






自从大语言模型(LLM)掀起 AI 革命以来,谁能在“参数大战”与“性能比拼”中杀出重围,一直是开发者与技术爱好者们关注的焦点。
如今,Meta Research 重磅推出的Llama 4,凭借全面升级的 Mixture‑of‑Experts(MoE)架构、创新性的 iRoPE 无限上下文技术,以及真正实现文本/图像/视频统一处理的多模态能力,再次将开源社区的热情推向新高峰——它甚至能支持20 小时连续视频处理!
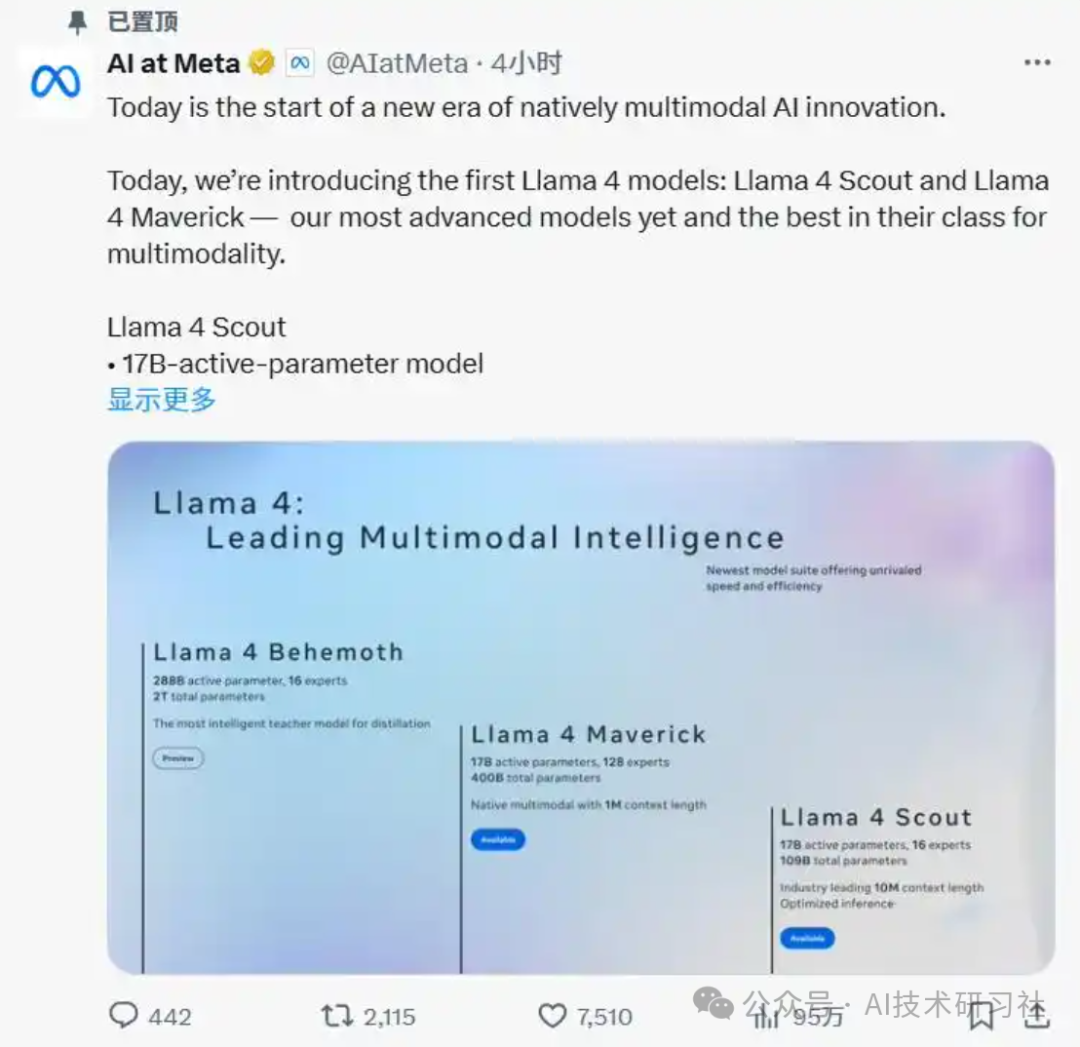
今天,我们将用最通俗易懂的方式,带你全面剖析 Llama 4 的核心亮点、技术架构与应用前景,让你第一时间把握这位“开源王者”的真面目。
一、Llama 4 三大版本:Scout、Maverick、Behemoth
Llama 4 家族共分为三个版本,满足不同场景下的算力与性能需求:
-
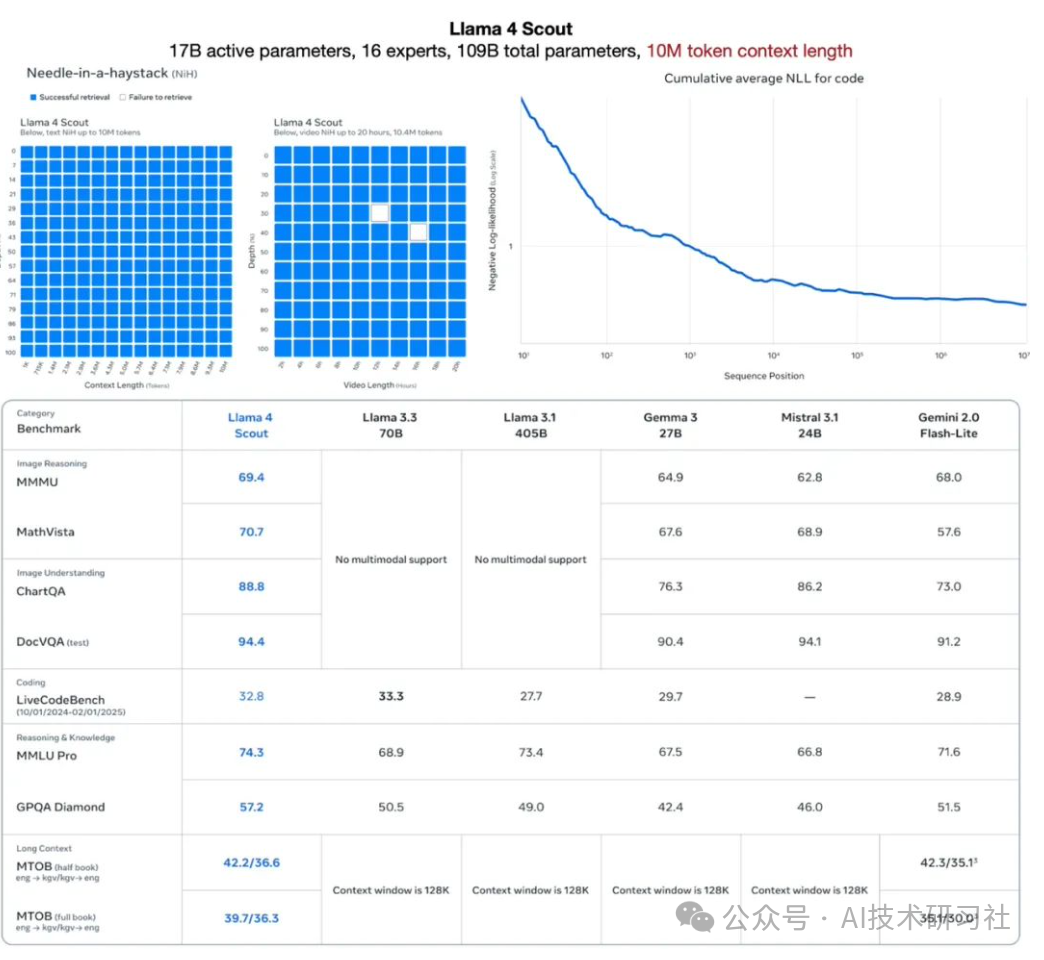
Scout(17B/109B MoE)
-
活跃参数:17 亿
-
专家数:16 个
-
总参数:1090 亿
-
部署成本最低,可单卡 H100(Int4 量化)运行
-
-
Maverick(17B/400B MoE)
-
活跃参数:17 亿
