






前言
近年来,图神经网络(GNN)和Transformer模型分别凭借其独到的优势,在处理复杂数据结构和识别序列间的相互依赖性方面取得了突破性进展,这些优势使得GNN和Transformer的结合成为图表示学习领域的一个有前景的研究方向。
具体来说,Transformer的引入使GNN能够扩展感受野,捕捉复杂图拓扑信息,增强信息传递能力,提高推荐系统准确性。最重要的是还能简化模型,降低计算成本和提高训练效率。
1.TransGNN: Harnessing the Collaborative Power of Transformers and Graph Neural Networks for Recommender Systems
方法
-
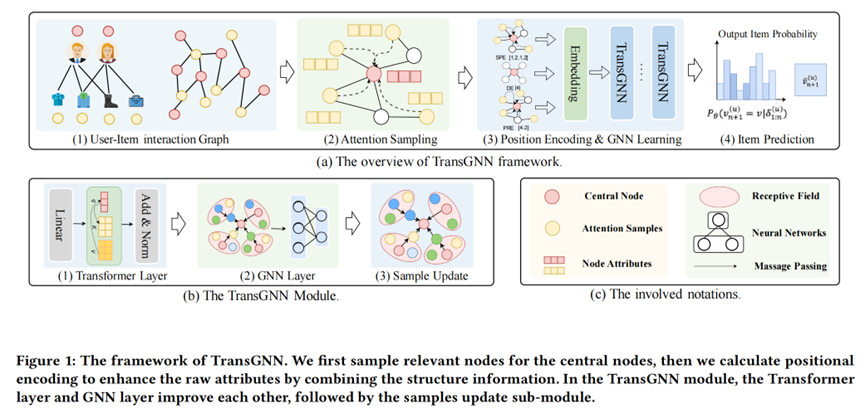
交替层结构:TransGNN采用交替的Transformer层和GNN层,以相互增强各自的能力。Transformer层用于扩大感知域并从更多相关节点聚合信息,而GNN层帮助捕获图结构信息并有效地从邻近区域聚合相关节点的信息。
-
注意力采样模块:为了减少计算复杂性并排除噪声节点的影响,TransGNN提出了基于语义和结构信息的注意力节点采样方法。
-
位置编码模块:为了帮助Transformer捕获图拓扑信息,TransGNN设计并整合了三种类型的位置编码:基于最短路径的位置编码、基于度的位置编码和基于PageRank的位置编码。
-
TransGNN模块:包含Transformer层、GNN层和样本更新子模块。Transformer层用于扩展GNN层的感知域,而GNN层帮助Transformer层感知图结构信息并获取更相关的邻居节点信息。
-
样本更新策略:提出了两种高效的样本更新方法,一种是基于随机游走的更新,另一种是基于GNN层的消息传递机制的更新。
创新点
-
Transformer与GNN的融合:TransGNN创新性地将Transformer的全局自适应信息聚合能力与GNN的图结构建模能力结合起来,以解决现有GNN方法在感知域和噪声连接方面的局限性。
-
注意力采样:通过注意力采样模块,TransGNN能够专注于对当前节点最相关的节点,这有助于减少计算复杂性并提高推荐的相关性。
-
结构信息编码:通过精心设计的位置编码,TransGNN能够将图结构信息有效地编码到节点属性中,增强了Transformer在图数据上的性能。
-
高效的样本更新策略:TransGNN提出了两种更新注意力样本的高效策略,这些策略可以轻松地推广到大规模图上,并减少了计算复杂性。
-
2.Prot2Text: Multimodal Protein’s Function Generation with GNNs and Transformers
方法
-
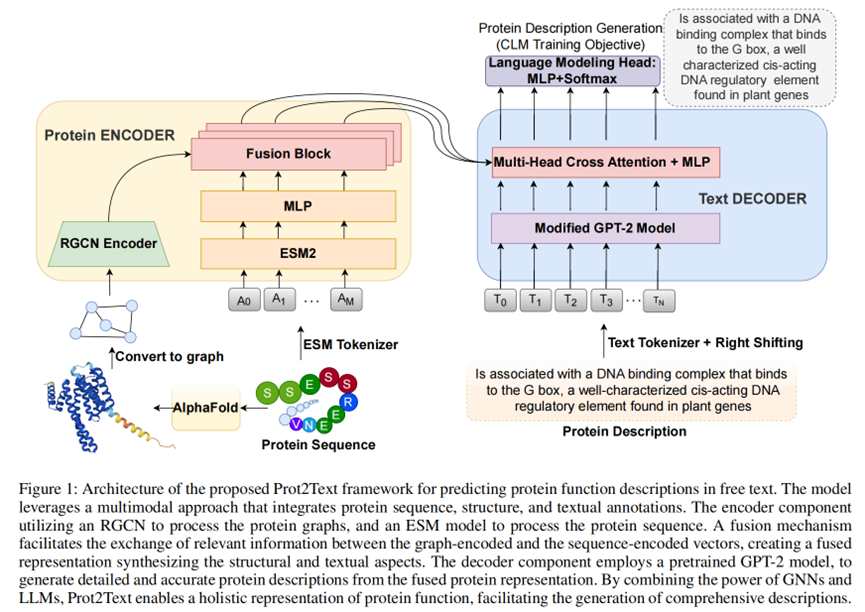
多模态框架: Prot2Text模型结合了图神经网络(GNNs)和大型语言模型(LLMs),用于生成蛋白质功能的自由文本描述。
-
编码器-解码器架构: 模型采用编码器-解码器框架,其中编码器部分使用关系图卷积网络(RGCN)处理蛋白质图,ESM蛋白质语言模型编码蛋白质序列。
-
多模态数据集: 从SwissProt数据库中提取多模态蛋白质数据集,包括蛋白质序列、结构和文本注释。
-
图构建: 利用AlphaFold获取的3D蛋白质结构,构建表示氨基酸间不同相互作用的异构图。
-
图编码: 使用RGCN对蛋白质图进行编码,通过考虑图中不同边类型的消息传递机制来更新节点表示。
-
