








一、导言
《奔跑吧,别走:追求更高的FLOPS以实现更快的神经网络》,主要探讨了如何设计快速且高效的神经网络模型。文章指出,尽管许多研究致力于减少浮点运算次数(FLOPs)来提升模型速度,但FLOPs的减少并不直接等同于延迟的降低。作者发现,问题的核心在于较低的每秒浮点运算次数(FLOPS),这主要是由于操作过程中频繁的内存访问,尤其是深度卷积(DWConv)带来的影响。
创新点
-
提出部分卷积(Partial Convolution, PConv):针对现有网络中由于增加网络宽度以补偿精度下降而导致的内存访问增加问题,该文提出了部分卷积(PConv)。PConv通过仅在输入通道的部分上应用滤波器,同时减少了冗余计算和内存访问,从而更高效地提取空间特征。
-
构建FasterNet系列模型:基于PConv,文章进一步设计了名为FasterNet的新家族神经网络,这些网络在多种设备上实现了显著的运行速度提升,同时保持了在不同视觉任务上的准确性。例如,FasterNet-T0相比MobileViT-XXS在GPU、CPU和ARM处理器上分别快2.8倍、3.3倍和2.4倍,且准确率更高。大型的FasterNet-L在保持与Swin-B相当的高精度(83.5%)的同时,GPU上的推理吞吐量提高了36%,CPU上的计算时间节省了37%。
优点
- 针对性优化:通过关注并解决深度卷积导致的内存访问效率问题,论文提出的PConv能更有效地利用硬件资源。
- 广泛适用性:FasterNet模型在不同尺寸和应用场景下均展现出卓越性能,从轻量级到大型模型均有覆盖。
- 代码开放:提供了开源代码,便于学术界和工业界复现研究结果,促进技术传播和进一步创新。
结论
本文通过提出部分卷积(PConv)这一新颖操作以及构建FasterNet模型系列,为追求高性能与低延迟的神经网络设计提供了一个创新思路。它不仅在理论层面分析了当前模型速度瓶颈,还在实践层面展示了显著的性能提升,具有重要的研究价值和实际应用潜力。未来工作可进一步探索PConv与其他优化技术的集成,以及在更多任务和平台上的表现。
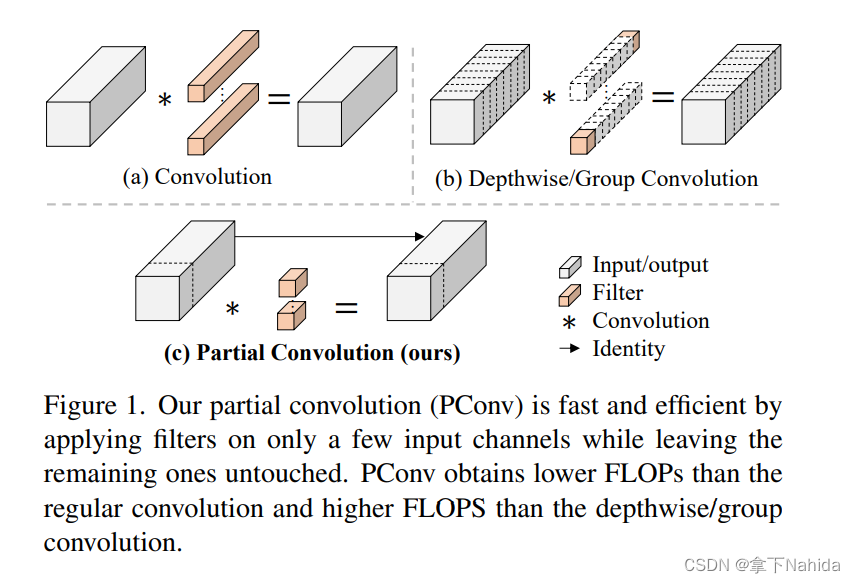
二、准备工作
首先在YOLOv5/v7的models文件夹下新建文件pconv.py,导入如下代码
from models.common import *
"""
https://arxiv.org/abs/2303.03667
<<Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks>>
"""
from torch import Tensor
class PConv(nn.Module):
def __init__(self,
in_channels,
kernel_size=3,
n_div: int = 4,
forward: str = 'split_cat'):
super(PConv, self).__init__()
assert in_channels > 4, "in_channels should > 4, but got {} instead.".format(in_channels)
self.dim_conv = in_channels // n_div
self.dim_untouched = in_channels - self.dim_conv
self.conv = nn.Conv2d(in_channels=self.dim_conv,
out_channels=self.dim_conv,
kernel_size=kernel_size,
stride=1,
padding=(kernel_size - 1) // 2,
bias=False)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError("forward method: {} is not implemented.".format(forward))
def forward_slicing(self, x: Tensor) -> Tensor:
x[:, :self.dim_conv, :, :] = self.conv(x[:, :self.dim_conv, :, :])
return x
def forward_split_cat(self, x: Tensor) -> Tensor:
x1, x2 = torch.split(x, [self.dim_conv, self.dim_untouched], dim=1)
x1 = self.conv(x1)
x = torch.cat((x1, x2), dim=1)
return x其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
from models.pconv import PConv并搜索def parse_model(d, ch)
定位到如下行添加以下代码
elif m is PConv:
c1 = ch[f]
args = [c1, *args[0:]]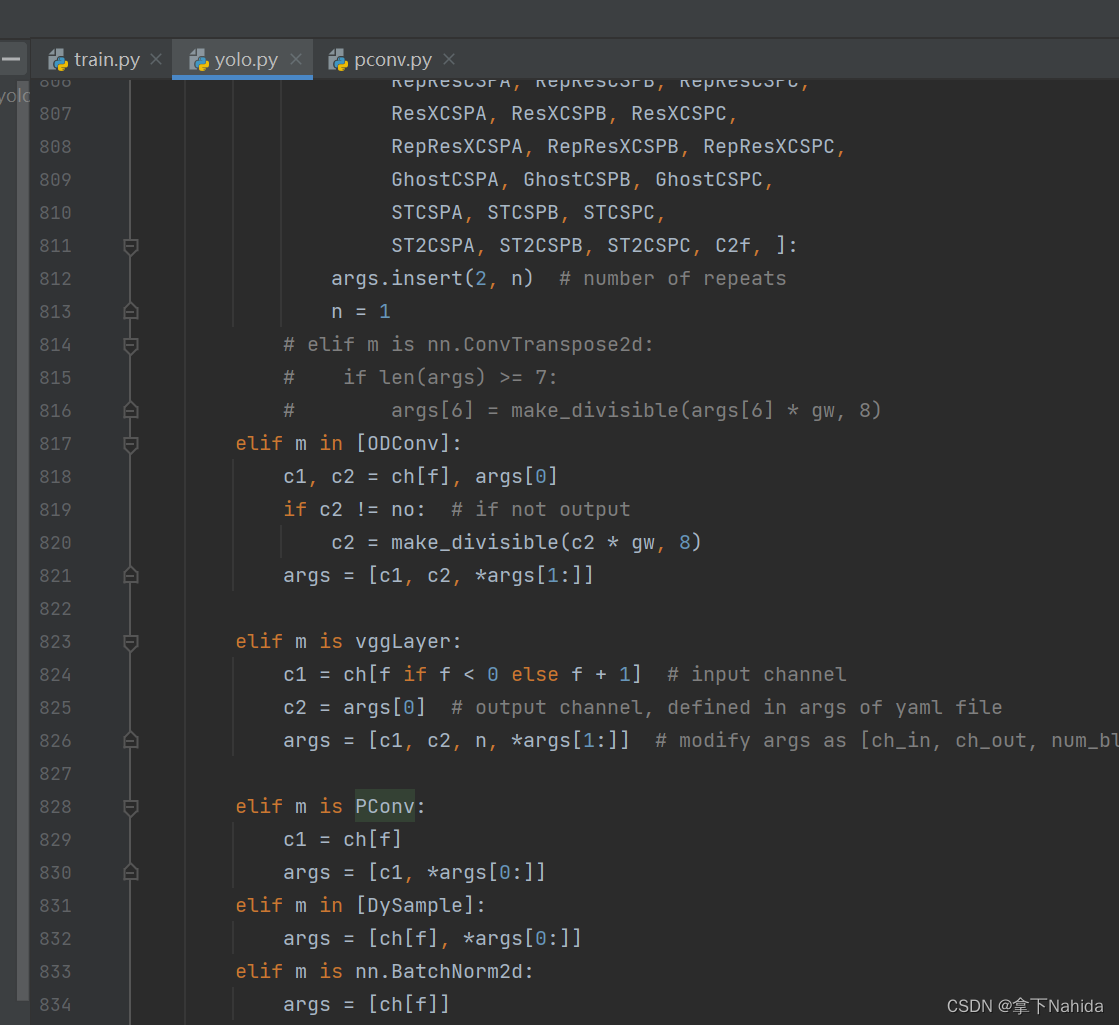
三、YOLOv7-tiny改进工作
完成二后,在YOLOv7项目文件下的models文件夹下创建新的文件yolov7-tiny-pconv.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, Conv, [32, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 0-P1/2
[-1, 1, Conv, [64, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 1-P2/4
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 7
[-1, 1, MP, []], # 8-P3/8
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14
[-1, 1, MP, []], # 15-P4/16
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 21
[-1, 1, MP, []], # 22-P5/32
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 28
]
# yolov7-tiny head
head:
[[-1, 1, v7tiny_SPP, [256]], # 29
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[21, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 39
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[14, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 49
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 39], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 57
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 29], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, PConv, [3, 4, 'split_cat']],
