






大模型面经——大模型训练中出现loss突刺的原因和解决方法详解
本篇主要介绍大模型训练时出现loss突刺(loss spike)的原因与解决方案。
需要先说明一下,其实在参数量级较少(6B~7B)的情况下出现小的loss波动是很正常的,这里的loss spike指的是大参数量级(100B以上)的大模型在预训练过程中loss暴涨的情况。
本篇是大模型训练微调实践经验最后一篇,该系列其他文小伙伴们也可以了解一下。
下面是本文的快捷目录。
一、大模型训练突刺是什么
二、大模型训练为什么会出现loss突刺
三、大模型训练出现loss 突刺怎么解决?
一、大模型训练突刺是什么
loss spike指的是大模型(100B以上)在预训练过程中出现的loss突然暴涨的情况。如下图
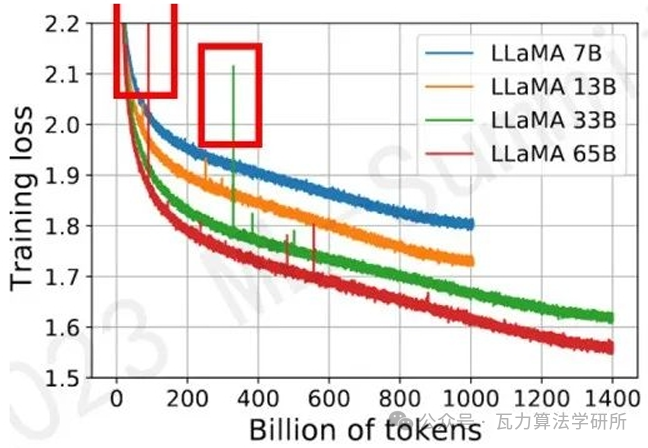
图中训练过程中红框中突然上涨的loss尖峰就是loss突刺(loss spike);
当出现这种情况以后,模型需要很长时间才能再次回到spike之前的状态(论文中称为pre-explosion),更严重的情况就是loss 再也没办法回来了,即模型再也无法收敛。
PaLM和GLM130b之前的解决办法是找到loss spike之前最近的checkpoint,更换之后的训练样本来避免loss spike的出现。
二、大模型训练为什么会出现loss突刺
首先讲结论:
loss spike的出现与梯度更新幅度,优化器中ε 大小,batch大小这三个条件密切相关:
大模型训练中使用Adam优化器,造成梯度变化与更新参数变化不满足独立性,浅层参数长时间不更新,并且大模型训练中batch太大,后期梯度更新又趋于平稳导致的Loss spike。
下面具体来讲讲为什么。
1. Adam优化器原理
吴恩达老师说过,梯度下降(Gradient Descent)就好比一个人想从高山上奔跑到山谷最低点,用最快的方式(steepest)奔向最低的位置(minimum)。优化器就是让梯度下降走得更顺利最终达到我们期望的目的地的工具。
Adam优化器,结合AdaGrad和RMSProp两种优化器的优点。
其对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
我们来具体看一下更新规则。
已知t时间步的梯度为
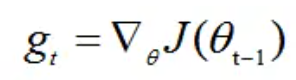
- 首先,计算梯度的指数移动平均数,m0 初始化为0。
这里类似于Momentum算法,需要综合考虑之前时间步的梯度动量。
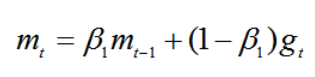
β1 系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值;默认为0.9。
下图简单展示出时间步1~20时,各个时间步的梯度随着时间的累积占比情况。
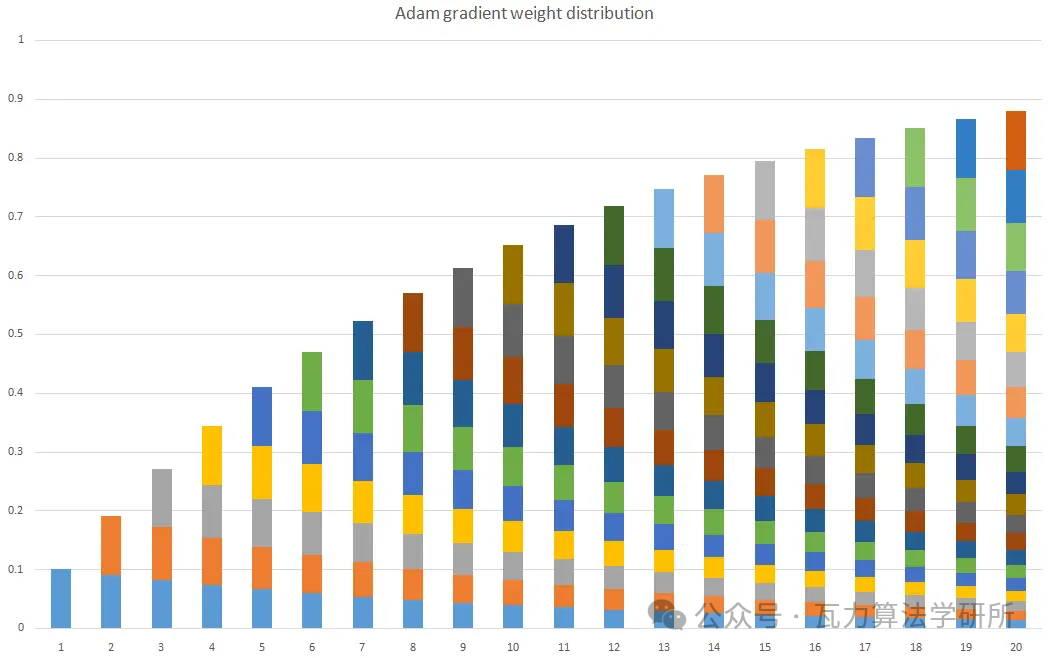
- 其次,计算梯度平方的指数移动平均数,v0初始化为0。
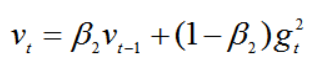
β2 系数为指数衰减率,控制之前的梯度平方的影响情况;类似于RMSProp算法,对梯度平方进行加权均值。默认为0.999。
- 第三,对梯度均值mt进行偏差纠正
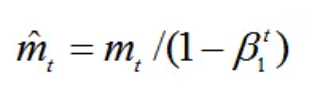
这里是由于m0初始化为0,在训练初期阶段会导致mt偏向于0;所以,此处需要对梯度均值mt进行偏差纠正,降低偏差对训练初期的影响。
- 第四,与m0 类似,因为v0初始化为0导致训练初始阶段vt 偏向0,对其进行纠正。
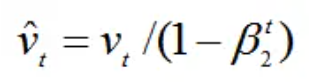
- 第五,更新参数,初始的学习率α乘以梯度均值与梯度方差的平方根之比。
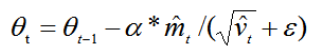
表达式中,默认学习率α=0.001,ε=10^-8,避免除数变为0。
由表达式可以看出,对更新的步长计算,能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。
2. 原因解释
可以看出来,Adam算法本质是牛顿下降法的一个迭代逼近。

