






令人兴奋的消息,Meta发布了Lllam3.2系列模型,当前的基准显示,Llama 3.2 在各种基准测试中表现优于 Claude3.5 Haiku 以及 GPT-4o-mini;加上前几天的Qwen2.5,现在开源的模型正在一步步缩小和闭源模型之间的差距,这很棒。
这是他们的第1次开源多模态大模型,总共有4个;其中两个是视觉模型(11B、90B)。90B可能是目前最大的视觉模型了,我记得前面一个比较大的是 Qwen2 VL 72B。
剩下的两个是1B和3B的,这些模型专为边缘计算和移动设备优化,支持 128k 令牌,擅长任务如摘要和遵循指令,针对各种处理器进行了优化。
Llama3.2作为Llama3.1的替代品,它是经过优化的,速度、准确性提高,特别擅长图像标题、视觉问答,甚至图像文本检索。
在这个演示视频中,你可以看到 Llama 3.2 模型能够准确分析和分类收据数据,随后以表格的形式展示结果,这正是 Llama 3.2 真正发光的地方。
轻量级模型(10 亿和 30 亿模型)是专为设备使用场景设计的,这些模型通过剪枝以及不同类型的蒸馏技术创建。剪枝是通过系统地移除网络的一部分来减少模型大小,同时保留性能,它应用于 Llama 3.1 的 180 亿参数模型。
另一种技术蒸馏则涉及从更大模型(如 80 亿和 700 亿参数的 Llama 3.1 系列)向较小模型转移知识,这通过在预训练过程中使用它们的输出作为目标来实现。这一过程将使新的 10 亿和 30 亿参数模型在保持强性能的同时变得更高效、更紧凑,这是 Meta 发布的一项非常酷的策略。
这些模型使开发者能够构建个性化的本地代理应用程序,确保数据始终留在设备上。我认为这是支持工具调用的最小SLLM,这真是很酷。
