







原文:Stefan Leutenegger, Margarita Chli et al.《BRISK: Binary Robust Invariant Scalable Keypoints》
BRISK
摘要:从一幅图片中高效地寻找关键点始终是一个深入研究的话题,以此形成了众多的计算机视觉应用的基础。正在这个领域中,先驱算法SIFT和SURF在各种图形转换中表现出了巨大的性能,特别是SURF在日益更新的高性能方法中被认为是计算最有效的方法。本文提出的BRISK算法是用于关键点检测,描述和匹配的一种新方法。在基准数据库中队BRISK的综合评价为:自适应和在大大降计算低成本下所表现的高质量的性能(这一些情况下,计算速度要比SURF快一个数量级)。速度的关键在于一种新的尺度空间的应用:基于FAST的检测器结合组装好的一位串描述子,该描述子从每个关键点附近专门取样的强度比较检索得到的。
1.引言
将图像分解为本身感兴趣区域或特征区域是一种在计算机视觉中广泛应用的技术,用来降低当寻找原图像表面特征的复杂度。图像表示﹑目标识别﹑匹配﹑三维场景重建以及运动跟踪都依赖于图像中稳定的具有代表性的特征,这个问题促进了研究并产生了大量的方法。
理想的特征点检测器发现突出的图像区域,这样以来尽管其角度变化,它们也可以重复检测特征点;更一般的是对于所有可能的图像转换它都得是稳健的。同样地,理想的关键点检测器捕捉了最重要和独特的信息内容,这些内容包含在检测到的突出区域,这样的话,如果遇到相同的结构区域也可以被识别出来。此外,在满足这些属性来实现所需的关键点的质量,检测器和描述子的速度同样需要优化来满足手头任务的时间约束。
在原则上,最先进的算法目标在于即应用于严格要求的实验精度也应用于计算速度。Lowe’ 的SIFT 算法是一个目前被广泛接受的最高质量的选择,对各种常见的图像转换具有有效的特殊性和不变性,然而,这种算法以计算代价为成本。在另一方面,FAST关键点检测器和BRIEF方法的结合对描述子提供了更实时应用的选择。然而尽管速度拥有明显的优势,但就可靠性和稳健性而言后一种方法更易接受,因为它具有最小的图像扭曲和旋转的承受度,尤其在平面旋转和尺度变换上更明显。结果,像SLAM这样的试试应用程序需要对数据关联运用概率性的方法来找到匹配一致性。
从图像中提取合适的特征点的内在困难在于平衡两个相互矛盾的目标:高质量的描述子和低计算需求。这就是这项工作的目的,即用BRISK方法建立一个新的里程碑。也许最相关的任务是解决这个问题:SURF已经演示了稳健性和速度的实现,只是,要得到的结果很明显,在花费更少的计算时间BRISK获得了更可观的匹配效果。简而言之,本文对从图像中得到特征点提出了一个新的方法,得到的要点如下:尺度空间特征点检测:图像和尺度维度都是通过使用一个显著性的标准来识别感兴趣特征点。为了提高计算效率,在图像金字塔的octave层和层于层的中间检测特征点。通过在连续域拟合二次函数来获得每个关键点的位置和尺度。关键点检测:由点组成的样本模式位于比例合适的同心圆上,在每一个关键点的相邻位置使用该圆来检测灰度值:就地处理强度梯度,决定了特征描述方向。最后,面向BRISK 的采样模式用于获得成对的亮度对比结果,将结果组合成二进制BRISK描述子。
BRISK关键点一旦生成由于描述子的二进制本质特点就可以非常高效的匹配。强烈注意一下其计算速度,BRISK还利用存储SSE指令在今天的架构中提供了广泛的支持。
