






交叉注意力机制+多模态,是当前非常热门,且可挖掘的创新点很丰富的方向。
交叉注意力机制动态对齐不同模态信息的特点,能够克服多模态最大的挑战之一。因而,该思路备受审稿人青睐,在各顶会录用量不断飙升。同时,这一特点,也能有效提升模型对复杂数据的理解能力。机器翻译、视觉问答、医疗诊断等领域,都离不开它。结合不同的场景,就能做微创新。比如模型LV-XATTN,便实现了速度提高45.85倍的效果……
此外,交叉注意力机制本身也自带创新基因,通过改进特征对齐方式(多头注意力、双向注意力)、结合新的模态数据(如脑电信号、传感器数据)、设计轻量化架构(如动态融合)就能实现创新。
为让大家能够获得更多灵感启发,早点发出自己的顶会,我给大家准备了15种创新思路,原文和源码都有。
论文原文+开源代码需要的同学看文末
Enhancing Multimodal Sentiment Analysis for Missing Modality through Self-Distillation and Unified Modality Cross-Attention
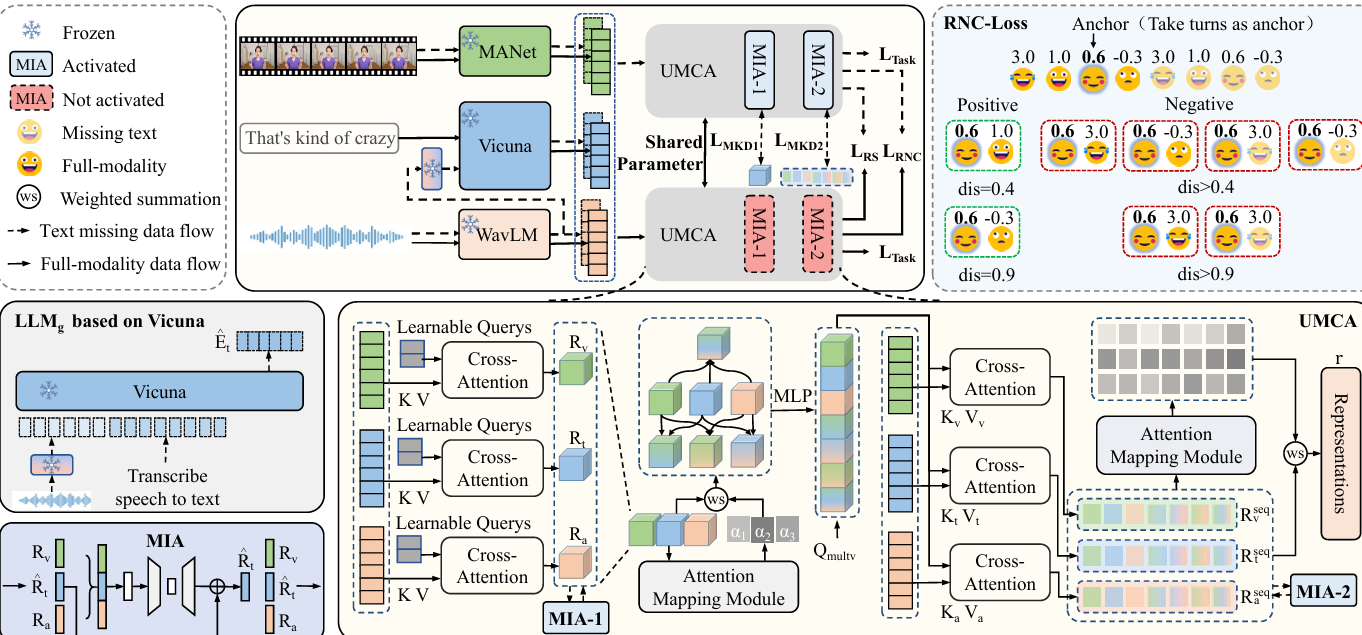
内容:本文提出了一种用于多模态情感分析的双流自蒸馏框架,通过统一模态交叉注意力(UMCA)和模态想象自编码器(MIA)模块,有效处理文本模态缺失的情况。该框架利用基于LLM的模型从音频模态生成模拟文本表示,并通过MIA补充信息以接近真实文本表示。此外,引入了Rank-N对比损失函数以对齐模拟和真实表示,并在CMU-MOSEI数据集上取得了优异的性能,尤其是在文本模态缺失时的表现显著优于其他方法。