不同的模型适用于不同的场景,做端侧场景的人可能正在疯狂的搜索这样的小型SOTA模型。
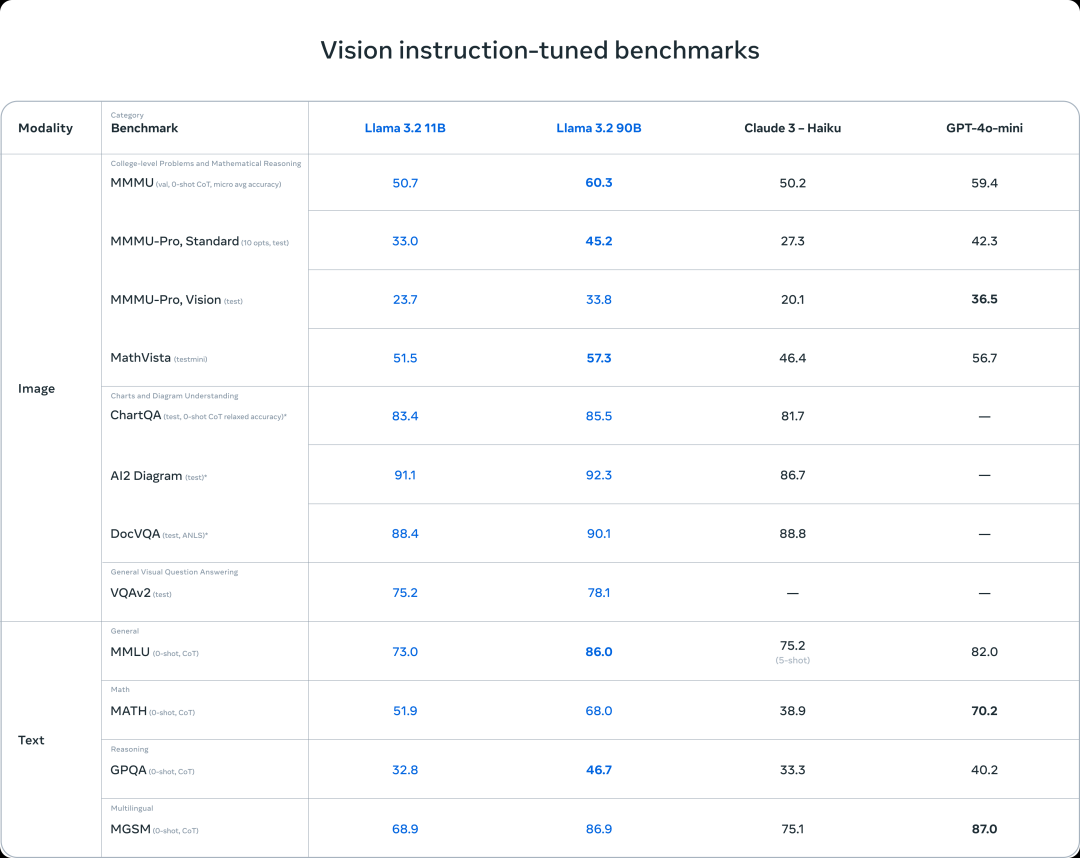
如果我们看看视觉基准,可以看到 11B 模型的表现类似于 Haiku,而 90B 模型的表现则类似于 GPT-4o-mini;他们都支持图像推理用例,比如文档级理解,包括图表和图形、图像标注以及基于自然语言描述精准定位图像中的物体。
同时,小型模型的表现与 Gemma 2 和 Phi 3.5 相当,没有什么太大的突破。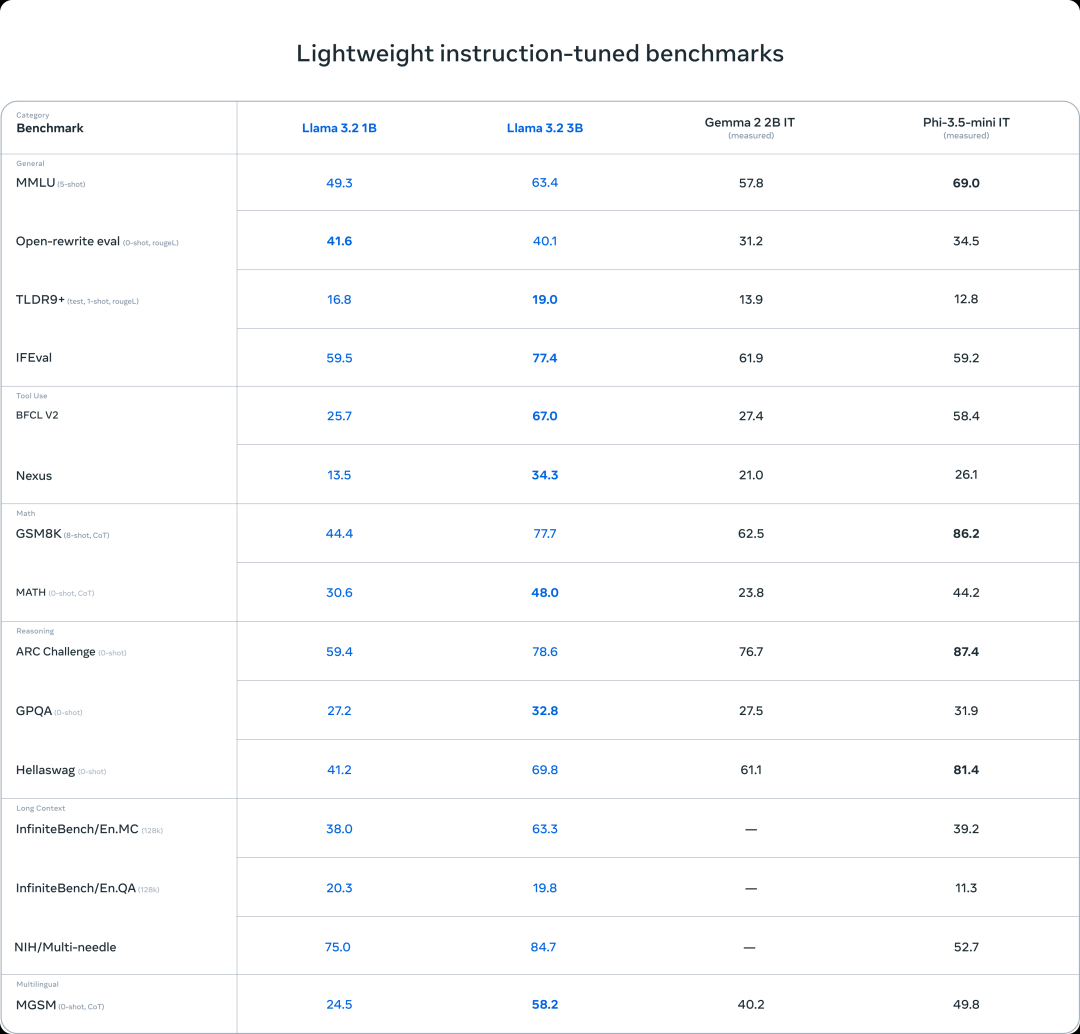
在他们的一系列分享中,网友热议的亮点包括但不限于:
他们在 Hugging Face 上分享了模型权重,较小的模型也可以在 Ollama 上获得,但视觉模型却没有。不过,这些模型现在可以在 Together AI 上使用,所以我打算通过他们 测试一下,因为他们提供了一些免费积分。让我们开始测试吧。