[-1, 1, PConv, [3, 4, 'split_cat']],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 65
[49, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[57, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[65, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[66, 67, 68], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 928 models.common.Conv [3, 32, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
2 -1 1 2112 models.common.Conv [64, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
3 -2 1 2112 models.common.Conv [64, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
4 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
5 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
6 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
7 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
8 -1 1 0 models.common.MP []
9 -1 1 4224 models.common.Conv [64, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
10 -2 1 4224 models.common.Conv [64, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
11 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
12 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
13 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
15 -1 1 0 models.common.MP []
16 -1 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
17 -2 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
18 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
19 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
20 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
21 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
22 -1 1 0 models.common.MP []
23 -1 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
24 -2 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
25 -1 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
26 -1 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
27 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
28 -1 1 525312 models.common.Conv [1024, 512, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
29 -1 1 657408 models.common.v7tiny_SPP [512, 256]
30 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
31 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
32 21 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
33 [-1, -2] 1 0 models.common.Concat [1]
34 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
35 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
36 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
37 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
38 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
39 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
40 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
41 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
42 14 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
43 [-1, -2] 1 0 models.common.Concat [1]
44 -1 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
45 -2 1 4160 models.common.Conv [128, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
46 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
47 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
48 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
49 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
50 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
51 [-1, 39] 1 0 models.common.Concat [1]