SAISA: Towards Multimodal Large Language Models with Both Training and Inference Efficiency
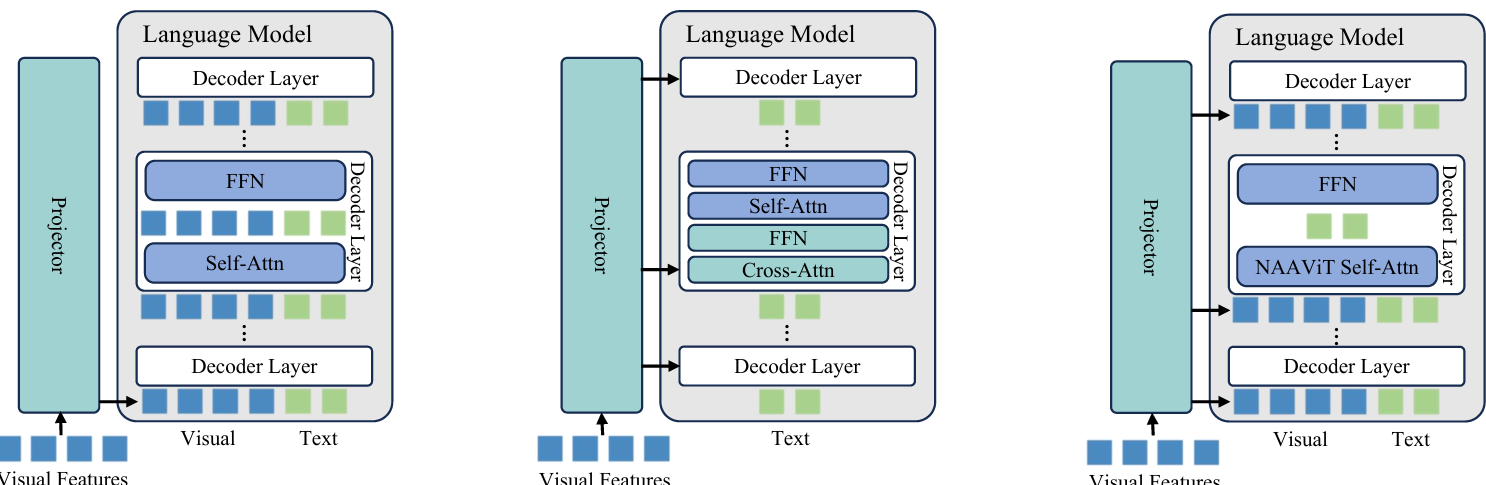
内容:本文提出了一种名为 SAISA的新型多模态大语言模型(MLLM)架构,旨在同时提高训练和推理效率。通过对现有 MLLM 架构的分析,作者发现当前方法在训练和推理效率之间存在权衡:嵌入空间对齐(如 LLaVA-1.5)在推理时效率低下,而交叉注意力空间对齐(如 Flamingo)在训练时效率低下。为此,作者提出了 NAAViT(No Attention Among Visual Tokens)自注意力机制,通过消除视觉 token 之间的注意力来减少计算冗余,并基于此设计了 SAISA 架构。
Multimodal Remote Sensing Scene Classification Using VLMs and Dual-Cross Attention Networks
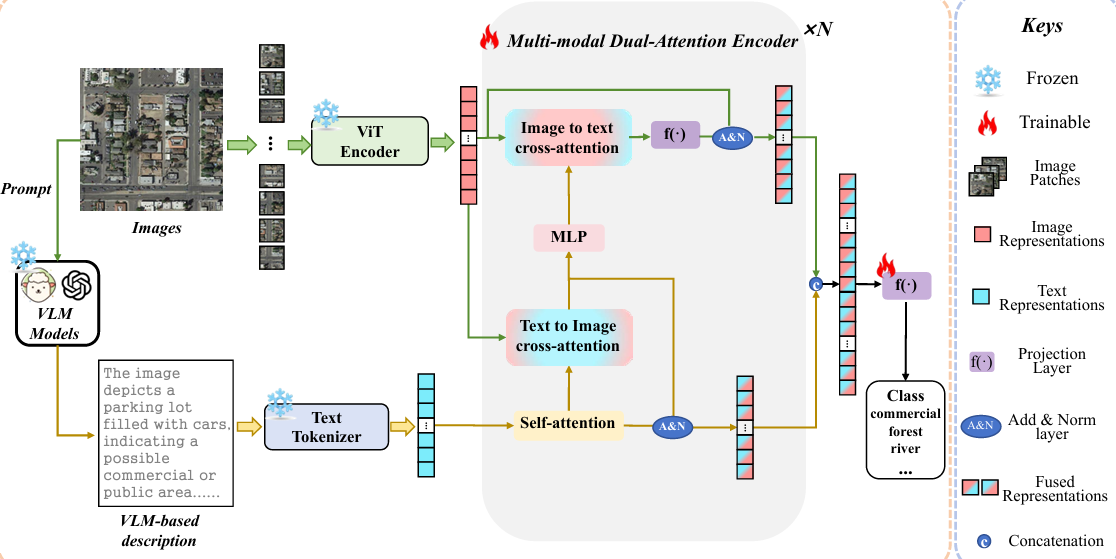
