






 本文探讨了图神经网络(GNN)与Transformer之间的联系,指出GNN通过邻域聚合学习图中节点的表示,而Transformer利用注意力机制在文本中捕捉单词间的相互依赖。将句子视为全连接图,可以发现Transformer的工作原理与GNN类似,都是通过节点(单词)间的信息交换来构建表示。
本文探讨了图神经网络(GNN)与Transformer之间的联系,指出GNN通过邻域聚合学习图中节点的表示,而Transformer利用注意力机制在文本中捕捉单词间的相互依赖。将句子视为全连接图,可以发现Transformer的工作原理与GNN类似,都是通过节点(单词)间的信息交换来构建表示。
1.首先我们看以下两个图:左图为图及其邻接矩阵,右图为transformer中注意力的可视化结果。
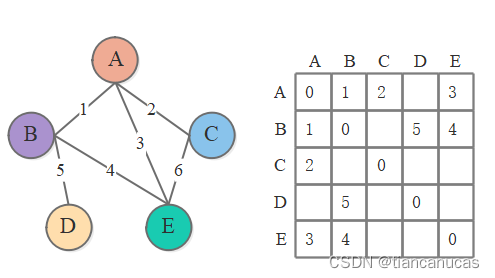
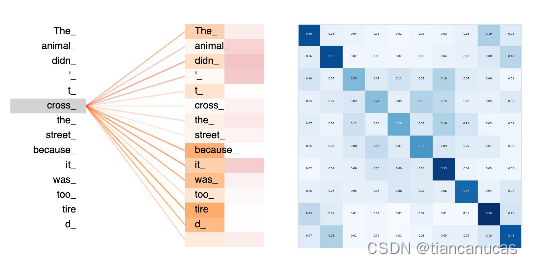
2.GNN图的表示学习transformer是文本的表示学习
GNN可以看作是建立了图中节点和边的表示,通过邻域聚合来实现,每个节点从其邻域收集特征,以更新其周围的局部图结构表示。通过堆叠多个GNN层使得该模型可以将每个节点的特征传播到整个图中,从其邻居传播到邻居的邻居。节点的表示受自身及邻居节点点影响,GNN学习的是node embedding。
Transformers在不用递归的情况下来进行文本的表示学习,使用注意力机制构建每个单词的特征,找出句子中的其他词对于当前的重要程度。知道了这一点,单词的特征更新就是所有其他单词特征的线性变换的总和,并根据它们的重要性进行加权。当前词受自身及上下文词语的影响,Transformer学习的是word embedidng。
3.句子就是词语的全连接图
为了让 Transformer 和图神经网络的关系更直接,我们可以将一个句子想象为一个全连接图,每个词都和其余的词相连接。就可以使用GNN来为图(句子)中的每个节点(单词)构建特征,这就是transformer所在做的工作。


















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