2.相关工作
在文献中质量最近最好的特征点提取方法是SIFT。高描述力和鲁棒性来启发和观点改变使得评价SIFT描述子在调查中处于最高位置。然而,这种描述子使得SIFT的高维度提取速度非常慢。PCA-SIFT 使得描述子从128维降到了36维,但是,影响其特殊性和增加描述子形成的时间几乎使得增加匹配速度的性能毁于一旦。这里值得注意的是,GLOH描述符也属于类SIFT方法家族,也已经证明其具有独特性但是比SIFT要付出更多昂贵的计算。
对特征提出日益增长的高质量和高速度的需求已使得更多的算法研究能够以更高的速率处理大量的数据。值得注意的是,Agrawal等人用中心对称的局部二值化模式作为另一个SIFT方向直方图的方法。最近的BRIEF算法是超高速描述符,匹配以及二进制串的组合设计的,包含了简单的图像增强在随机预定的像素位置的比较。尽管这种方法简单并且有效,但其对图像旋转和尺度变换非常敏感,以此限制了其通用功能的应用。
可能目前最吸引人的特征点提取方法是SURF,它已被证实比FAST 速度明显快很多。SURF特征点检测使用了Hessian矩阵(blob检测器)的行列式,而其描述符是总结了Harris小波在感兴趣区域的响应。SURF展示了令人深刻的最先进的计时,在速度方面,数量级仍然是远远不够最快的,目前这些限制了其提取特征点的质量。
本文提出了一种新颖的算法称为BRISK,其具有高性能,快速的特征点检测和描述符以及快速匹配。意如其名,该方法在很大程度上具有旋转不变性和尺度不变性,实现了高性能和最先进的同时极大地降低了计算成本。下面的特征描述子的方法是,目前在基准数据库执行的实验结果和使用标准化的评价方法。即提出了关于SURF和FAST的BRISK评价,这被广泛地接受为在常见的图像转换领域内的比较准则。
3.BRISK
3.1 尺度空间的检测
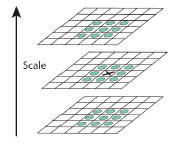
注重计算效率,特征检测方法是Mair等人对图像感兴趣区域检测时的工作启发。他们的AGAST本质上是现在流行的FATS算法性能的扩展,被证明是特征提取的一个给出有效的基础。实现尺度不变性的目标对高质量的关键点是至关重要的,为了进一步得到极大值,不仅要在图像平面上研究,而且在尺度空间使用FAST分数作为精确地测量。尽管在粗轴上离散化尺度轴比选择高性能检测器更难,但BRIEF检测器估计了在每一个连续的尺度空间的每一个特征点的真实值。
在BRIEF的框架中,尺度空间金字塔的组成是n个octave层(用ci表示)和n个intra-octave层(用di表示),文章中n=4,i={0,1,...,n-1}。假设有图像img,octave层的产生:c0层就是img原图像,c1层是c0层的2倍下采样,c2层是c1层的2倍下采样,以此类推。intra-octave层的产生:d0层是img的1.5倍下采样,d2层是d1层的2倍下采样(即img的2*1.5倍下采样),d3层是d2层的2倍下采样,以此类推。则ci、di层与原图像的尺度关系用t表示为:,
这里重要的是要注意FAST和AGAST都为特征点检测的掩膜形状提供了不同的选择。在BRISK中,主要使用了9-16个掩膜,即在16像素的圆中至少需要9个连续的像素来提供足够亮或暗的像素来实现,相比于FATS标准的中心像素的实现。
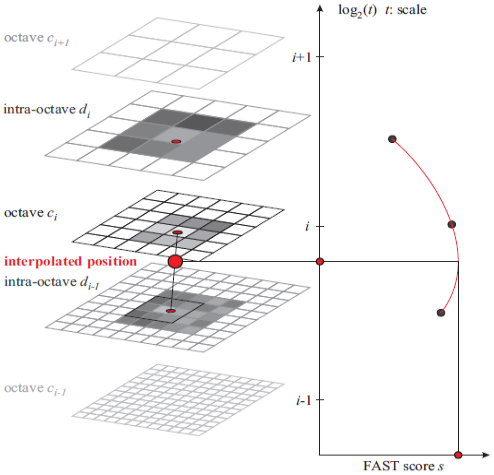