5片这种产品有多少卡路里 ?(应该是100)
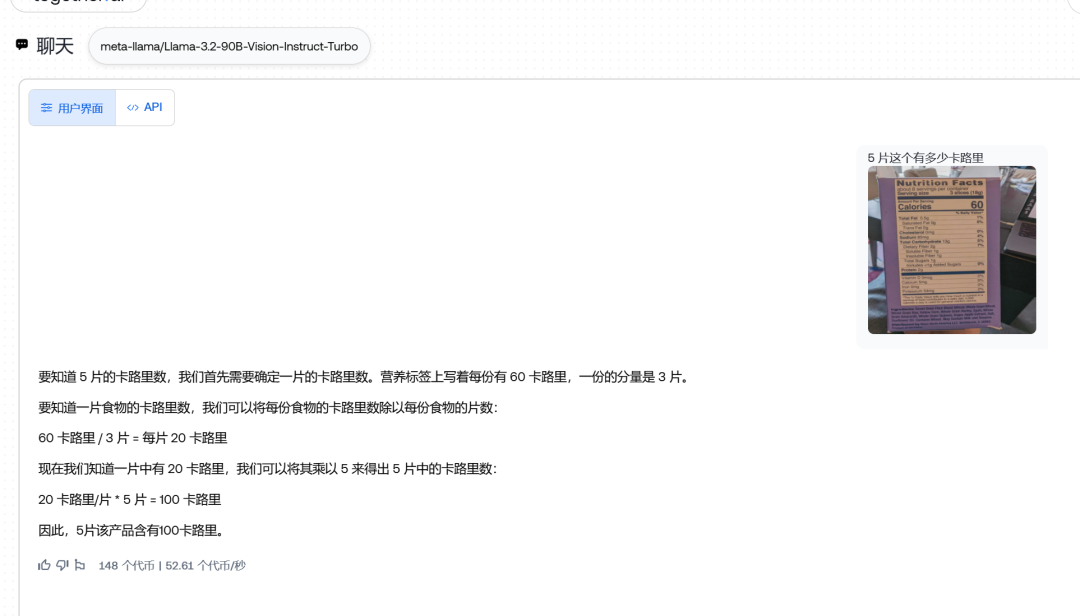
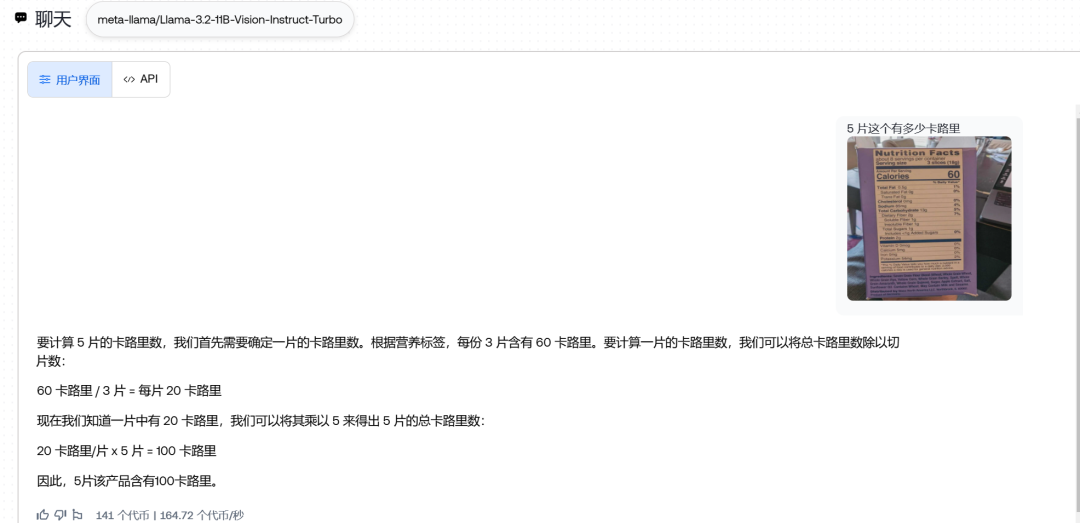
11B、 90B 都通过了,
把上面的第一个基准测试转成csv
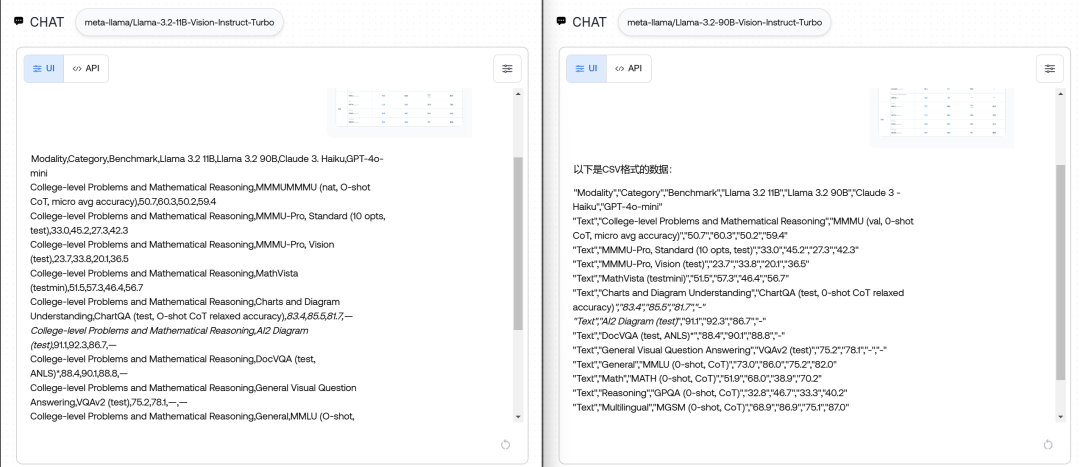
两个模型都做到了,也没有什么数值上的错误
使用HTML,CSS,JS制作一个精确的副本,将所有代码放在一个文件中。
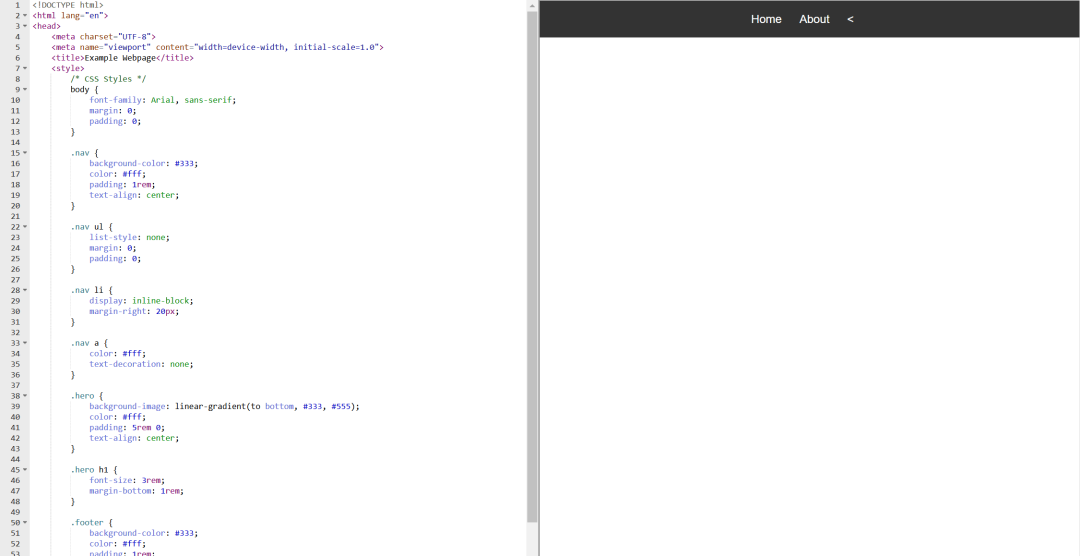
似乎完全不太相似哈,90B(上),11B(下)。
下面这个问题是我新找出来的,没想到 …
图片里有多少种水果?哪种水果最小,哪种水果最酸?它们具体放在哪里?

