






VisRAG:清华大学&面壁智能提出了一种新的RAG思路,效果提升明显
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Retrieval-augmented generation (RAG) 让大型语言模型 (LLM) 能够借助外部知识源进行生成,但现有系统仅依赖文本,无法利用视觉信息如布局和图像,这些在多模态文档中至关重要。本文提出的 VisRAG,通过构建基于视觉-语言模型 (VLM) 的 RAG 流程,直接将文档作为图像嵌入并检索,从而增强生成效果。相比传统文本 RAG,VisRAG 避免了解析过程中的信息损失,更全面地保留了原始文档的信息。实验显示,VisRAG 在检索和生成阶段均超越传统 RAG,端到端性能提升达 25-39%。VisRAG 不仅有效利用训练数据,还展现出强大的泛化能力,成为多模态文档 RAG 的理想选择。代码和数据已公开,详见 https://github.com/openbmb/visrag。
https://arxiv.org/abs/2410.10594
1. 为啥要提出VisRAG?
检索增强生成(Retrieval-augmented generation, RAG) 已经成为解决LLM幻觉和知识更新的经典方案,典型的RAG流程是基于文本的(以下简称TextRAG),以分割后的文本作为检索单元。
但是在真实场景中,知识往往以多模态的形式出现,比如教科书、手册等。这些文档中的文本与图像交织在一起。为了从这类数据源中提取文本,通常需要一个解析阶段,这包括布局识别、光学字符识别(OCR)和文本合并等后处理步骤。虽然这种方法在大多数情况下是有效的,但解析过程还是会不可避免地引入错误,从而对检索和生成阶段产生负面影响。
TextRAG只利用了文本信息,忽略了其他模态,如图像中可能包含的信息。尽管已经对图像检索和多模态RAG进行了研究,但这些研究主要集中在预定义场景中,其中图像和描述性文本已经被正确提取和配对,与现实世界中文本和图像(包括图形)常常交错在单个文档页面内的情况有所不同。
所以,本文作者提出了一种VisRAG,旨在探索完全基于视觉语言模型(VLMs)构建纯视觉RAG流程的可行性。
2. 什么是VisRAG?
VisRAG是一种新型视觉检索增强生成系统,由VLM驱动的检索器VisRAG-Ret和生成器VisRAG-Gen组成。
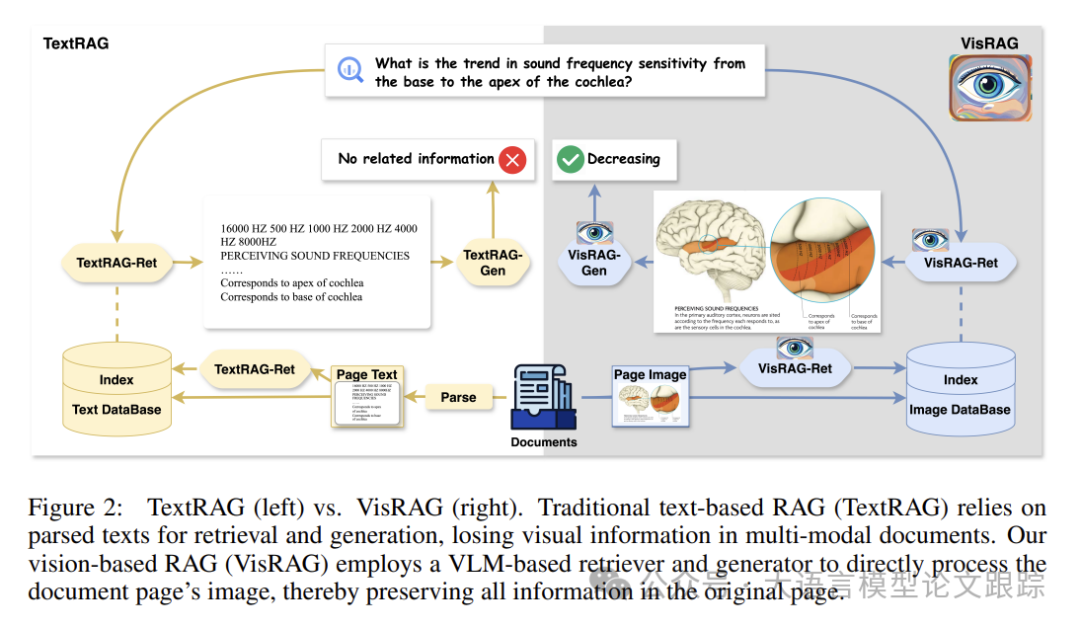
如上图(左边)所示,TextRAG 通常使用基于文本的单元进行检索和生成。右边是 VisRAG,与传统RAG框架利用文本片段进行检索和生成不同,VisRAG通过文档图像来保留全部信息,确保数据的完整性。
2.1 检索阶段
VisRAG的首个环节,即VisRAG-Ret,在给定查询q的情况下,从文档集合D中检索出一系列页面。