-
专家数:128 个
-
总参数:4000 亿
-
适合中型集群部署,推荐 3–6 张 H100
-
-
Behemoth(288B/2T MoE)
-
活跃参数:288 亿
-
专家数:16 个
-
总参数:2 万亿
-
性能旗舰,需 15–26 张 H100 集群
-
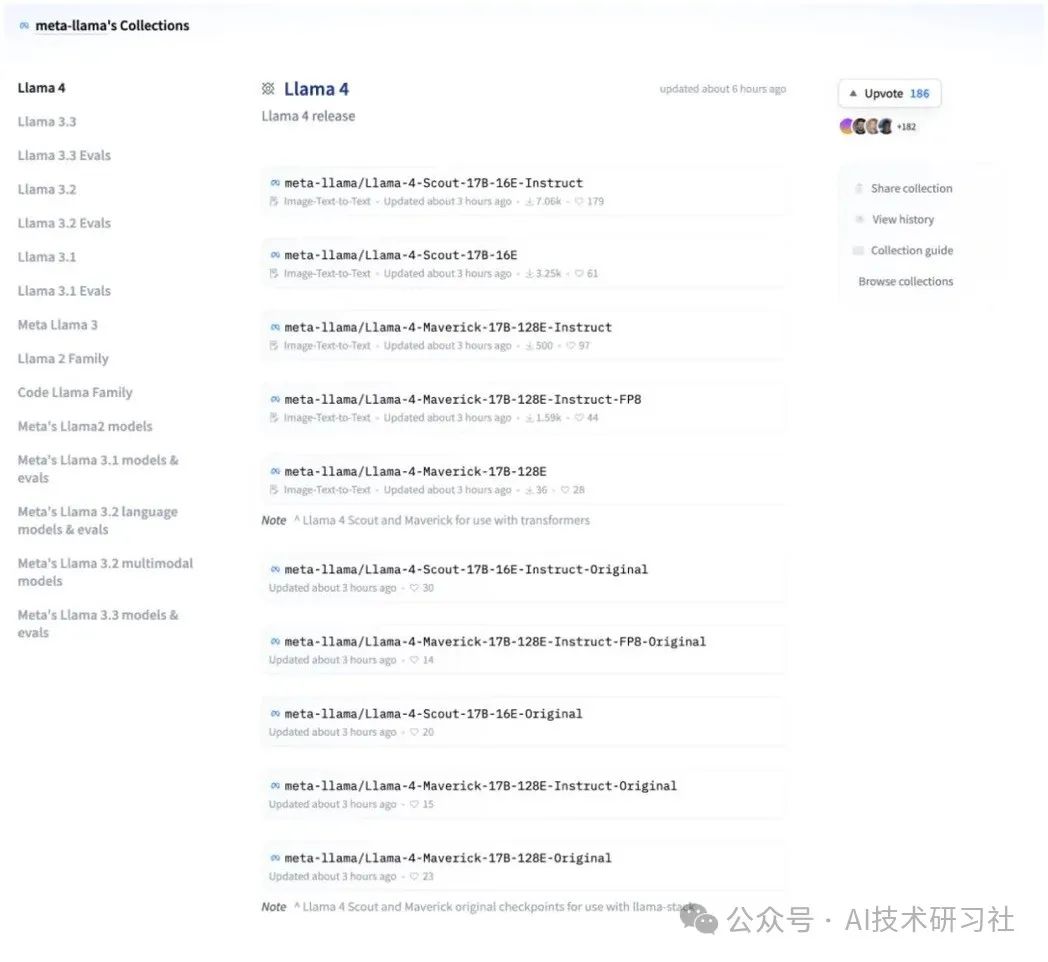
三个版本在活跃参数保持一致的同时,通过专家数量与总参数规模的调整,实现了从轻量部署到极限性能的无缝覆盖。
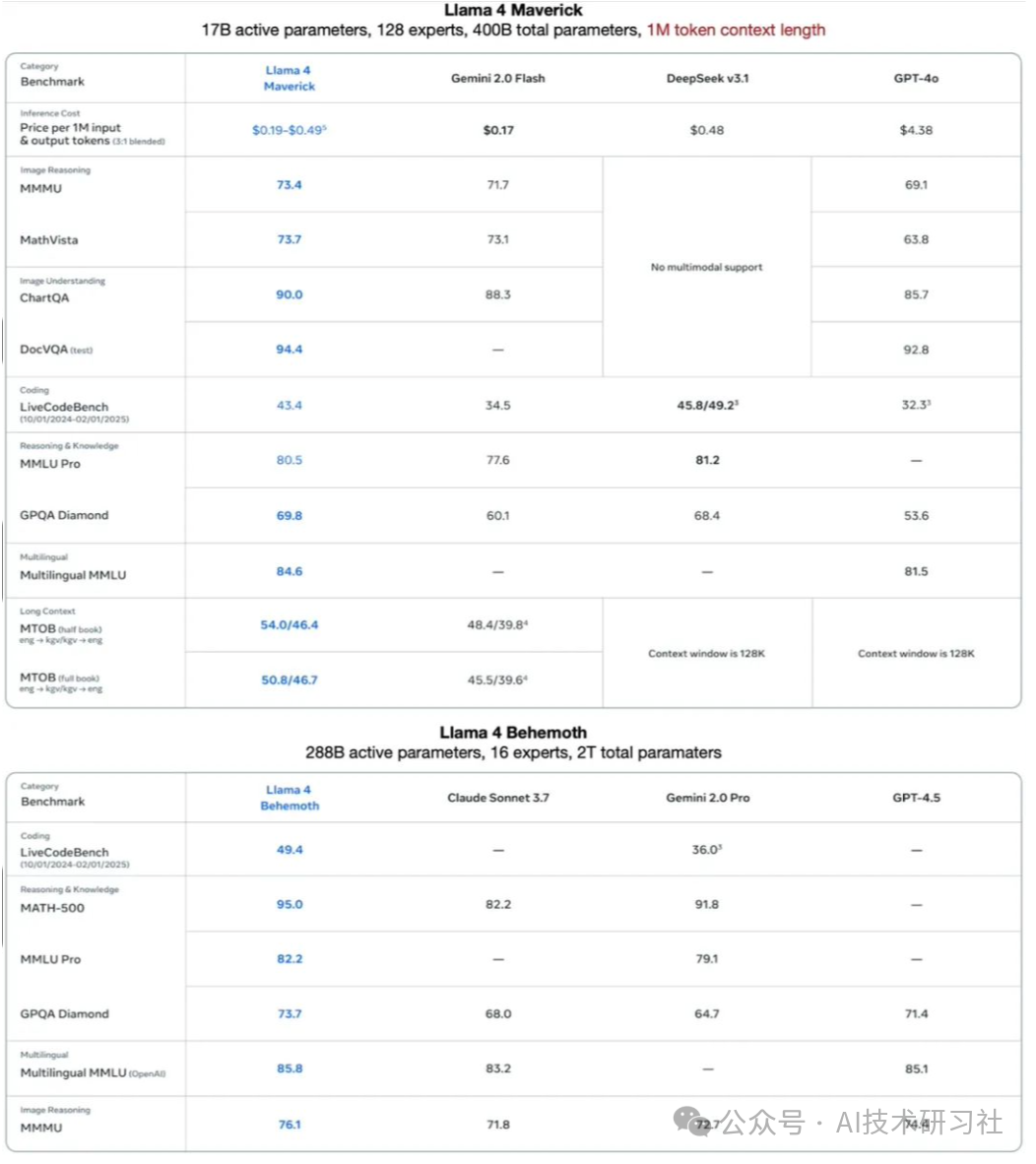
二、核心亮点一:成本革命,推理价低至$0.19/M tokens
在当下“算力成本”高企的环境下,Llama 4 带来了一场推理成本的革命:
-
Behemoth 以 3:1 混合比例(Int4 + FP16)推理时,成本低至 $0.19/M tokens,已经能与 DeepSeek 等商用大模型定价一较高下。
-
Scout 和 Maverick 也能将推理成本控制在 $0.19–0.49/M tokens 之间,且解码延迟仅 30ms/Token,预填充延迟 350ms。
对于需要大规模在线推理的企业和开发者来说,这样的价格几乎颠覆了对“开源模型即高成本”刻板印象。