序列编码: 使用ESM2-35M模型对蛋白质序列进行编码,捕捉氨基酸序列间的进化信息。
-
多模态融合: 通过融合块将每个氨基酸在序列中的表示与图表示向量结合,进行元素级相加和投影,实现信息整合。
-
文本生成: 使用预训练的GPT-2模型作为解码器,从融合的蛋白质表示生成详细的蛋白质描述。
创新点
-
自由文本功能描述: 与传统的多分类问题不同,Prot2Text将蛋白质功能预测任务重新构建为自由文本生成问题,允许更细致和深入地理解蛋白质功能。
-
多模态信息融合: 模型不仅整合了蛋白质的序列信息,还包括了结构信息和文本注释,提供了蛋白质功能的全面表示。
-
图神经网络与语言模型的结合: 通过结合GNNs和LLMs,模型能够处理图结构数据并生成自然语言文本,这是蛋白质功能预测中的新颖尝试。
-
公开多模态数据集: 研究者提供了一个包含256,690个蛋白质结构、序列和文本功能描述的综合数据集,供其他研究人员用于基准测试和领域内进一步的研究。
-
编码器-解码器架构的改进: 通过在编码器和解码器之间引入融合机制,模型能够更好地捕捉序列和结构之间的复杂交互和依赖关系。
-
预训练模型的应用: 使用预训练的ESM2模型和GPT-2模型,利用它们在相关任务上的强大能力,提高了蛋白质功能描述的准确性和相关性。
-
实验验证: 通过与多个基线的比较,实验结果证明了Prot2Text在生成蛋白质功能描述方面的有效性,特别是在低相似性训练样本情况下的表现。
3.Polynormer: Polynomial-Expressive Graph Transformer in Linear Time
方法
-
基础模型:提出了一个基础模型,该模型通过学习输入特征的高阶多项式来表达节点表示。模型的每一层都由一个权重矩阵和一个可训练的偏置矩阵组成,通过Hadamard积(元素级乘积)来更新节点特征。
-
多项式表达性:定义了模型的多项式表达性,即模型能够学习将输入节点特征映射到输出节点表示的高阶多项式函数的能力。
-
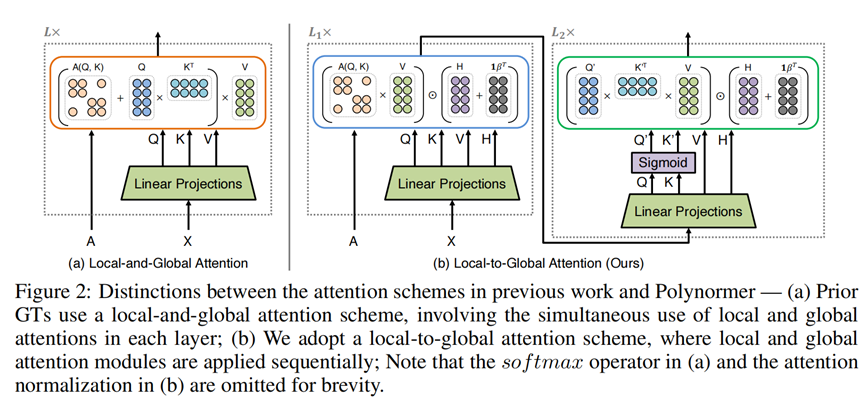
局部和全局注意力模型:为了使基础模型能够对节点排列保持等变性,论文提出了局部和全局等变注意力模型。局部注意力模型利用图拓扑信息,而全局注意力模型则利用节点特征。
-
线性局部到全局注意力方案:Polynormer采用了一种线性的局部到全局注意力方案来学习节点表示,这在语言和视觉领域的高效Transformer中是一种常见做法,但在图上的应用较少。
创新点
-
多项式表达性的图Transformer:首次提出了一个多项式表达性的图Transformer模型,该模型能够表示输入节点特征的高阶多项式,并且对节点排列是等变的。
-
局部和全局等变注意力机制:通过将图拓扑和节点特征分别整合到多项式系数中,分别导出了局部和全局等变注意力模块,这使得Polynormer能够利用局部到全局注意力机制来学习对节点排列等变的多项式。
-
无需非线性激活函数的性能提升:即使不使用非线性激活函数,Polynormer也能够在多个数据集上超越现有的GNN和GT基准模型。
-
线性复杂度:通过避免计算密集的注意力矩阵和昂贵的PE/SE方法,Polynormer的局部到全局注意力方案具有线性复杂度,使其能够扩展到具有数百万节点的大型图。
-
广泛的实验验证:在包括同质和异质图在内的13个数据集上进行了广泛的实验验证,包括具有数百万节点的大型图,展示了Polynormer的有效性。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