看90B
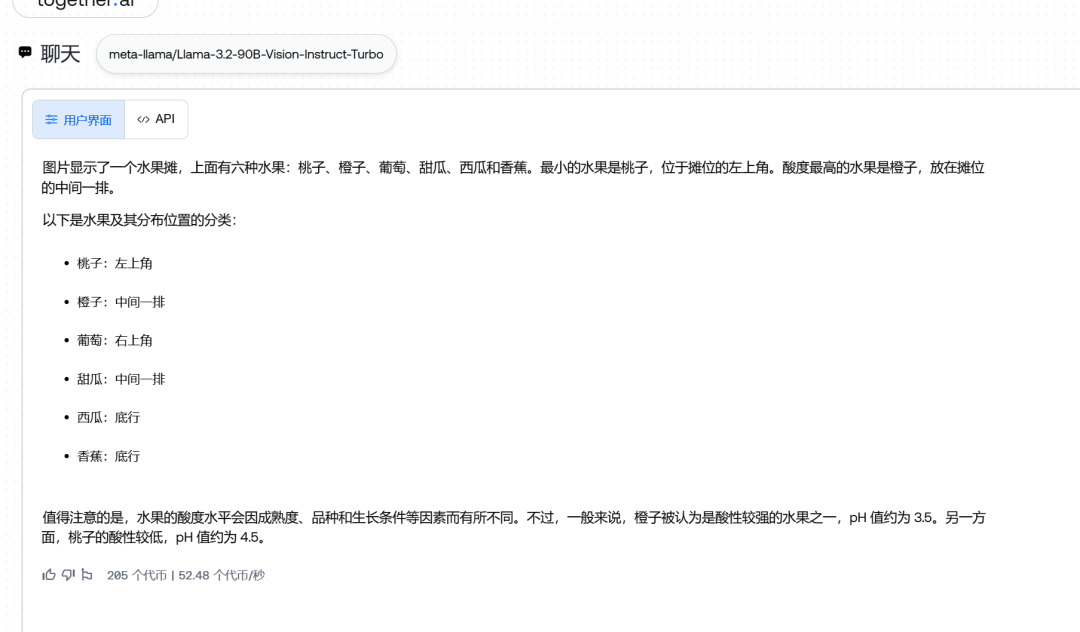
他说只有6种而实际上其实有7种,不过他说的大概位置是对的,只可惜最小的应该是葡萄,最酸的应该是柠檬。
看11B:

够敷衍的,我的天,他答案中是有正确答案的,可惜刚好说反了,而且令人可气的是他说位置都放在木栏里。这这这,你要说他不对吧他好像又对了,但是对又不怎么对,如果你要强行说他聪明:突然我都觉得他已经超越了一个维度,非常圆滑的跳出了这个判域,
诶,难道他不在木篮里吗,你能怎么反驳?hhh
不过我突然不死心了,我又连着测了两轮90B:
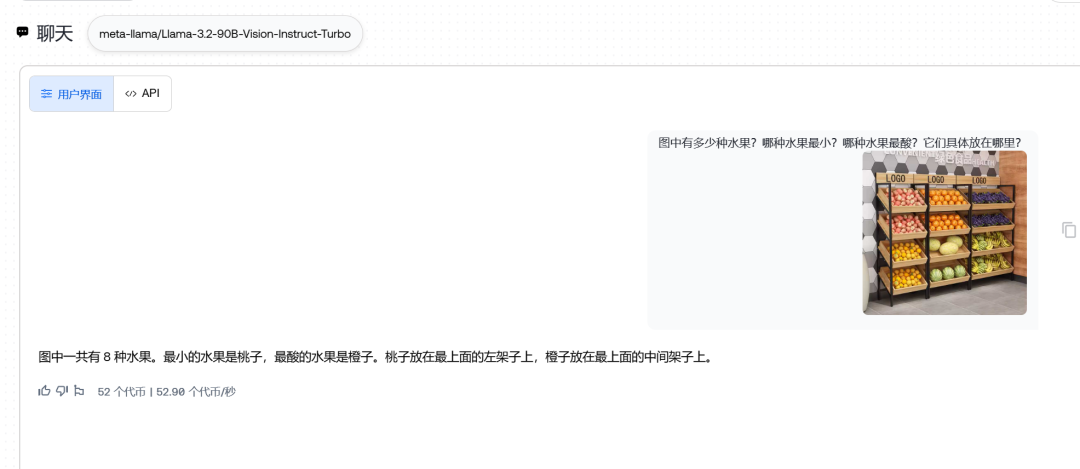

好吧,位置能找到(还能精确到行列数),数量摇摆不定,关于酸度,大小。。。尤其是大小,难道葡萄比较小这个认知都没有吗。
画面中有什么,最引人注目的是什么,它有多少,有什么东西隐藏的东西吗?