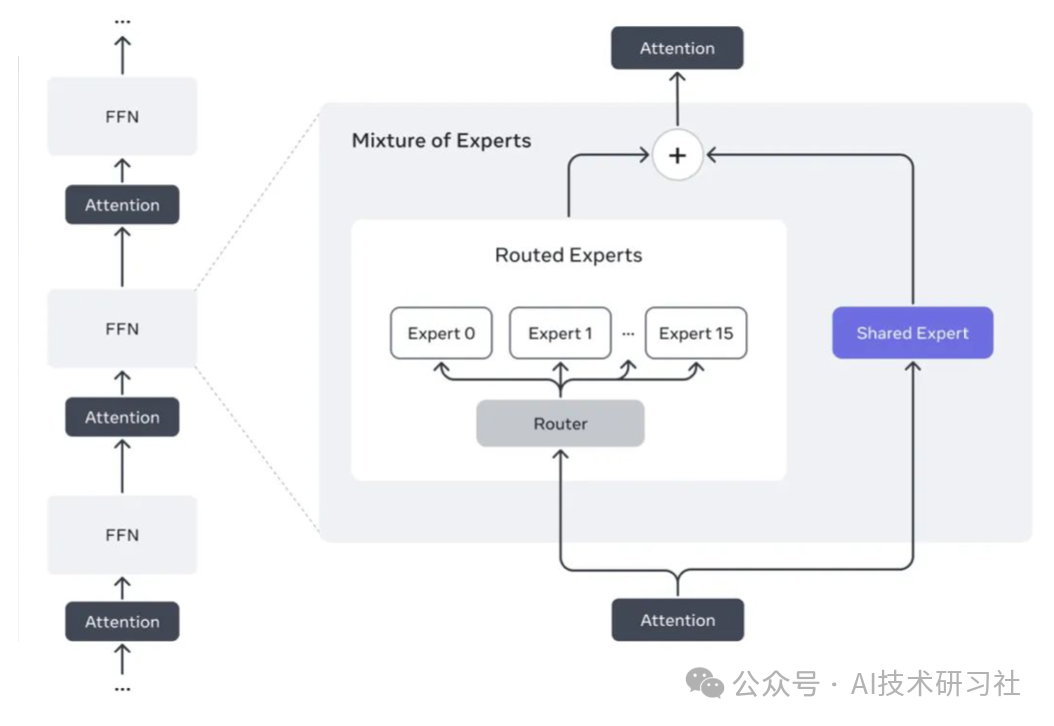
三、核心亮点二:Mixture‑of‑Experts 架构——2 万亿参数的“隐藏实力”
Llama 4 全系列都采用动态 MoE(Mixture‑of‑Experts)系统,将“专家混合”推向极致:
| 版本 | 活跃参数 | 专家数量 | 总参数规模 | 类比 |
|---|---|---|---|---|
| Scout | 17B | 16 | 109B | 单缸发动机 |
| Maverick | 17B | 128 | 400B | 多缸 V8 引擎 |
| Behemoth | 288B | 16 | 2T | 双涡轮巨兽 |
-
工作逻辑:每次推理时,系统会动态激活 2–3 个专家模块,类似于汽车引擎的“气缸工作模式”,既保证了高效计算,又避免了全量激活带来的冗余开销。
-
性能表现:在 LMArena 排行中,Llama 4 系列以 ELO 1417 的成绩暂居开源模型第二,实力毋庸置疑。
MoE 架构让 Llama 4 在保证“轻量推理”的同时,拥有接近大规模密模型的“知识储备”,实现了规模与效率并存的最佳平衡。

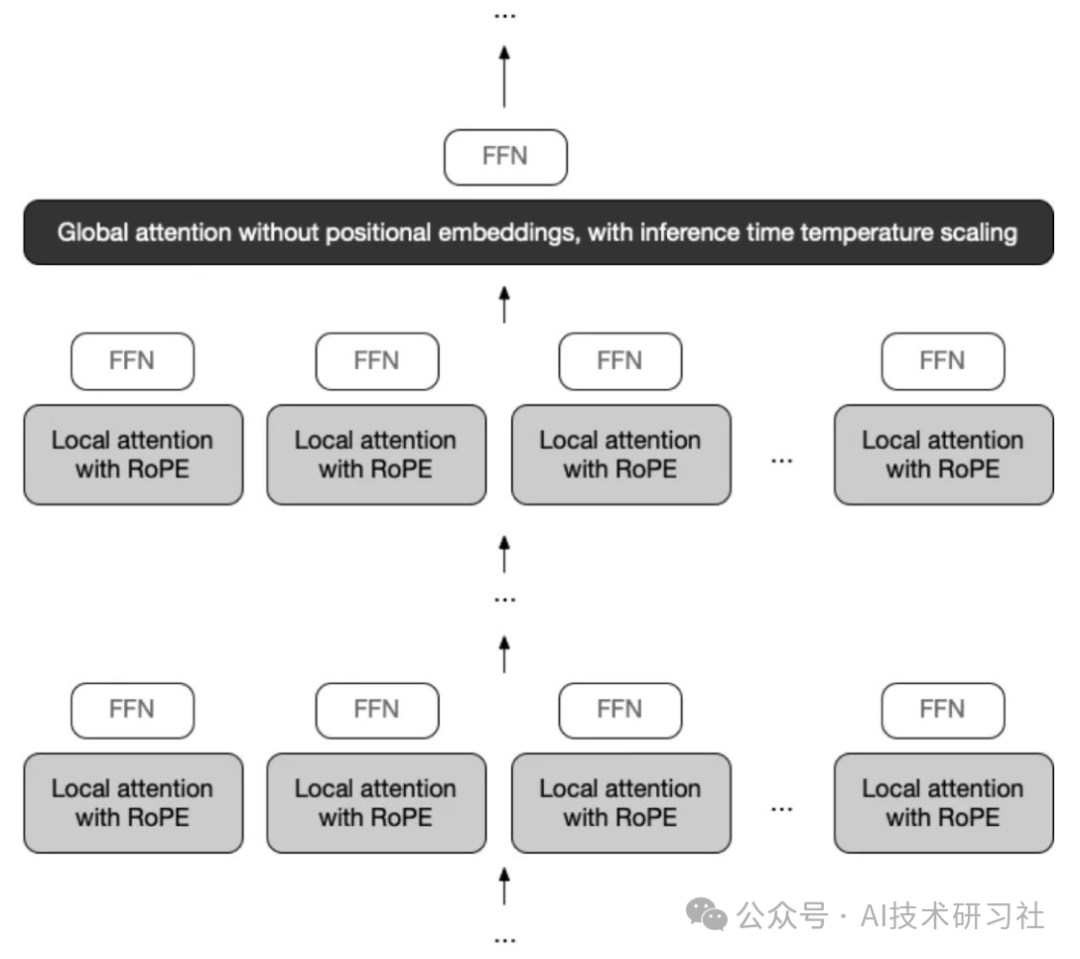
四、核心亮点三:iRoPE 无限上下文——看视频、读代码“无极限”