整个过程看上去是很优美的,但收敛过程并没有想象中顺利。
我们来预设一个理想的ut更新参数的变化趋势:
在t=1的初始状态时,u1集中在+1,-1附近;
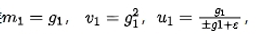
训练到最后时,模型会收敛到某个最优点,此时un集中在0附近。
也就是说,更新参数变化过程可以想象成一个两端(非稳态)向中间(稳态)收拢的过程。
实际观察到的现象也是如此,见下图

进入正态分布的稳态之后,理想的更新参数变化趋势应该是方差越来越小,所有更新参数逐渐向0靠近。
理论上应该是一个单向的过程,即稳定的单峰状态(unimodal)不会再次进入非稳定的双峰状态 (bimodal),但事实并非如此,更新参数会再次进入非稳定的双峰状态。
理论总结:从中心极限定理(可以结合道尔顿板实验理解)出发,随机事件的叠加进入单峰的正态分布的必要条件之一是各个随机事件事件之间应该是相互独立的,但是梯度变化以及更新参数的变化并不能特别好的满足独立性这一条件,易导致更新参数振荡,loss spike出现以及loss 不收敛。
另外loss spike也跟模型训练时浅层参数长期不更新有关,下面我们对loss spike出现前后的模型变化进行分析:
1)当前模型处在稳态(健康状态),即单峰的正态分布状态,并且梯度值 |gt|>>ε,此时loss平稳,训练过程正常;
2)模型浅层(embedding层)梯度|g|<<ε,这一般是由于训练一段时间之后,浅层的语义知识表示此时一般已经学习得较好。但此时深层网络(对应复杂任务)的梯度更新还是相对较大;
3)一段时间浅层(embedding层)梯度 |gt| << ε 之后会导致 |mt| << ε, ε。此时vt趋于0。因此导致浅层参数得不到更新(也对应于上述参数更新事件不独立的原因)
4)此时虽然浅层(embedding层)参数长时间不更新,但是深层的参数依然一直在更新。长时间这样的状态之后,batch之间的样本分布变化可能就会直接导致浅层(embedding层)再次出现较大的梯度变化,变成双峰的非稳定状态;
这里需要补充两个点:
- 为什么小模型不会出现这种情况?
小模型函数空间小,无法捕获样本的分布变化,越大规模的模型对样本之间不同维度的特征分布变化越敏感
- 为什么更换样本重新训练有可能会减少Loss spike的出现频率?
本质上就是选择分布变化较小的样本,减小浅层梯度变换幅度
5)这个阶段模型处于非稳态,梯度变化幅度较大,每一次的梯度变化和更新参数变化事件之间又出现了一定的独立性,因此经过一定的时间之后模型有可能再次进入稳态,loss再次回到之前的状态,也可能直接飞了再也无法收敛。
最后我们用比较简单的话总结一下,
loss spike本质原因是梯度变化以及更新参数的变化并不能特别好的满足独立性,导致随机事件的叠加难以按照理想状态进入单峰的正态分布;
表现出来就是浅层网络参数突然进入到了之前长时间不在的状态;并与模型深层参数当前的状态形成了连锁反应造成了模型进入非稳态;一般情况即使出现loss spike也会自动回复到正常状态,但也有概率可能模型直接没法收敛。
三、大模型训练出现loss 突刺怎么解决?
这里给一些参考,大家也可以再自己发挥想一想。
\1. 更换batch样本 :常规方法,但是成本比较高
\2. 减小learning rate:治标不治本,对更新参数的非稳态没有做改进
\3. 重新定义在vt=0时候的值
根据公式
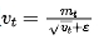
可以减小ε大小,或者直接设置ε为0,
\4. 把浅层梯度直接乘一个缩放系数来减小浅层梯度更新值

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