借鉴了文本密集检索器的 Bi-Encoder 架构,将查询和文档(直接使用文档图像,而非依赖提取的文本内容)映射到嵌入空间。
Bi-Encoders:将句子 A 和 B 独立地传递给 BERT,从而产生句子嵌入 u 和 v,然后可以使用余弦相似度比较。
查询和页面在VLM中分别以文本和图像的形式独立编码,为了得到最终的嵌入向量,采用了位置加权平均池化处理VLM的最后一层隐藏状态。
2.2 生成阶段
VisRAG的第二环节:VisRAG-Gen,利用视觉语言模型(VLM)根据用户查询和检索出的页面生成答案。考虑到检索出的页面往往都不止一页,而大多数多模态大模型只能接受单张图片,所以提出了两种方案来实现:
-
• 页面合并(Page Concatenation):将检索出的页面合并为一张图片,在VisRAG中,作者主要尝试的是水平合并。
-
• 加权筛选(Weighted Selection):让VLM为top-k中的每个页面生成一个答案,并选择置信度最高的答案作为最终答案。
3. 效果对比
3.1 检索性能
对比了VisRAG-Ret与三种情况模型进行对比:
-
• a. 现成模型
-
• b. 仅利用合成数据的跨领域模型
-
• c. 同时利用领域内和合成数据
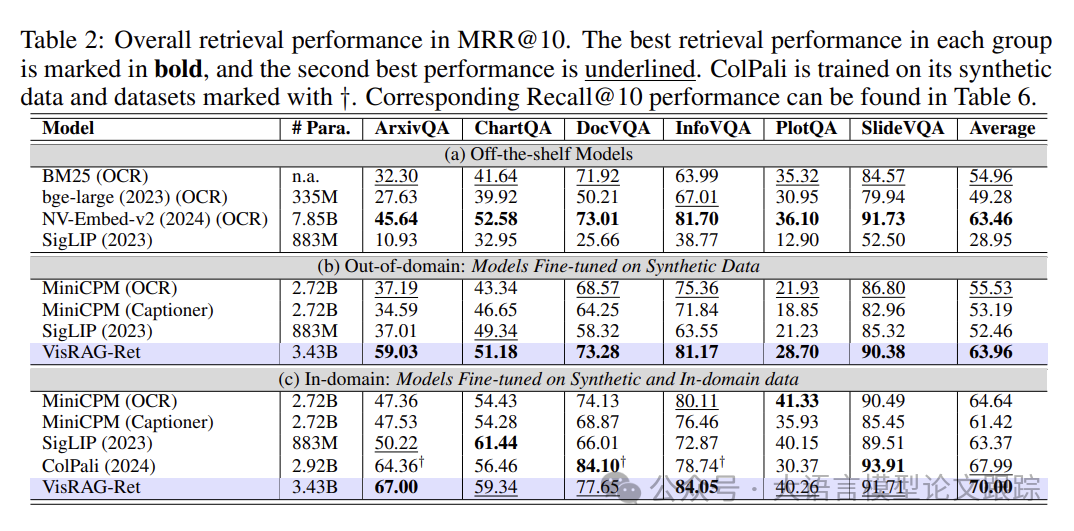
如上表(a)(b)所示,VisRAG-Ret在跨领域数据上的训练成果超越了所有现成基线模型,包括文本和视觉模型。它显著地优于BM25和bge-large,并超越了拥有7.85B参数的先进文本检索模型NV-Embed-v2。
bge-large和NV-Embed-v2是在数百万查询-文档对上训练的,比VisRAG-Ret训练数据多出10倍。尽管bge-large在MTEB等基准测试中胜过BM25,但在作者的数据集上表现不佳,表明:在干净文本上训练的嵌入模型难以应对现实世界文档解析出的文本。
当在相同的数据设置下训练时,VisRAG-Ret显著超越了文本模型MiniCPM (OCR) & (Captioner)和视觉模型SigLIP。
在跨领域环境中,VisRAG-Ret的优势更加明显,相较于MiniCPM (OCR)和SigLIP分别实现了15%和22%的提升,而在领域内环境中提升为8%和10%。说明VisRAG-Ret相比以文本和视觉为中心的模型具有更佳的泛化能力。
尽管MiniCPM (Captioner)使用了相同的VLM MiniCPM-V 2.0进行解析,但其表现不及VisRAG-Ret,这表明直接用VLMs编码比用VLMs解析更为有效。可能是因为在将多模态信息转录为文本时不可避免地会有信息损失。
MiniCPM (OCR)和SigLIP在不同数据集上的表现各异:
-
• SigLIP在ArxivQA和ChartQA中表现出色,而MiniCPM (OCR)在DocVQA和InfographicsVQA中显著优于SigLIP。这可能是因为两个模型的关注点不同:MiniCPM侧重于文本,而SigLIP侧重于视觉信号。