传统 RoPE(Rotary Position Embedding)在长文本或长序列处理上,常常受制于固定上下文窗口。Llama 4 创新性地提出iRoPE 无限上下文架构,让模型轻松应对10M tokens的超长输入,相当于:
-
20 小时 连续视频字幕
-
500 万行 代码库
iRoPE 双层注意力机制
-
局部层(Local)
-
标准 RoPE 注意力,支持 8K tokens 的高精度局部上下文理解
-
-
全局层(Global)
-
无位置编码的全局注意力,理论上可覆盖 无限上下文
-
同时,Llama 4 还引入了温度缩放公式,动态调整不同位置的注意力强度:
xq *= 1 + log(floor(i / α) + 1) * β# 其中 α=8K 为基准长度,β 为缩放系数在
256K 长度预训练基础上,iRoPE 实现了对10M+ 长度的稳定外推,彻底解决了长文本与长序列的记忆“断片”难题。
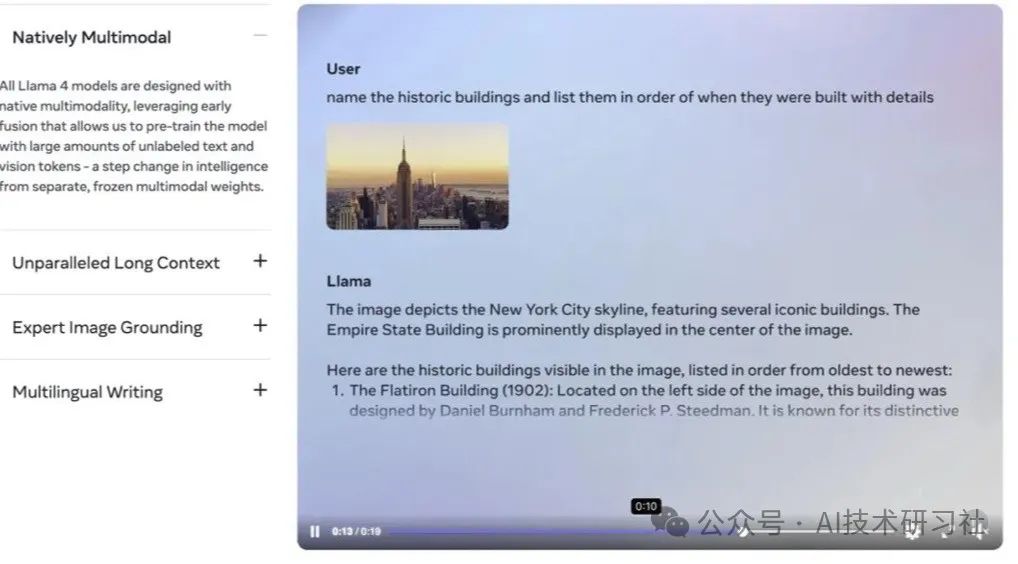
五、核心亮点四:多模态早期融合——统一处理文本/图像/视频
在多模态领域,Llama 4 采用早期融合设计,将文本、图像、视频映射到同一嵌入空间,训练数据量高达 30T 多模态 tokens(FP8 精度):