开始时,FAST 9-16 检测器在每一个octave层和octave层分别使用相同的阈值T来识别潜在的感兴趣区域。接着,属于这些感兴趣区域的点在尺度空间上进行非极大值抑制(同SIFT算法 的非极大值抑制):首先,问题是特征点需要在每一层的FAST得分值s的8邻域内实现最大值条件。分值S定义为在一幅图像的块区域的点的最大阈值。其次,每一层及其上下层的得分值也要尽可能的低。检查同样大小的正方形邻域:在每一层中内部边长为2个像素的最可能是最大值。因为相邻层(因此其FAST的得分)代表有不同的离散化,对其邻域边界进行一些插值。图1描述了这个过程采样和极大值检测的一个例子。
尺度轴在octave c0层的最大值检测是一个特例:为了获得FAST分数,因为c0层是最底层,故需虚拟有一个d-1层,在c0上使用FAST5-8。然而,在这种情况下,d-1层patch的分数需要比检测的octave c0的特征点低。
考虑到图像的特点作为一个连续数字化不仅在图像上也在尺度维度上,为每一个检测到的最大值执行亚像素插值和持续的进行。为了限制细化过程的复杂性,首先,满足一个二维最小二乘意义上的二次函数使得每3个score-patches(获得该层和上下两层的关键点)得到3像素突出最大值。为了比较重复采样,考虑在每一层采用3x3的得分patch。接下来,这些突出的score用合适的一维曲线沿着尺度轴生成最后的得分估计和其最大值的尺度估计。最后一步,重复对图像坐标在该层及邻边决定性尺度进行插值。BRISK检测在Boat序列的两幅图中是近距离的的一个例子如图2所示。
3.2 特征点描述
给定一组特征点(包含亚像素插值图像位置和相关浮点型点的尺度值),BRISK描述子是由二进制串通过间接简单的亮度比较测试的结果组成。这种观点已证实是非常有效的,然而在这里使用更多的定性模式。在BRISK中,确定了每个特征点的特征方向以便得到方向均衡化的描述子,因此,实现旋转不变性是一般鲁棒性的关键。同时,精心选择了注重描述最大化的亮度比较。
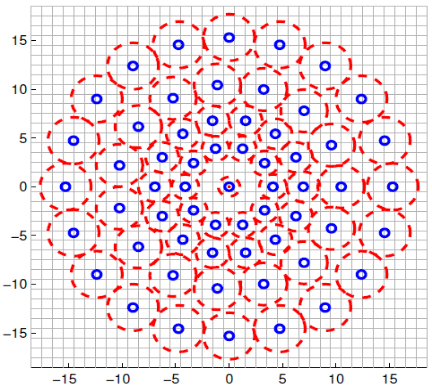
3.2.1 采样模式和旋转估计
BRISK描述子关键的概念是利用采集关键点相邻位置所使用的模式。该模式如图3所示,以关键点为中心,在其周围采集N个特征点的圆,定义多个相等局部圆形区域。这种模式类似于DAISY描述符,重要的是要注意到在BRISK中所使用的是完全不同的,DAISY专门为密集匹配建立的,刻意地捕捉更多的信息,因此,要求速度和存储需求。
为了避免混叠效果,对在模式中的采样点Pi应用了高斯平滑,标准差δi正比于每个采样点对应于各自中心的距离,定位和扩展模式在图像中相应地为关键点k模式化,考虑一个N(N-1)/2个采样点对,用集合(Pi,Pj)表示。这些点的平滑像素值分别为I (Pi , σi ) 和I (Pj , σj ),用于估计局部梯度值g(Pi , Pj ) 的公式为:
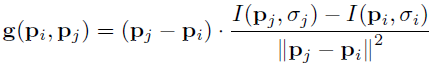
所有组合方式的集合称作采样点对,用集合表示为:
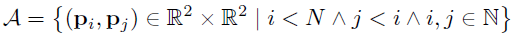
定义短距离点对子集S、长距离点对子集L(L个)为:
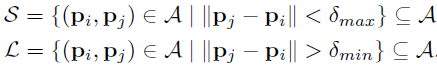
其中,阈值距离设置为:δmax=9.57t,δmin=13.67t,t是特征点k所在的尺度。
