格式文本注释,用现成的语言模型(例如 CLIP [45])将文本转换为特征表示。对于结构化答案,每个动作都被编码为一个 one-hot 标签。y/1 = CLIP(A/1),y/2 = One-Hot(A/2) 。
文本特征对齐。使用三个文本特征 y/1 = {y/c、y/f、y/r} 作为监督,开发一个以自车特征 f/ego 作为输入的特征对齐头。此设置类似于知识蒸馏 [16],其中特征对齐头学习与教师 VLM 提供的文本特征对齐。
在这个头中,初始化三个可学习的文本查询,q/1 = {q/c、q/f、q/r}。每个查询通过多头交叉注意 (MHCA) 块与自车特征 f/ego 交互,其中文本查询充当注意查询 q,而自车特征则同时充当K和V,从而生成更新的文本查询。然后,这些更新的查询与自车特征连接起来,形成此文本头的特征表示,随后通过 MLP 层处理以生成最终的特征对齐输出。该过程公式为:q‘/1 = MHCA(q, k, v),q = q/1, k = v = f/ego,fˆ/1 = MLP(q′/1 ⊕ f/ego)。其中 ⊕ 表示拼接,fˆ/1 = {f/c , fˆ/f, fˆ/r} 表示要与相应的 VLM 文本特征对齐的三个输出特征。注:使用三个独立的 MHCA 块,每个组件一个,使每个文本查询能够关注可以以文本形式表示的自车特征特定方面。
受到 DINO [1] 中控制特征向量平滑度和锐度的知识蒸馏方法启发,采用类似的策略对文本和具有不同温度参数的输出特征进行归一化,从而产生特征分布而不是原始特征值。这种调整使得输出特征和监督标签之间能够更好地对齐,从而提高知识蒸馏的对齐质量。注:不应用居中操作,因为认为监督用的是真值。
结构动作分类。用问题 Q/2 从 VLM 获得结构化动作标签 y/2 = {y/control,y/turn,yl ane}。然后,构建另一个以自车特征 f/ego 作为输入的动作分类头。与之前的特征对齐阶段类似,初始化三个可学习的动作查询 q/control、q/turn 和 q/lane,它们通过三个 MHCA 块与 f/ego 交互。在此设置中,每个动作查询都用作注意查询 q,而自车特征既用作K又用作V,从而生成更新的动作查询。然后,将这些更新的查询与自车特征连接起来,为动作分类头创建特征表示,并将其传递给 MLP 层,然后通过 Softmax 函数来生成动作预测。q‘/2 =MHCA(q,k,v),q = q/2, k = v = f/ego,fˆ/2 = MLP(q′/2⊕f/ego)。
辅助损失
在规划模块之后定义两个并行的辅助任务,以使模型能够从 VLM 中提取知识,并且总体训练损失定义为两个分量的加权和:L = λ/1 L/align + λ/2 L/action, 其中每个分量对应于一个不同的辅助文本头,在目标区域提供监督。
对于特征对齐,用交叉熵损失来对齐监督和输出特征,从而捕获文本传达的关键信息。对于动作分类任务,还应用交叉熵损失来确保准确分类。
用 UniAD1 和 VAD2 的官方代码,并遵循其官方实现中指定的超参数。对于提出的 VLM-AD,定义两个辅助任务头,每个任务头包含一个具有 8 个头和 3 个交叉注意层的 MHCA 块,并且为 Q1 和 Q2 分别设置 3 个文本查询。在训练期间,设置温度参数 τs = 0.1 和 τt = 0.04 来控制特征的锐度,并设置 λ1 = 1 和 λ2 = 0.1 来平衡 Lalign 和 Laction。所有模型均使用 PyTorch 框架 [41] 在 8 个 NVIDIA H100 GPU 上进行训练。
在 VLM-AD 方法集成到 UniAD [18] 中时,遵循 UniAD 中定义的联合训练协议。在第一阶段,使用 BEVFormer [34] 权重初始化模型,并训练感知和映射任务 6 个epochs。在第二阶段,冻结图像主干和 BEV 编码器,并使用提出的 VLM-AD 方法进行 20 个epochs的端到端训练。该模型使用 2 × 10−4 的初始学习率、0.1 的学习率乘数和 AdamW 优化器 [37] 进行训练,权重衰减为 0.01。
在 VLM-AD 方法集成到 VAD [26] 中时,采用与其原始实现相同的超参数。该模型使用 AdamW 优化器 [37] 和余弦退火调度器 [38] 进行训练,权重衰减为 0.01,初始学习率为 2 × 10−4。
为了将自由格式注释编码为文本特征,用预训练的 CLIP-ViT-B/32 [45] 模型,维度为 512。此外,还尝试了其他文本编码器,如 T5-base [46] 和 MPNet-base [50],它们都将自由格式注释编码为维度为 768 的文本特征。

















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









