






前言
经典RAG应用的范式与架构已经非常流行,我们可以在很短的时间内借助成熟框架开发一个简单能用的RAG应用。
但是传统的RAG系统有个非常大的局限,即不善于处理复杂关系推理、总结性问题和多跳问题。因为传统RAG需要对文本进行分块,然后进行向量化存储,这种处理模式就会天然导致RAG在全局查询或总结上的表现不会太好。比如面对这样的问题,“《跨越鸿沟》这本书整体上讲了什么?请撰写一份2000字的总结”,传统RAG大概率会表现不及格。
同样的,在对文本分块之后,可能会丢失一些信息之间的关系和因果性,因此在处理多跳问题时,会出现逻辑关系断裂的问题。比如面对这样的问题,“在华东区所有的门店中,哪个导购的消费者客单价最高”,传统RAG系统可能会给出错误的答复。
这正是知识图谱和GraphRAG可以发挥作用的场景。
1. 知识图谱与GraphRAG
知识图谱是一种将将信息表示为实体(节点)和关系(边)的网络,模仿了人类结构知识的组成方式。知识图谱不仅能捕获原始信息,还能捕获跨越多个文档的高阶关系,并具备强大的推理能力。
知识图谱的信息存储可以使用图数据库,图数据库是一种专门用于存储和操作图结构数据的数据库管理系统,如下图所示。与关系型数据库不同,图数据库使用节点、边和属性来表示和存储数据,非常适合处理高度连接的数据,提供高性能的复杂查询能力,用来遍历与发现有洞察力的数据关系。其最大特点是:
-
灵活的模型:可以方便地表示复杂的关系。
-
高效的查询:特别是多跳关系的查询,比关系数据库更高效。
-
可扩展性:能够处理大量节点和边。
目前流行的图数据库包括Neo4j,OrientDB、TigerGraph等等。
我们接着来说GraphRag,它是一种将知识图谱与Rag相结合的技术范式。传统Rag是对向量数据库进行检索,而GraphRag则对存储在图数据库中的知识图谱(而非存储在向量数据库中的知识向量)进行检索,获得关联知识并实现增强生成的。
GraphRAG在整体架构与传统RAG非常相似,也是需要先建立索引,然后再通过检索召回,生成最终输出。区别在于,GraphRAG采用了图数据库进行索引构建和检索召回。
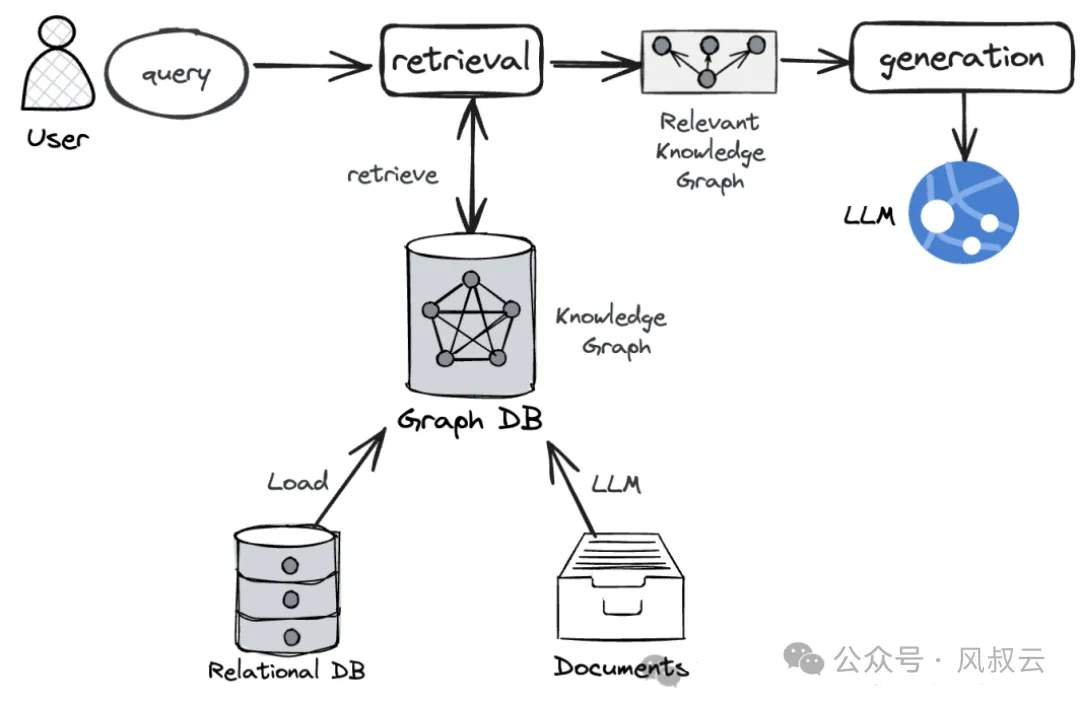
基于图数据库进行知识图谱检索的时候,有两种常见方式:
第一种是借助Text-to-GraphQL,即将自然语言输入转换为图数据库的查询语言,比如Neo4j的Cypher语言,再使用图数据库的查询语言从知识图谱中检索出需要的知识,这是一种精确的检索方式。
第二种是借助Vector索引,即在构建的Graph基础上,对其中的节点与关系创建向量索引,并通过向量相似性来检索出相关的节点和关系信息,还可以结合传统的关键词做混合检索,这种检索方式的精确度不如上一种。
2. GraphRAG适合的应用场景
下面我们来分析一下GraphRAG适合的场景,通常来说,具备如下特征的数据和场景更适合使用GraphRAG。
第一类是有较多相互关联实体与复杂关系,且结构较明确的数据。比如:
-
人物关系网络数据:社交网络中的用户关系、历史人物关系、家族图谱等。
-
企业级关系数据:公司结构、供应链、客户等之间的关系。
-
医学类数据:疾病、症状、治疗、药物、传播、病例等之间复杂关系。
-
法律法规数据:法律条款之间的引用关系、解释、判例与适用法律条款的关系。
-
推荐系统数据:产品、用户、浏览内容、产品之间的关联、用户之间的关系等。
第二类是涉及复杂关系、语义推理和多步逻辑关联的查询,比如:
-
多跳关系查询:在华东区所有的门店中,哪个导购的消费者客单价最高?
-
知识推理查询:根据患者的症状和病史,推断可能的疾病并提供治疗方案。
-
聚合统计查询:在《三国演义》中,出场次数最多的人是谁?
-
时序关联查询:过去一年都有哪些AI大模型的投资与并购事件?
-
跨多文档查询:在《三体3》中,有哪些人物在《三体1》中出现?
基于GraphRAG的特点,我们可以提炼出一些GraphRAG适合的应用场景
-
智能客服:将产品手册或说明文档映射到知识图谱中,解答消费者各式各样的售后问题,不需要提前准备QA对,也不需要提前对问题进行扩写,GraphRAG可以在精确理解用户意图的基础上进行查找。
-
智能检修:通常电气设备的产品说明短则几百页,长则数千页,即便是最资深的运维工程师也很难完全消化。因此,可以将设备的故障排除指南映射到知识图谱中,当设备出现故障时,方便工程师快速排查和解决问题。
-
智能问诊:在医学领域,病人的症状和病因之间存在着非常复杂的因果关系,同时医学领域对精准度的要求也非常高,因此非常适合GraphRag的使用,比如智能问诊