现在要利用上面得到的信息,来计算特征点k的主方向(注意:此处只用到了长距离点对子集),如下:
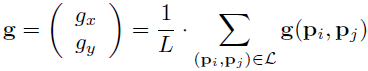
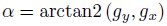
长距离的点对都参与了运算,基于本地梯度互相抵消的假说,所以全局梯度的计算是不必要的。这一点同时也被距离变量阈值δmin 的实验确认了。
3.2.2 创建描述子
对于旋转和尺度归一化的描述子的建立,BRISK使用了关键点k周围的抽样点旋转α = ARCTAN2 (gy , gx )角度作为模式。和BRIEF类似,BIRSK的描述子也是一个包含512个比特位的向量,每个描述子由短距离点对(Pαi , Pαj ) ∈ S两两进行比较产生的,上标alpha表示旋转的模式。这样的每一位b对应于:
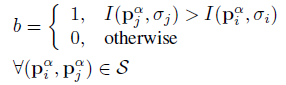
与BRIEF不同的地方是,BRIEF只是进行亮度比较,除了预设尺度和预先对样本模式的旋转之外,BRISK和BRIEF有着根本的区别:一.BRISK使用固定的样本模式点,而且是以R为半径围绕关键点周围的圆进行均匀取样。因此特定的高斯核平滑不会突然地扭曲亮度内容的信息(模糊邻近的两个采样点的亮度,从而保证亮度平滑过渡)二.与两两组成的点对比BRISK显著的减少了采样点的数量(例如,单个的样本点参与了更多的比较),限制了亮度查找表的复杂度三.这里的比较是受到空间的限制的,所以亮度的改变仅仅只是需要局部一致性就可以了。对于上面的采样模式和距离阈值,获得了一个长度为512个比特位串。BIRSK64的描述子也是一个包含512个比特位的向量,因此为一对描述子匹配将以同样的速度进行定义。
3.3 描述符匹配
匹配两个BRISK描述符是简单的计算他们在BRIEF中汉明距离:比特位数量是不同的两个描述符它们的衡量是不同的。注意他们各自通过位计数来减少按位操作的运算操作,在今天的架构中它们都可以非常有效地计算。
3.4 实现说明
这里,对一些方法实现的问题给出了一个简短的概述,这些问题对整体的计算性能和该方法的重现性具有显著的贡献。所有基于OpenCV的常见的二维特征点界面的BRISK功能都可以用存在的特征点提取算法(SIFT,SURF, BRIEF, 等等)简单的整合和互换。
为计算显著性得分检测过程使用了AGAST算法实现。非最大值抑制受益于早期的终止能力,以此限制了显著得分计算到最小值。建立图像金字塔使用了一些SSE2和SSE3指令,这两个指令都是关于半抽样以及下抽样的1.5倍。
为了有效地用采样模式检索灰度值,生成了一个离散旋转的和已尺度化的BRISK模式版本的查找表,包括取样点的位置和高斯平滑内核的属性以及长短距离配对的索引,这些消耗了大约40MB的RAM内存,所有这些仍然可接受受限的计算能力低的应用。另外,在一个简化的高斯内核版本使用积分图像,使用的激励该内核为:在没有任何增加计算复杂度的情况下改变σ时内核是可伸缩变换的。在最后的实现中,在浮点边界和边长为ρ = 2.6 · σ使用了一个简单的平方均值滤波器误差估计。因此,不需要在整幅图片中使用许多不同内核的高斯平滑来浪费时间,而是使用一个任意的参数σ检索单个值。本文还整合改进了SSE汉明距离的测量来实现目前OpenCV六倍的速度来实现匹配,例如带有BRIEF的OpenCV版本。