52 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
53 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
54 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
55 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
56 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
57 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
58 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]
59 [-1, 29] 1 0 models.common.Concat [1]
60 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
61 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
62 -1 1 9216 models.pconv.PConv [128, 3, 4, 'split_cat']
63 -1 1 9216 models.pconv.PConv [128, 3, 4, 'split_cat']
64 [-1, -2, -3, -4] 1 0 models.common.Concat [1]
65 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]
66 49 1 73984 models.common.Conv [64, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
67 57 1 295424 models.common.Conv [128, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
68 65 1 1180672 models.common.Conv [256, 512, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]
69 [66, 67, 68] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 256 layers, 5737996 parameters, 5737996 gradients, 13.0 GFLOPS运行后若打印出如上文本代表改进成功。
四、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-pconv.yaml,导入如下代码。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, PConv, [3, 4, 'split_cat']], # add
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 147456 models.pconv.PConv [512, 3, 4, 'split_cat']
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 249 layers, 5987062 parameters, 5987062 gradients, 15.1 GFLOPs运行后若打印出如上文本代表改进成功。
五、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5n-pconv.yaml,导入如下代码。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, PConv, [3, 4, 'split_cat']], # add
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
from n params module arguments
0 -1 1 1760 models.common.Conv [3, 16, 6, 2, 2]
1 -1 1 4672 models.common.Conv [16, 32, 3, 2]
2 -1 1 4800 models.common.C3 [32, 32, 1]
3 -1 1 18560 models.common.Conv [32, 64, 3, 2]
4 -1 2 29184 models.common.C3 [64, 64, 2]
5 -1 1 73984 models.common.Conv [64, 128, 3, 2]
6 -1 3 156928 models.common.C3 [128, 128, 3]
7 -1 1 295424 models.common.Conv [128, 256, 3, 2]
8 -1 1 296448 models.common.C3 [256, 256, 1]
9 -1 1 164608 models.common.SPPF [256, 256, 5]
10 -1 1 33024 models.common.Conv [256, 128, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 90880 models.common.C3 [256, 128, 1, False]
14 -1 1 8320 models.common.Conv [128, 64, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 22912 models.common.C3 [128, 64, 1, False]
18 -1 1 36992 models.common.Conv [64, 64, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 74496 models.common.C3 [128, 128, 1, False]
21 -1 1 147712 models.common.Conv [128, 128, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 36864 models.pconv.PConv [256, 3, 4, 'split_cat']
24 [17, 20, 23] 1 8118 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]
Model Summary: 249 layers, 1505686 parameters, 1505686 gradients, 4.0 GFLOPs运行后打印如上代码说明改进成功。
六、注意事项
一般来说,PConv只适用于替换YOLO网络中3x3、步调为1的卷积,如
本文只是作为一个示例更改,实际更改需根据自己的需求与实际情况进行替换。
对于本文存在疑问的地方欢迎评论区讨论,也欢迎读者训练后或发现问题进行反馈以便我持续更新该文章!
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!



















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