-
**药物合成:**在医药领域,存在非常多的分子化合物,每种分子化合物的特性都相差迥异,不同的分子还能结合成新的分子化合物,其中的排列组合不胜枚举。因此,可以将各种已经发现的分子化合物的结构、特征映射到知识图谱中,帮助生物学家更高效地发现有益的大分子结构。
-
报告总结:在金融领域,行业分析师每天都要阅读海量的市场信息或研究报告,过去都得完全依靠人工提炼和总结。而通过GraphRAG,构建智能投研、智能投顾等系统,帮助研究员快速提炼分析报告的核心内容。
GraphRAG虽然强大,但是相比传统RAG,其成本要高出不少。因此在以下常规场景下,我们还是尽量使用传统RAG。
首先,当大多数查询集中在单个实体上时,传统的 RAG 就够用了,因为相关的上下文很可能包含在以实体为中心的文档中,构建知识图谱会额外增加大量成本。其次,对于小型且垂直的语料库(几百个文档),仅对文档本身进行索引可能已经足够,即使存在一些文档间的关系。第三,如果主要目标是理解主题和叙事,比如社交媒体的负面评价分析,重点更多地放在语言上而不是关系上,使用传统Rag也绰绰有余。
下面,我们结合实际的源代码,介绍一下GraphRAG的实战技巧。风叔选了两个场景:一个是利用pdf、word等非结构化数据,实现内容的推理总结;另一个是利用MySQL结构化数据,实现精确查询。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

3. GraphRAG实战之推理总结
构建一个非结构化数据的GraphRAG应用,首要任务是把非结构化数据转换成以图结构表示的知识图谱,并存储到GraphDB如Neo4j,用来提供后续检索与生成的基础。
从非结构化文本到知识图谱,借助LLM是一种常见且高效的方法。即利用LLM强大的语义理解与推理能力,从非结构化文本中抽取大量的类似实体-关系-实体的三元组,并借助必要的接口(如GraphDB支持的查询语言)导入到GraphDB中创建对应的实体、关系与属性,形成知识图谱。
第一步,将非结构化数据存储进GraphDB
这里的核心是基于LLM而实现的Extractor,即Graph结构的抽取组件。在不同的框架中有不同的组件实现,这里我们以LlamaIndex框架为例,其实现的核心组件为LLMPathExtractor,一般用最简单的SimpleLLMPathExtractor进行代码实现即可。
llm = OpenAI(model="gpt-4o")
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
#加载数据
documents = SimpleDirectoryReader(input_files=['./dreamcity.txt']).load_data()
#图数据库
from llama_index.graph_stores.neo4j import Neo4jPropertyGraphStore
from llama_index.core import PropertyGraphIndex
from llama_index.core.indices.property_graph import SimpleLLMPathExtractor
#neo4j存储
graph_store = Neo4jPropertyGraphStore(
username="***",
password="***",
url="bolt://localhost:7687",
)
#知识抽取的提示词
prompt = '''
下面提供了一些文本。根据文本,提取最多 {max_knowledge_triplets} 个知识三元组,形式为(实体,关系,实体或属性)。避免使用停用词。仅输出三元组,不要有多余解释和说明。
---------------------
示例:
文本:麦迪是姚明的队友。
三元组:麦迪,队友,姚明
文本:阿里巴巴是马云在1999年创立的公司
三元组:
阿里巴巴,是,公司
阿里巴巴,创立于,马云
阿里巴巴,创立于,1999年
--------------------
文本:{text}
三元组:
'''
#抽取结果的解析
def parse_fn(response_str: str) -> List[Tuple[str, str, str]]:
lines = response_str.split("\n")
triples = [line.split(",") for line in lines]
return triples
#定义知识抽取器