4 实验
本文提出的方法在广泛地测试后,现在在首先由 Mikolajczyk 和 Schmid提出的领域中建立了评价方法和数据库。为了在其他的工作提出一致性的结果,本文也使用了在线的MATLAB评价版本。每一个数据库包含了一个六个图像的序列,变现出越来越多的转换数量。这里所有的比较都在每一个数据库上对比第一张图片实现的。图4显示了一幅分析每个数据集的图片。

这个变换包含了角度改变(Graffiti 和 Wall),缩放和旋转(Boat),滤波(Bikes and Trees),亮度变化(Leuven),以及JPEG压缩(Ubc)。因为角度变化场景是平面的,相比于OpenCV2.2版本的SIFT和OpenCV初版的SURF,在所有序列的图像对上提供了一个地面真实的单一性矩阵用于BRISK的检测和描述器的展示。评估使用了相似性匹配,该匹配认为每对特征点的描述子距离都低于某个阈值匹配,例如相比于最近邻匹配,用最低的描述子距离来寻找数据库的位置。最后,展示了BRISK在属比较计时的计算速度方面的一大优势。
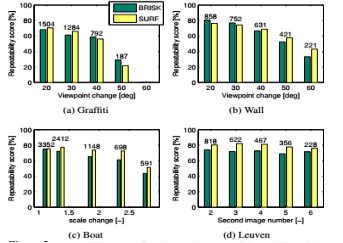
4.1 BRISK检测重复性
检测重复性定义为,在两幅图中计算相应的关键点和最小关键点的数量。相应标志是通过查看一幅图中关键点区域的重叠区域(即提取圆)和从其他图形中得到的关键点区域的投影:如果相交的区域大于共同区域的50%,就被认为是一个相应标志。用这种方法标记在很大程度上依赖于关键点圆形区域的工作,即尺度和半径之间的常数因子。像这样选择用BRISK检测器获得的平均半径和SURF和SIFT获得的平均半径大致匹配。
重复性评价得分(选择的结果如图5所示)在一个序列中实施使用连续的BRISK检测阈值。为了达到与SURF检测器相当的比较,选择使用了各自的Hessian阈值在相似的基本的匹配步骤下使其大概输出一样的相应标志数量。
如图5所示,BRISK检测器展示了和SURF一样的重复性只要应用的图像转换不是很大。然而鉴于在计算速度上BRISK比SURF更具有明显的优势,本文提出的BRISK方法成为了强有力的竞争对手,即使在大尺度变换上似乎也稍逊一筹。
4.2 总体评价和比较BRISK算法
因为任务的目的在于提供一个总体及速度快有具有健壮性的检测器,描述子和匹配,所以评估了BRISK中相比于SIFT和SURF的所有步骤的共同表现。图6 显示了在选择不同数据集的图像对,准确性-记忆曲线使用基于阈值的相似匹配。对这个评估又适应于检测阈值,以此输出一个在公平的意识下相应标志大致相等的数量。注意这里的评价结果与[3]中的不同,那里所有的描述子都是在相同的区域中提取的(用Fast-Hessian获得的)。
如图6 所示,BRISK在所有数据集上比SIFT和SURF更有竞争优势,甚至在一些情况下远远胜过其他两个。BRISK在树的数据集上的降低性能是由于检测器的性能:当SURF检测到2606和2624图像区域时,BRISK在图像4中只检测到2004个图像区域,相比于在图片1中找到5949个图像区域,实现了相应标志的大致相等的数量。这样的方法同样适用于其他的滤波数据集,Bikes:FAST的突出本质上比其他的类blob检测子更敏感。因此,显示了从SURF区域中为树的数据集提取BRISK描述子的评价。
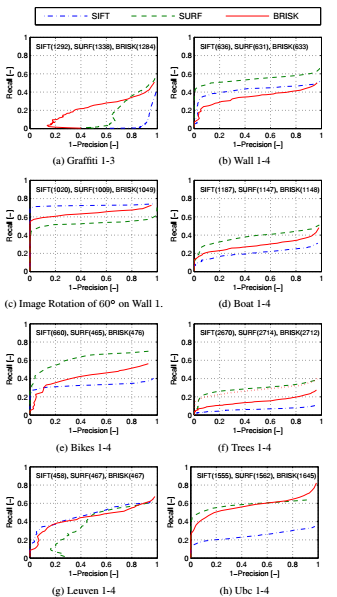 图6
图6
