






小样本学习+CLIP太好发文了,光是CVPR24就有多篇了!像是在100%噪声标签比例情况下,识别准确率依然出色的DeIL模型;性能远超SOTA的Transductive-clip模型……
主要在于:一方面,小样本学习一直是研究的热门,但也面临数据稀缺的困扰。而CLIP强大的跨模态表征能力,则能提供丰富的信息来源,助力模型提高准确性。且CLIP作为一个预训练好的多模态模型,已经包含了丰富的知识,通过微调少量的参数,便能来适应新任务,大大减少训练时间和资源消耗。另一方面,该思路目前还在上升期,还不算卷。在医疗诊断、自动驾驶、机器人交互等领域都有着广泛应用,创新机会很多。
为让大家能够紧跟领域前沿,早点发出自己的顶会,我给大家准备了11种创新思路和源码,一起来看!
论文原文+开源代码需要的同学看文末
Fully Fine-tuned CLIP Models are Efficient Few-Shot Learners
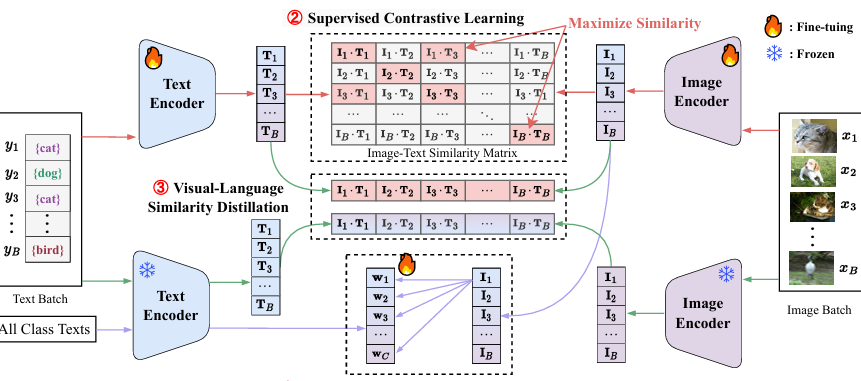
内容:本文提出了CLIP-CITE,这是一种针对CLIP模型的微调方法,旨在有限监督下提升其在特定任务上的专业性,同时保持在其他数据集上的通用性。该方法通过设计判别性视觉-文本对齐任务、监督对比学习以及视觉-语言相似性蒸馏技术,有效缓解了过拟合和灾难性遗忘问题。在少样本学习、基础到新任务泛化、领域泛化和跨领域泛化等设置下的广泛实验结果表明,CLIP-CITE在特定任务上取得了卓越性能,同时保留了CLIP模型的多功能性。
Domain Aligned CLIP for Few-shot Classification
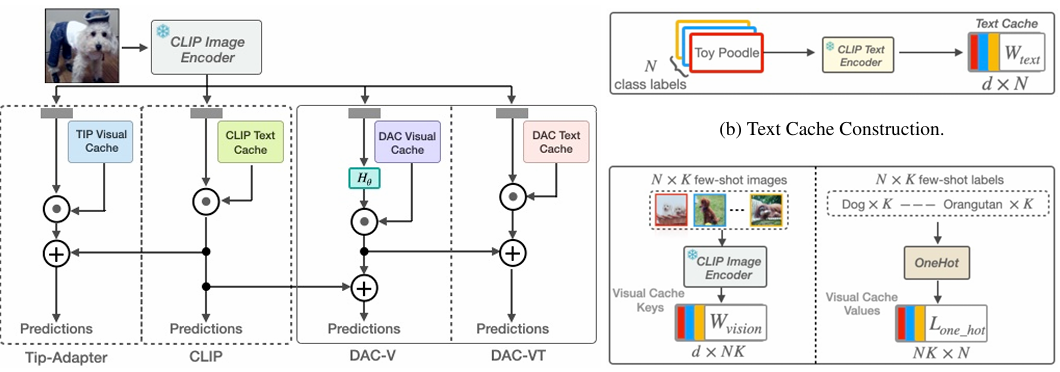
内容:本文介绍了一种名为Domain Aligned CLIP(DAC)的样本高效领域适应策略,用于提升CLIP模型在少样本分类任务中的性能。DAC通过引入轻量级适配器和优化预计算的类别文本嵌入,分别改善了CLIP在目标分布上的 intra-modal(图像-图像)和 inter-modal(图像-文本)对齐,而无需微调主模型。实验表明,DAC在11个图像分类任务上平均提升了2.3%的16-shot分类性能,并在4个OOD鲁棒性基准上展现出竞争力。