kg_extractor = SimpleLLMPathExtractor(
llm=llm,
extract_prompt=prompt,
max_paths_per_chunk=50,
parse_fn=parse_fn,
)
#抽取创建图知识库索引(本地化做持久,避免反复抽取)
if not os.path.exists(f"./index_storage"):
index = PropertyGraphIndex.from_documents(
documents,
embed_model=embed_model,
kg_extractors=[kg_extractor],
property_graph_store=graph_store,
show_progress=True,
)
index.storage_context.persist("./index_storage")
else:
print('Loading index...\n')
storage_context = StorageContext.from_defaults(persist_dir="./index_storage",property_graph_store=graph_store)
index = load_index_from_storage(storage_context=storage_context)
这里需要注意的是:
-
抽取过程最重要的工具是LLM与对应的提示词,这里用了少量示例提示模式(few-shot prompt),大家可以根据需要做优化
-
借助于PropertyGraphIndex组件,可以快速的基于文档与抽取器生成知识图谱并存储到图数据库中
-
在生成知识图谱时,需要指定嵌入模型,这是为了在生成Graph的节点时,对节点的内容或者名称生成向量,用于后续的向量检索
运行这段代码后,原始的文本将被分割成多个chunk,并用来创建label为"chunk"的多个知识图谱节点,这个节点的text属性用来存放原始的文本,同时embedding属性用来存放生成向量。
第二步,基于知识图谱的检索与生成
这里先创建一个基于关键词的检索器,注意这里的prompt,是用来抽取输入中的关键词。检索器的参数通常包括使用的大模型、提取关键词的提示词、最大提取的关键词数量、检索的路径深度等。
def parse_fn(output: str) -> list[str]:
matches = output.strip().split("^")
keywords=[x.strip().capitalize() for x in matches if x.strip()]
print(keywords)
return keywords
prompt = (
"给定一些初始查询,提取最多 {max_keywords} 个相关关键词,考虑大小写、复数形式、常见表达等。\n"
"用 '^' 符号分隔所有同义词/关键词:'关键词1^关键词2^...'\n"
"注意,结果应为一行,用 '^' 符号分隔。"
"----\n"
"查询: {query_str}\n"
"----\n"
"关键词: "
)
synonym_retriever = LLMSynonymRetriever(
index.property_graph_store,
llm=llm,
include_text=False,
output_parsing_fn=parse_fn,
max_keywords=10,
synonym_prompt=prompt,
path_depth=1,
)
再创建一个向量的检索器,注意向量检索器需要指定的是嵌入模型而非大模型,因此也无需指定提示词参数:
vector_retriever = VectorContextRetriever(
index.property_graph_store,
embed_model=embed_model,
include_text=False,
similarity_top_k=2,
path_depth=1,
)
在LlamaIndex中,可以将创建的两种类型检索器作为子检索器进行融合检索,从而形成更加丰富的上下文。借助PGRetriever这个组件即可实现:
retriever = PGRetriever(sub_retrievers=[synonym_retriever,vector_retriever])
retrieve_nodes = retriever.retrieve("主人公在遇见谁之后,有了重大的人生目标改变?")
