







论文:https://arxiv.org/pdf/2412.14446
0. 摘要
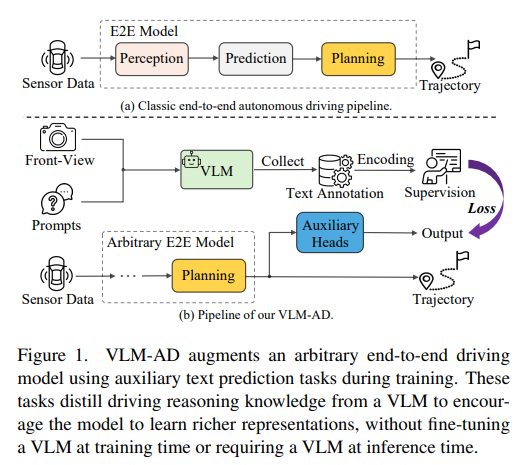
人类驾驶员依赖常识推理来应对复杂多变的真实世界场景。现有的端到端(E2E)自动驾驶(AD)模型通常被优化以模仿数据中观察到的驾驶模式,而没有捕捉到背后的推理过程。这一限制制约了它们处理具有挑战性的驾驶场景的能力。为了弥补这一差距,我们提出了VLM-AD,这是一种利用视觉-语言模型(VLMs)作为教师来增强训练的方法,通过提供额外的监督,结合非结构化推理信息和结构化动作标签。这种监督增强了模型学习更丰富的特征表示的能力,这些特征表示能够捕捉驾驶模式背后的理由。
重要的是,我们的方法在推理时不需要VLM,使其适合实时部署。当与最先进的方法结合时,VLM-AD在nuScenes数据集上实现了规划精度的显著提高和碰撞率的降低。
1. 创新点
1.1 知识蒸馏与特征表示学习
VLM-AD在知识蒸馏与特征表示学习方面做出了显著的创新与贡献。通过利用视觉语言模型(VLM)作为教师模型,VLM-AD能够将VLM中蕴含的丰富推理知识和语义信息有效地传递给端到端自动驾驶模型,从而显著提升后者的特征表示能力和决策性能。
- 知识蒸馏机制:VLM-AD采用了独特的知识蒸馏方法,将VLM生成的自由形式推理注释和结构化动作注释作为额外的监督信号,融入到端到端自动驾驶模型的训练过程中。这种蒸馏机制使得自动驾驶模型不仅能够学习到传统的轨迹监督信息,还能够吸收VLM所提供的深层次推理知识,从而更好地理解驾驶场景中的各种因素及其相互关系。例如,在nuScenes数据集上的实验表明,经过VLM-AD训练的模型在面对复杂场景时,能够更准确地识别潜在的风险和机会,做出更合理的决策,这正是知识蒸馏效果的直接体现。
- 特征表示学习:借助VLM的指导,VLM-AD显著增强了端到端自动驾驶模型的特征表示学习能力。模型能够学习到更丰富、更细致的特征表示,这些特征不仅涵盖了视觉信息,还融合了语言知识和推理逻辑。具体来说,VLM-AD通过文本特征对齐和结构动作分类等辅助头设计,使得自动驾驶模型的内部特征表示与VLM提供的文本特征和动作标签进行有效对齐和匹配。这种对齐过程促使模型关注那些对驾驶决策至关重要的特征,从而提高了模型对驾驶环境的感知和理解能力。实验结果显示,经过VLM-AD训练的模型在特征空间中能够更清晰地区分不同的驾驶场景和动作,为准确的决策提供了坚实的基础。
1.2 实时部署的可行性
VLM-AD在保证模型性能提升的同时,充分考虑了实时部署的可行性,这是其另一大创新与贡献所在。与一些依赖大型基础模型进行实时推理的方法不同,VLM-AD巧妙地将VLM的推理过程仅限于训练阶段,而在推理阶段则完全不依赖VLM,从而显著降低了推理成本和延迟,使得模型能够满足实时自动驾驶应用的要求。
- 推理效率优化:在VLM-AD的设计中,通过一系列优化措施,如多头交叉注意力机制的高效实现、特征归一化策略的合理应用等,提高了模型在推理阶段的计算效率。这些优化措施使得模型能够在有限的计算资源下,快速地处理输入数据并生成准确的决策输出。例如,在实际的自动驾驶场景中,VLM-AD能够在毫秒级的时间内完成对复杂交通环境的感知、理解和决策规划,为车辆的实时控制提供了有力支持。
- 硬件兼容性与资源利用:VLM-AD还考虑到了与现有自动驾驶硬件平台的兼容性。由于在推理阶段不依赖VLM,模型可以更容易地部署在各种计算资源受限的车辆环境中,如仅配备中等性能GPU或专用自动驾驶芯片的车辆。此外,VLM-AD对计算资源的高效利用也降低了系统的功耗和成本,提高了自动驾驶系统的整体性价比。这使得VLM-AD不仅在技术上具有创新性,而且在实际应用中具有很高的可行性和推广价值,为自动驾驶技术的大规模商业化应用奠定了基础。
2. VLM-AD方法概述
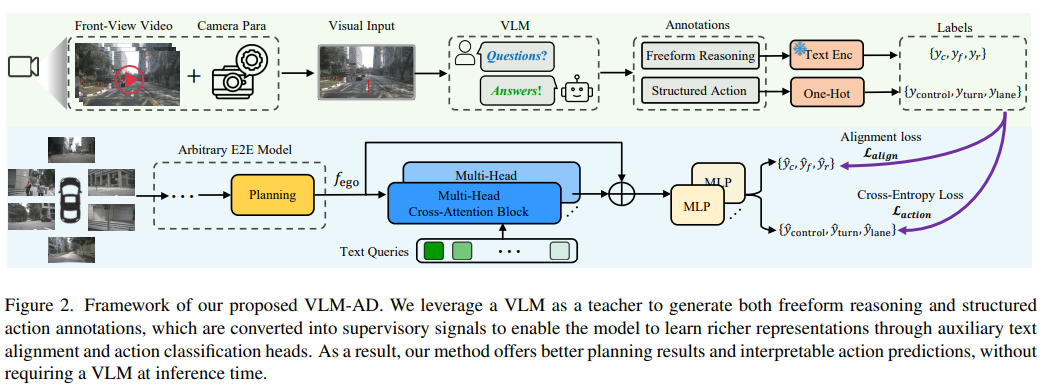
2.1 VLM作为教师模型的角色
VLM-AD方法中,视觉语言模型(VLM)扮演着至关重要的教师模型角色。VLM通过其强大的多模态处理能力,能够将视觉信息与语言知识相结合,为自动驾驶模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