-
图像理解:在多项视觉基准测试中,Llama 4 超越 GPT‑4o 和 Gemini 2.0 Flash,具备更强的图像识别与场景理解能力。
-
视频处理:得益于 iRoPE 的超长上下文,Llama 4 可以20 小时 连续处理视频日志,自动生成字幕、提炼要点,甚至进行情感分析与镜头分类。
-
代码理解:在 10M tokens 窗口内,实现对 500 万行 代码库的即时检索、分析与自动补全,开发效率大幅提升。
这一“多模态大融合”不仅让 Llama 4 成为真正的“全能型 AI 助手”,更为各行各业的智能化应用打开了无限想象空间。
六、技术架构深度解析
6.1 动态 MoE 系统
-
专家动态路由:基于任务特征,智能路由器(Router)决定每次推理激活哪些专家。
-
负载均衡:通过专家容量约束,避免“热门专家”过载,保证系统稳定性。
-
训练与蒸馏:在大规模 MoE 训练后,Llama 4 提供蒸馏版模型,兼顾性能与部署成本。
6.2 iRoPE 无限上下文
-
分层注意力:局部+全局双层注意力配合温度缩放,兼顾短距离与长距离依赖。
-
预训练策略:使用 256K 长序列预训练,并结合“递增长度”训练技巧,实现对 10M+ 的高效外推。
6.3 多模态早期融合
-