for node in retrieve_nodes:
print(node.text)
可以直接基于上述检索器创建查询引擎,即可用来生成查询响应:
...
query_engine = index.as_query_engine(
sub_retrievers=[synonym_retriever,vector_retriever]
)
#查询
response = query_engine.query("主人公在遇见谁之后,有了重大的人生目标改变?")
print(response)
以上就是使用GraphRAG,对非结构化文本进行推理总结的过程
4. GraphRAG实战之精确查询
下面再介绍一个利用GraphRAG实现精确查询的例子。
第一步,原始MySQL数据准备
首先创建几个简单的表,可以借助工具生成必要的测试数据:
-
orders:订单表,包含客户id,产品id,数量,销售员,订单日期等。
-
custoemrs:客户信息表,包含客户id,姓名,电话,电子邮件,城市等。
-
products:产品信息表,包含产品ID,名称,单价等。
-
salespersons:销售员信息表,包含人员id,姓名,电话,所属部门等。
-
departs:部门信息表,包含部门id,部门名称等。
第二步,将MySQL数据映射到Neo4j图数据库
首先,我们将表数据读取到本地pandas的dataframe
import pandas as pd
import mysql.connector
from neo4j import GraphDatabase
def fetch_table_data(table_name):
cnx = mysql.connector.connect(
host='******',
user='******',
password='******',
database='sales'
)
cursor = cnx.cursor()
query = f"SELECT * FROM {table_name}"
cursor.execute(query)
rows = cursor.fetchall()
column_names = [desc[0] for desc in cursor.description]
df = pd.DataFrame(rows, columns=column_names)
cursor.close()
cnx.close()
return df
# 读取到dataframe
orders_df = fetch_table_data("orders")
customers_df = fetch_table_data("customers")
products_df = fetch_table_data("products")
salespersons_df = fetch_table_data("salespersons")
departs_df = fetch_table_data("departs")
然后,创建Graph的节点,可以使用Cypher的CREATE语句来批量创建节点
def create_unique_nodes_from_dataframe(df, label, unique_id_property):
# 连接到Neo4j数据库
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "******"))
# 创建一个会话来执行Cypher查询
with driver.session() as session:
# 遍历DataFrame中的每一行
for _, row in df.iterrows():
# 从行中获取唯一id的值
unique_id_value = row[unique_id_property]
# 检查是否已经存在具有相同唯一id的节点
query = f"MATCH (n:{label} {{{unique_id_property}: '{unique_id_value}'}}) RETURN n"
result = session.run(query)
if result.single() is not None:
# 已经存在具有相同唯一id的节点,跳过创建新节点
continue
# 创建一个Cypher查询来创建具有给定标签和属性的节点
properties = ", ".join(f"{key}: '{value}'" for key, value in row.to_dict().items())
query = f"CREATE (n:{label} {{ {properties} }})"
# 执行Cypher查询
session.run(query)
# 为订单创建节点
create_unique_nodes_from_dataframe(orders_df, "Order","order_id")
create_unique_nodes_from_dataframe(customers_df, "Customer","customer_id")
create_unique_nodes_from_dataframe(products_df, "Product","product_id")
create_unique_nodes_from_dataframe(salespersons_df, "Salesperson","salesperson_id")
create_unique_nodes_from_dataframe(departs_df, "Depart","depart_id")
最后,我们还要创建Graph的节点关系。这里的Cypher语句其实和SQL很类似。注意创建关系时我们使用的是MERGE,这是为了防止重复生成关系。
def create_relationships():
# 连接到Neo4j数据库
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "******"))