内容:本文提出了一种基于多模态的遥感场景分类框架,利用大型视觉语言模型(VLMs)生成的文本描述作为辅助模态,无需人工标注即可增强分类性能。研究中引入了双交叉注意力网络,通过融合视觉和文本数据的互补信息,生成统一的场景表示。通过在五个遥感场景分类数据集上的实验,该框架显著优于基线模型,并验证了VLM生成文本描述的有效性。此外,该研究还展示了多模态表示在零样本分类中的潜力,为未来遥感场景分类任务中利用文本信息提供了新的思路和方法。
FigCLIP: A Generative Multimodal Model with Bidirectional Cross-attention for Understanding Figurative Language via Visual Entailment
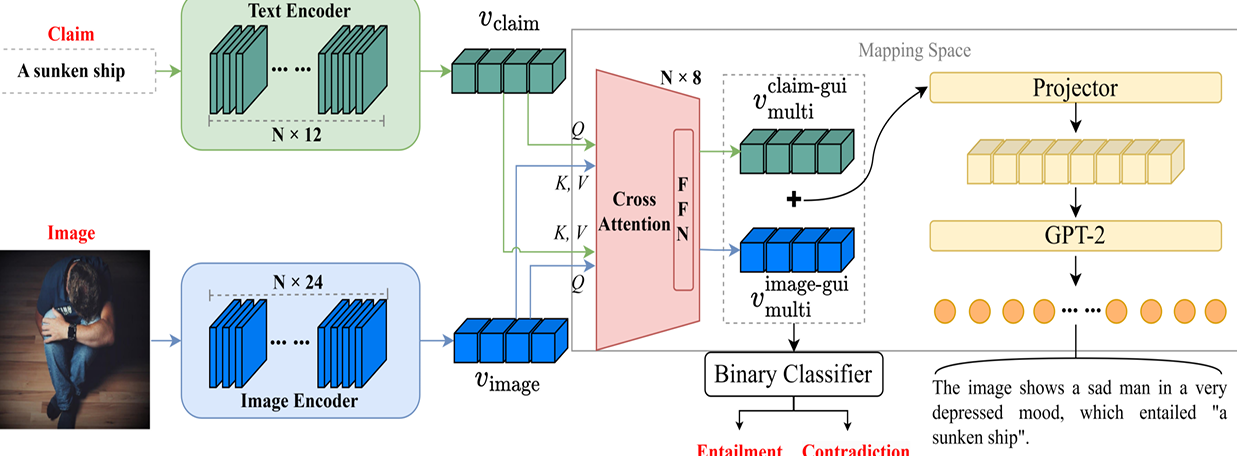
内容:FigCLIP 是一种用于理解比喻语言的生成式多模态模型,通过双向交叉注意力机制结合视觉和语言信息,以实现视觉蕴含任务。它在视觉和语言之间建立了紧密的联系,使得模型能够更好地理解和生成与图像相关的文本描述。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【交叉多模】获取完整论文
👇

















 4342
4342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