Learning to Adapt CLIP for Few-Shot Monocular Depth Estimation
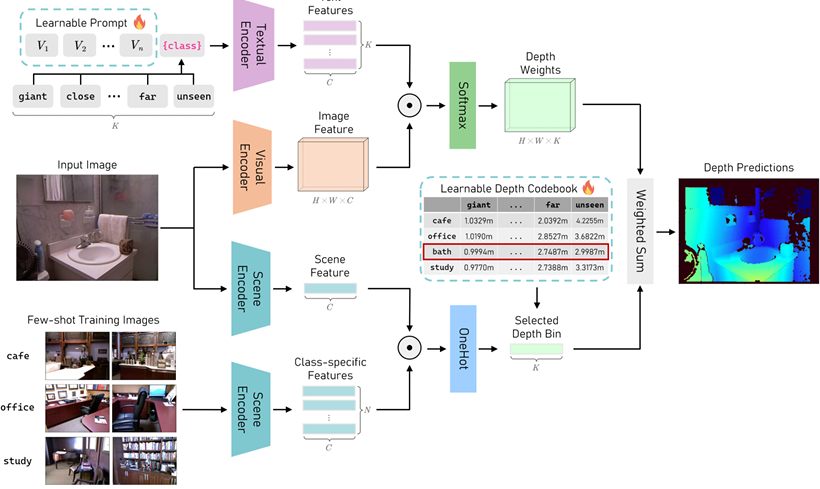
内容:本文提出了一种基于少量样本的学习方法,用于适应预训练的视觉-语言模型CLIP进行单目深度估计。该方法通过为不同场景分配不同的深度箱(depth bins),并在推理过程中由模型选择,以平衡训练成本和泛化能力。此外,还引入了可学习的提示(prompts)来预处理输入文本,将易于人类理解的文本转换为模型易于理解的向量,进一步提升性能。在NYU V2和KITTI数据集上的实验结果表明,仅使用每个场景的一张图像进行训练,该方法的性能超过了以往的最佳方法,最高达10.6%的提升。
AMU-Tuning: Effective Logit Bias for CLIP-based Few-shot Learning
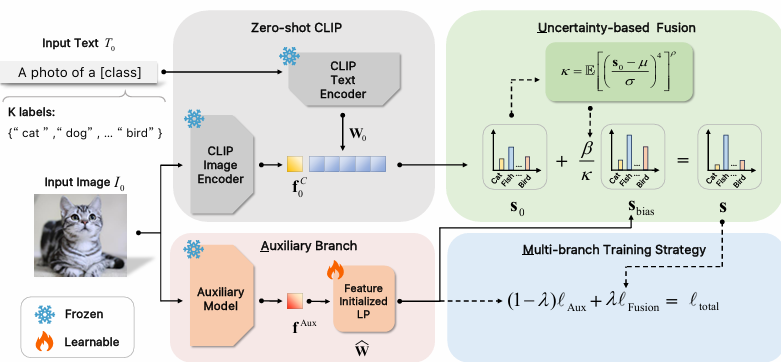
内容:本文提出了一种名为AMU-Tuning的新方法,用于基于CLIP的少样本学习。该方法通过分析现有方法,从逻辑偏差(logit bias)的角度出发,提出了一个统一的公式来改进CLIP在少样本学习中的性能。AMU-Tuning通过利用辅助特征、多分支训练的特征初始化线性分类器以及基于不确定性的融合策略来学习有效的逻辑偏差。在多个基准测试上的实验结果表明,AMU-Tuning在性能上超越了现有的方法,并且在计算成本上更为高效。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【小样本结合】获取完整论文
👇

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