# 创建一个会话来执行Cypher查询
with driver.session() as session:
# 在顾客和订单之间创建关系
query = "MATCH (c:Customer), (o:Order) WHERE c.customer_id = o.customer_id MERGE (c)-[:ORDERED]->(o)"
session.run(query)
# 在销售人员和订单之间创建关系
query = "MATCH (s:Salesperson), (o:Order) WHERE s.salesperson_id = o.salesperson_id MERGE (s)-[:CREATED]->(o)"
session.run(query)
# 在产品和订单之间创建关系
query = "MATCH (p:Product), (o:Order) WHERE p.product_id = o.product_id MERGE (p)-[:IS_ORDERED_IN]->(o)"
session.run(query)
# 在销售人员和部门之间创建关系
query = "MATCH (s:Salesperson), (d:Depart) WHERE s.depart_id = d.depart_id MERGE (s)-[:BELONGS]->(d)"
session.run(query)
# 调用函数来创建关系
create_relationships()
运行以上代码,如果一切正常,将会在Neo4j数据库中看到我们创建的所有节点和关系信息。
第三步,实现GraphRag精确查询
我们可以借助LangChain中的GraphCypherQAChain组件来快速实现对Graph的检索与答案生成,这个组件的基本原理就是把输入的自然语言转换成Cypher语句,然后获得查询结果。
from langchain.prompts import PromptTemplate
cypher_generation_template = """
任务:为Neo4j图数据库生成Cypher查询。
说明:仅使用提供的模式中的关系类型和属性,不要使用任何未提供的其他关系类型或属性。
模式:{schema}
注意:不要回答任何可能要求你构建除Cypher语句之外的任何文本的问题。
确保查询中的关系方向是正确的,确保正确地为实体和关系设置别名。
不要运行会向数据库添加或删除内容的任何查询。
问题是:{question}
"""
cypher_generation_prompt = PromptTemplate(
input_variables=["schema", "question"], template=cypher_generation_template
)
qa_generation_template = """
你是一个助手,根据Neo4j Cypher查询的结果生成人类可读的响应。
查询结果部分包含基于用户自然语言问题生成的Cypher查询的结果。
查询结果:{context}
问题:{question}
如果提供的信息为空,请说你不知道答案。
如果信息不为空,您必须使用结果提供答案。
"""
qa_generation_prompt = PromptTemplate(
input_variables=["context", "question"], template=qa_generation_template
)
from langchain_community.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="******",
password="******",
)
graph.refresh_schema()
hospital_cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm=ChatOpenAI(model='gpt-4o'),
qa_llm=ChatOpenAI(model='gpt-4o'),
graph=graph,
verbose=True,
qa_prompt=qa_generation_prompt,
cypher_prompt=cypher_generation_prompt,
validate_cypher=True,
top_k=100,
)
response = hospital_cypher_chain.invoke("张三订购了哪些产品?总金额是多少")
print(response['result'])
在控制台运行可以观察到输出提示与结果,可以看到生成的完整Cypher语句和运行结果,以及最后LLM的生成答案。
通过这个例子,大家知晓了如何通过GraphRag提升精确查询能力,如前文所述,另一种提升精确查询能力的方案是text-to-SQL。根据实际测试情况发现,在关系比较简单的场景下,两者在功能上并没有太大的区别,大部分任务都可以完成。但是如果涉及较复杂的多跳查询,且在数据量较大(如100万以上)时,基于GraphRAG的检索性能会更好。
总结
整体来说,GraphRAG 擅长处理复杂、互联的数据集以及需要深度关系理解的查询。特别是在需要多层次分析和推理的情况下,GraphRAG能够显著提升信息检索的精度和深度。
然而,这种能力的提升也必然伴随着更高的系统复杂性和资源消耗。因此,在决定是否采用 GraphRAG 之前,必须仔细分析具体的应用场景、数据结构以及典型的查询模式。在简单和事实性查询、较小数据集以及简单应用场景下,传统 RAG 仍然是更理想的选择。
GraphRAG是一个非常热门的领域,很多公司都在研究如何利用图数据库,进一步提升RAG的推理和总结能力。今年,微软开源了自主研发的Microsoft GraghRAG,犹如一枚重磅炸弹,给市场带来了非常大的反响。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}