共享嵌入空间:文本、图像、视频通过统一的编码器投射到同一高维空间,消除模态鸿沟。
-
大规模多模态预训练:30T tokens,覆盖各种场景与任务,让模型具备“万金油”般的适应能力。
七、开发者须知:部署与成本指南
| 版本 | 部署算力 | 显存需求 | 推荐集群 | 推理成本 |
|---|---|---|---|---|
| Scout | 单卡 H100(Int4) | 120–130GB | 1 卡 | $0.19–0.49/M tk |
| Maverick | 3–6 张 H100 | 120–130GB × N | 3–6 卡 | 同上 |
| Behemoth | 15–26 张 H100 | 120–130GB × N | 15–26 卡 | $0.19/M tk |
-
解码延迟:30ms/Token
-
预填充延迟:350ms
-
许可限制:MAU(Monthly Active Users)超 700 万 需申请特殊授权
无论是小团队的轻量级部署,还是大企业的超大规模应用,Llama 4 都能提供从单卡到集群的全方位支持。
八、Llama 4 的行业影响与未来展望
-
开源生态再升级
Llama 4 以媲美商用模型的性能与成本,势必推动更多企业与开发者选择开源方案,促进 AI 应用创新。 -
长序列与多模态应用爆发
20 小时视频处理、百万行代码理解等极限场景,将催生新一代智能视频剪辑、全代码搜索与自动化运维工具。 -
人机协同进入新纪元
多模态、超长上下文与 MoE 架构的结合,让 AI 助手真正从“对话”走向“执行”,企业级智能化办公将成为常态。 -
未来优化方向
-
专家数量与容量动态调整:让 MoE 系统更具自适应性
-
更高效的长序列推理算法:降低延迟,提升用户体验
-
更多模态的融合:加入语音、3D 点云等,实现全感官 AI 体验
-
从 Mixture‑of‑Experts 的规模革命,到 iRoPE 的无限上下文,再到多模态的早期融合,Llama 4 用一系列技术创新告诉我们:开源大模型不仅能在性能上与商用旗舰一较高下,还能以更低的成本、更灵活的部署,真正走进千行百业的应用场景。
如果你是开发者,Llama 4 将助你在代码分析、自动化运维、智能客服等领域一骑绝尘;如果你是科研人员,它能为你提供超长文献阅读与多模态实验支持;如果你是产品经理或企业决策者,Llama 4 的低成本与高性能,无疑会成为你构建智能产品的“秘密武器”。
未来已来,开源王者 Llama 4 正在引领下一波 AI 革命浪潮!

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