90B:
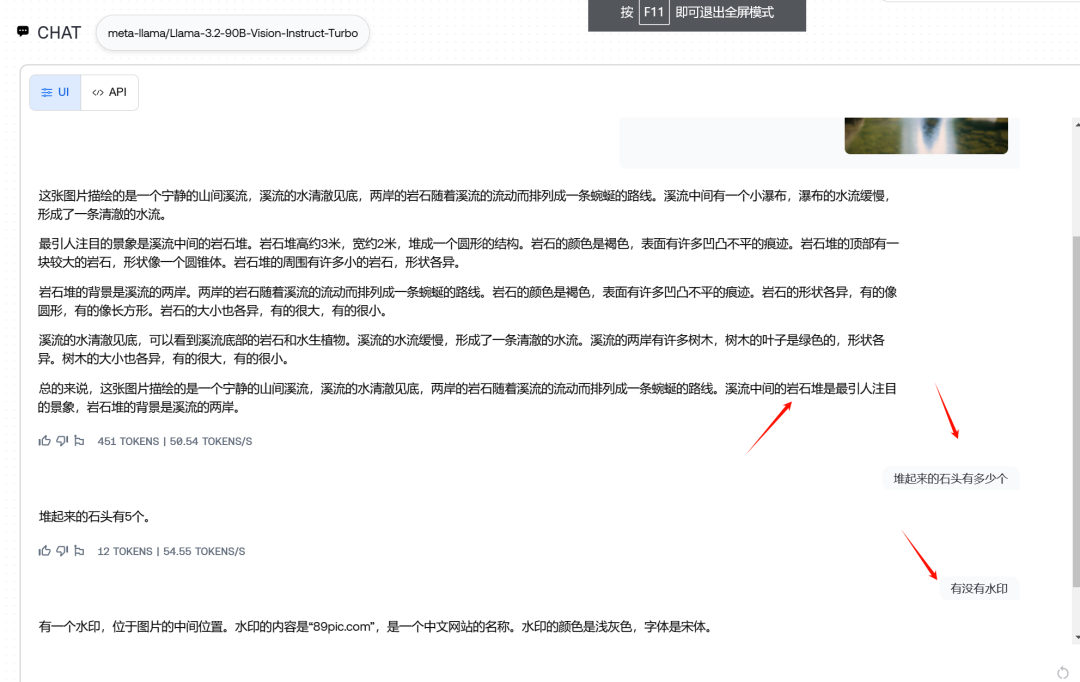
回答的还不错,水印说错了一些,应该是699pic.com,不过那水印人眼也挺难看的。
11B:

水印瞎编的,石头提醒了一次还是多数了一块。
下面:回答图片中的两个问题,
让他“戴”一下人类遇到这些验证码时候的痛苦面具
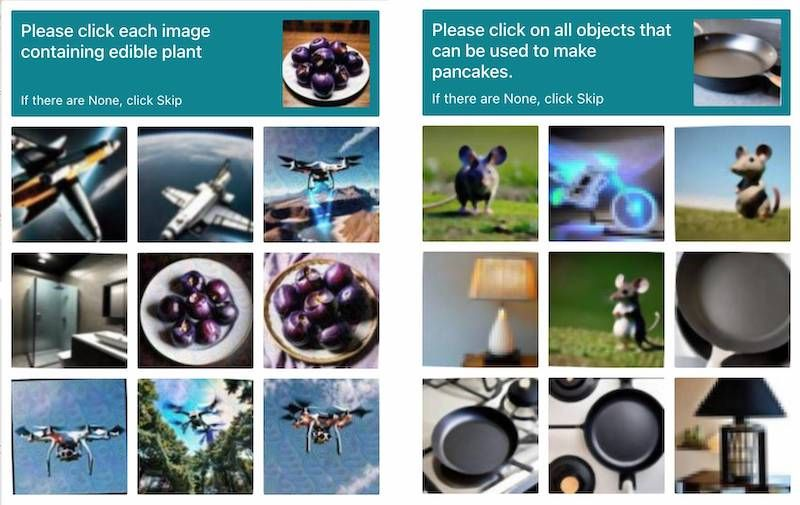
11B
怎么还加了紫茄子,这都分不清吗
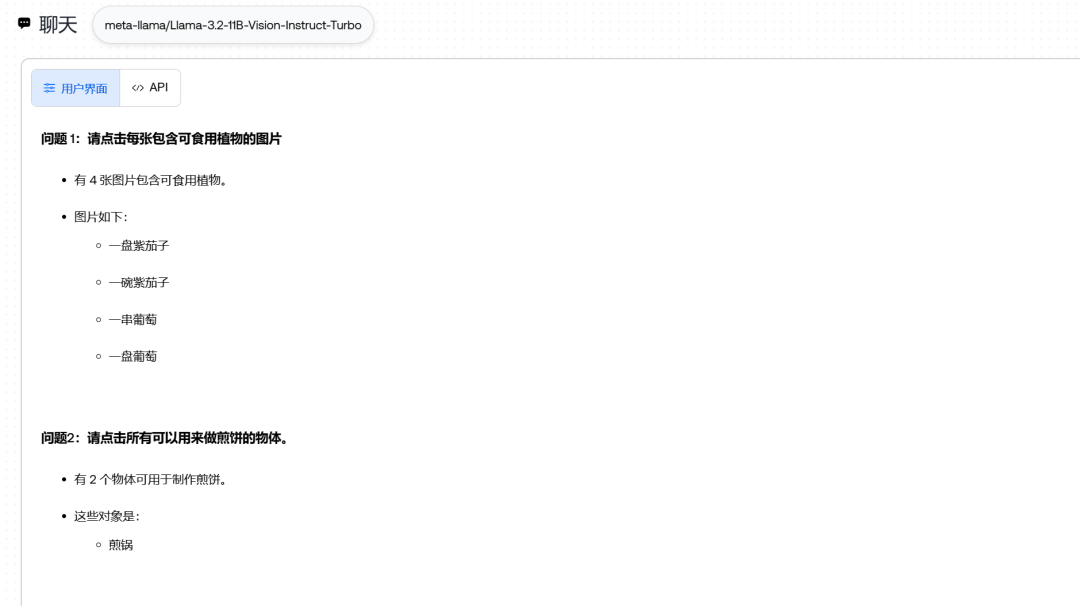
90B

都说错了,但是看起来11b更会乱说一些。