显然,SIFT在图Trees, Boat, 和Ubc datasets中的性能明显恶化,这可以解释在这些情况下检测器重复性受限的原因。另一方面,SIFT和BRISK处理纯平面旋转的重要情况很好,比SURF更好。
为了完成实验的这个部分,联系到了BRIEF算法。图7 显示了不具有旋转的单尺度的BRISK版本(SU-BRISK)和64字节的BRIEF特征点在相同的(单尺度)AGAST特征点上的比较。还包括了旋转不变性,单尺度的BRISK(S-BRISK)以及标准的BRISK。实验用两幅图像对进行:一方面使用了前两幅图片,在图Wall数据集中证明SU-BRISK和BRIEF64在没有单尺度和平面旋转的情况下都表现出非常相似的性能。注意到,BRIEF算法设计的真实条件。另一方面,应用不同的版本到图Boat序列的前两幅图片:本次试验显示了一些就小规模旋转和尺度变化的鲁棒性而言SU-BRISK比BRIEF更让你更具有优势。此外,众所周知的和明显代价的旋转和尺度不变性是很容易观察到的。
4.3 时间安排
时间控制已经记录在配备四核i7 2.67 GHz处理器(虽然只用了一个核)运行Ubuntu 10.04 (32位)的笔记本电脑中,使用了上面详细的实现和设置过程。表1 给出了有关在图Graffit序列的第一幅图片的检测结果,而表2 显示了匹配时间。运行平均值超过了100次。注意到,所有的匹配器在没有任何提前终止优化的前提下都做了暴力描述符距离计算。
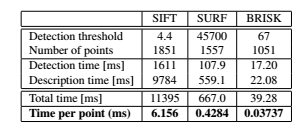
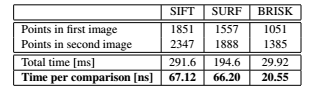
计时显示了BRISK的一个明显的优势,它的检测盒描述子的计算通常比SURF的速度快一个数量级,这被认为目前存在的最快的具有旋转不变性和尺度不变性的特征点匹配。同样重要的是,要强调BRISK可以容易更快地执行尺度化,通过在以匹配质量为代价的模式下减少采样点的数量,这是一个特定的应用下可能承担得起。此外,尺度或旋转不变性可以省略,在不需要的应用上增加速度和匹配质量。
4.4 例子
对以上的提出补充广泛的评价,也提供了一个使用BRISK作为匹配的真实例子。图8显示了一幅图像对展现了各种变换。一个阈值为90的相似性匹配在没有明显的异常值得情况下得到的鲁棒性匹配(超过512对特征点)。
 图7
图7
5 结论
本文提出了一种新颖的方法称之为BRISK,解决了经典的计算机视觉的检测问题,在现场和照相位置没有足够的先验知识下描述和匹配图像关键点。相比之下,与已建立且证明具有高性能的算法如SIFT和SURF相比,本文的方法实在地提供了一个戏剧性更快的按可比的匹配性能的选择,基于一个广泛评价的一份声明中使用既定的框架。BRISK依赖一个简单地可配置的圆形的采样模式,模式从它形成一个二进制描述符字符串计算亮度的对比。BRISK的独特特性可用于广泛的应用,特别是对硬实时约束或有限的计算能力。最后,BRISK在费时的应用中提供了高端的特征点质量。
在对BRISK进一步研究的道路上,目标是探索能替代尺度空间最大值收索突出得分到生成更好高的可重复性,同时保持速度。此外,目标在于分析理论和实验上的BRISK模式和配置的比较,这样的描述子的信息内容或鲁棒性是最大化的。

















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









