






太牛了!模型DF-TransFusion,通过把交叉注意力机制与多模态结合,性能完美,分类准确性达100%!
实际上,近来该方向已经狂揽了多篇A会,研究热度很高!这是因为,交叉注意力机制能在不同模态之间建立联系,促进信息的交流和整合。而多模态数据,则提供了丰富的信息来源,通过交叉注意力机制可以充分利用这些信息的互补性。从而提高模型的性能、降低计算成本!
目标该方法在图像处理、时间序列分析、多模态情感分析等领域都取得了显著效果,且还在上升期,创新空间很大。
为让大家能够找到更多灵感启发,早点发出自己的顶会,我给大家准备了12种创新思路,原文和源码都有!
论文原文+开源代码需要的同学看文末
论文:Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
内容
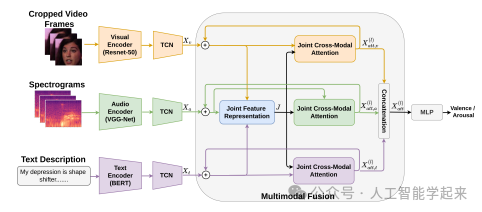
该论文介绍了一种名为递归联合跨模态注意力(Recursive Joint Cross-Modal Attention, RJCMA)的模型,用于多模态融合中的维度情感识别。该模型能够有效捕捉音频、视觉和文本模态之间的内在和跨模态关系,通过计算基于联合音视频文本特征表示与各个单独模态特征表示之间的交叉相关性来同时捕获这些关系。
论文:Temporal Cross-Attention for Dynamic Embedding and Tokenization of Multimodal Electronic Health Records
内容
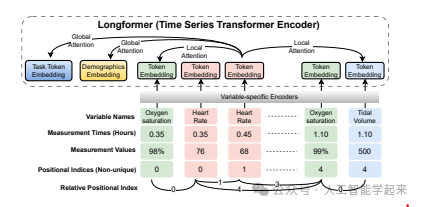
该论文介绍了一种动态嵌入和标记框架,用于精确表示多模态临床时间序列数据,通过结合时间编码、序列位置编码和时间交叉注意力的新颖方法来解决现代电子健康记录(EHR)系统的高维度、稀疏性、多模态性和不规则采样频率等挑战。
论文:CrossFuse: A Novel Cross Attention Mechanism based Infrared and Visible Image Fusion Approach
内容
该论文提出了一种名为CrossFuse的新型交叉注意力机制,用于红外和可见光图像融合。该方法通过两个阶段的策略来训练融合网络:首先,分别对每种模态训练自编码器网络以提取特征;然后,使用固定的编码器和新提出的交叉注意力机制(CAM)以及解码器进行第二阶段的训练,利用自注意力增强每种模态内的特特征,并通过基于交叉注意力的架构增强不同模态间的互补信息。

论文:DF-TransFusion: Multimodal Deepfake Detection via Lip-Audio Cross-Attention and Facial Self-Attention
内容
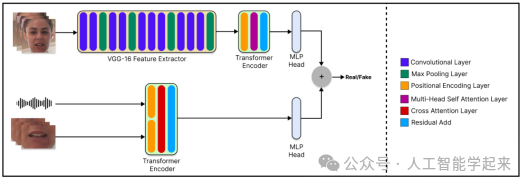
该论文介绍了一种名为DF-TransFusion的新型多模态深度伪造检测框架,该框架通过唇部同步和输入音频的交叉注意力机制以及通过微调的VGG-16网络提取视觉线索来同时处理音频和视频输入,使用变换器编码器网络执行面部自注意力。
论文:GAF-Net: Improving the Performance of Remote Sensing Image Fusion using Novel Global Self and Cross Attention Learning
内容
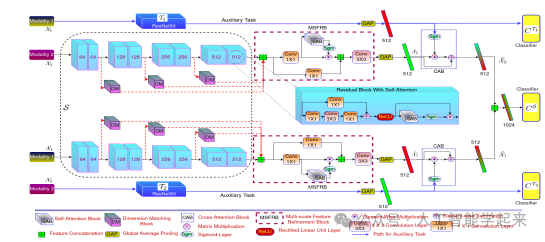
该论文提出了一种名为GAF-Net的新型多模态遥感图像融合架构,该架构利用了创新的全局自注意力和交叉注意力学习技术来提升融合性能。GAF-Net通过在查询-键-值处理中引入模态内特征细化模块,实现了全局空间和通道上下文的结合,生成两个通道注意力掩模,通过两个辅助的模态特定分类任务来生成高度区分性的交叉注意力掩模,并提出一种新颖的非冗余正则化器来减少模态特定特征之间的高相关性。
关注下方《人工智能学起来》
回复“CAM”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