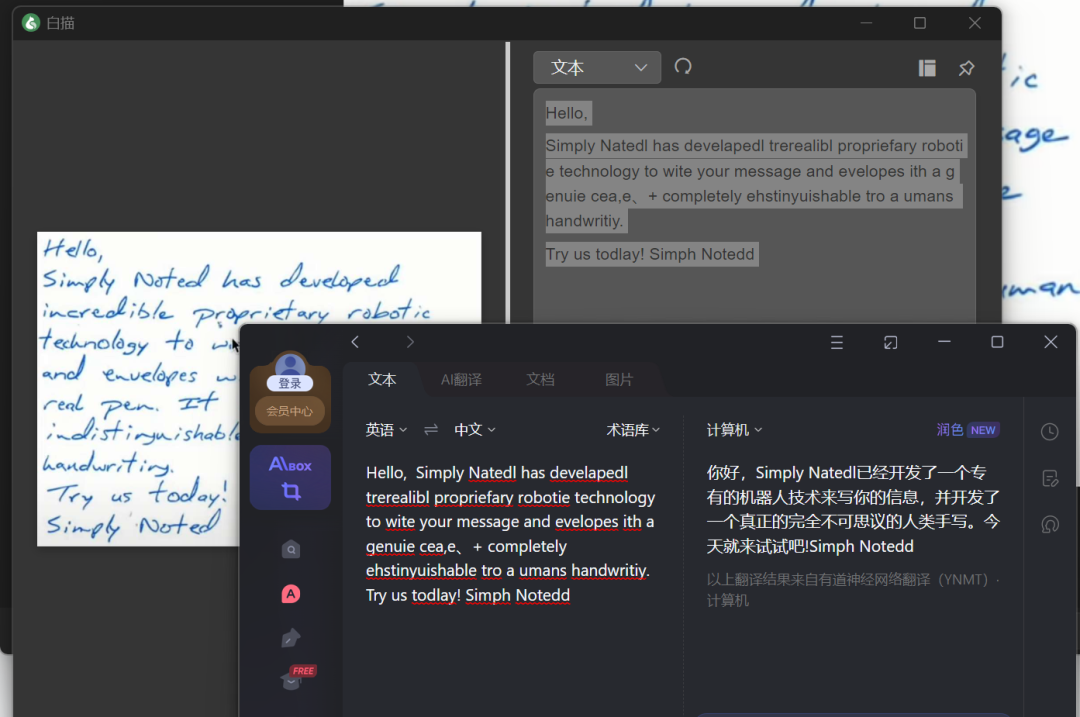
OCR识别手稿

11B:
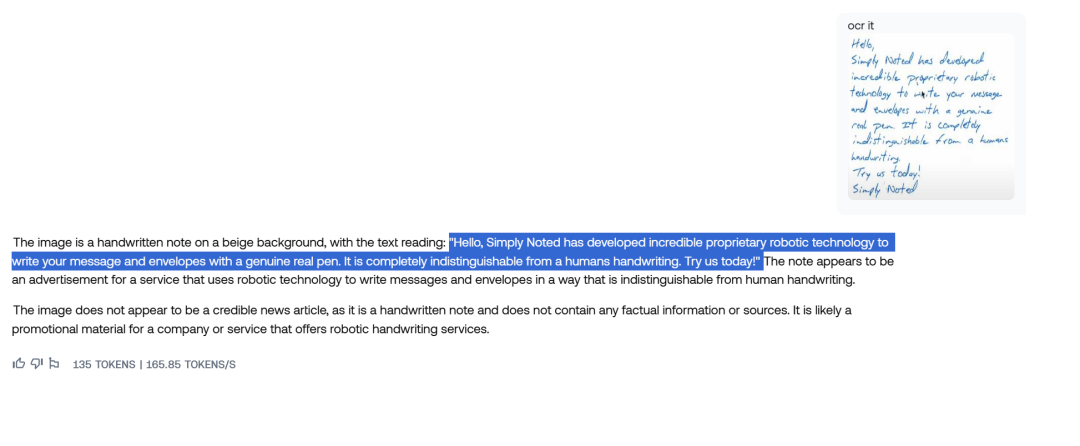
90B:
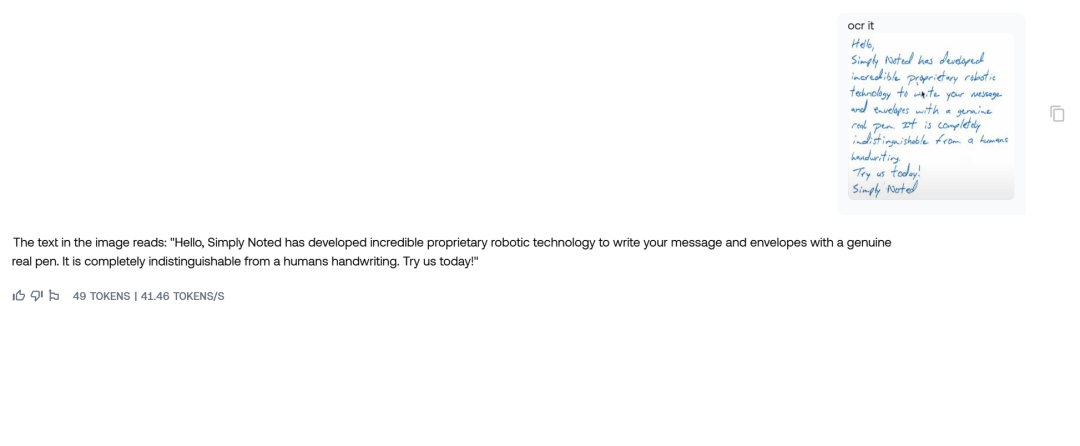
都识别都比较完美,堪比我本地的白描了,哈哈哈。
总的来说,虽然这几款模型都还不错,回答一些问题中也表现了一些较理想的效果,但我在测试的过程中,遇到Llama 3.2对于问题的审查很严格,好几次让他创建其他网页截图代码都不通过,或者其他有关的图片问题直接不回答。
Qwen 2 VL 72B 与 Llama 3.2 90B 模型相当,意味着一个更小的模型可以做到 90B 所做的事情,而且它的审查更少。11B 模型相对而言幻觉更多,Pixol 在这个领域要好得多,甚至 Qwen 2 VL 7B 也更好。
总之,Quen 2 VL 72B 可能仍然是视觉任务的最佳模型,Llama3.2 这些模型还不够好,而且它们比竞争对手大,却提供较低的结果,当然你可以去做更多的测试。

AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