-
• VisRAG-Ret基于MiniCPM-V 2.0构建,结合了SigLIP编码器和MiniCPM语言模型的优势,在所有数据集上均有良好表现,能够从文档中捕获更全面的信息。
与ColPali相比,ColPali是一个多向量文档页面嵌入模型,VisRAG-Ret保持了优越的性能,实现了更佳的内存效率。ColPali用分布在1030个128维向量上的256KB数据表示一页,而VisRAG-Ret仅使用单个2304维向量的4.5KB。这使得VisRAG-Ret更适合在现实世界的应用中扩展至数百万或数十亿文档。
3.2 生成性能
在统一的检索智能体VisRAG-Ret之上,应用了多种基于文本和视觉的生成器和方法,探究它们在给定查询和检索文档的情况下生成答案的能力。
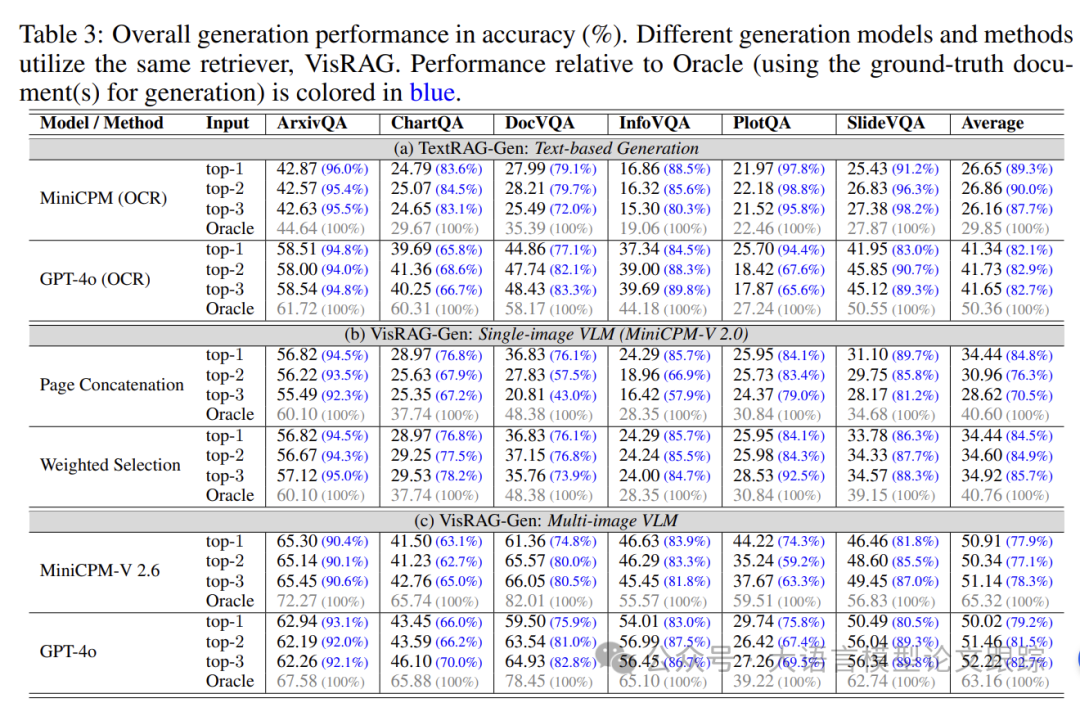
上表展示了多种生成方式的效果:
-
• a. 基于文本的生成(TextRAG-Gen)
-
• b. 采用单张图片输入的VLM MiniCPM-V 2.0进行的生成
-
• c. 采用能接受多张图片输入的VLM进行的生成
当模型仅被提供真实文档(“Oracle”)时,直接处理文档图像的VisRAG-Gen模型显著超越了仅依赖提取文本的RAG-Gen模型。比如:MiniCPM-V 2.0在利用真实文档时的性能比MiniCPM (OCR)高出36%。从文档中提取答案时视觉线索的关键作用,并显示出VisRAG-Gen相比TextRAG-Gen有着更高的性能潜力。
在实际应用场景中,模型通常会接收到包含噪声的前1至3个检索文档,VisRAG-Gen在同一系列模型中持续超越TextRAG-Gen。
特别是对于仅能处理单张图片的MiniCPM-V 2.0,加权选择方法在处理2或3个检索文档时,比页面合并方法展现出更优的表现。简单的合并可能会向VLM传递过多不必要的信息,而加权选择则基于各个文档的条件,通过多个VLM输出来筛选答案,从而减轻了信息负载。
TextRAG流程通常因检索文档数量的增加而受益,因为这能更好地覆盖信。然而,尽管加权选择增强了性能的稳健性,但采用这种方法时,随着检索文档数量的增加,并没有带来显著的性能提升。值得注意的是,仅有最先进的VLM,如能处理多张图片的GPT-4o,随着检索文档数量的增加,表现出明显的性能提升。这表明对多张图片进行推理对当前的VLM来说仍是一个挑战。
3.3 整体性能
在这项实验中,对比了VisRAG与TextRAG两条处理流程的效果,以评估VisRAG流程的有效性。
TextRAG流程中,采用了MiniCPM (OCR)负责检索,MiniCPM-V 2.6 (OCR)负责生成,而VisRAG流程则由VisRAG-Ret负责检索,MiniCPM-V 2.6负责生成。
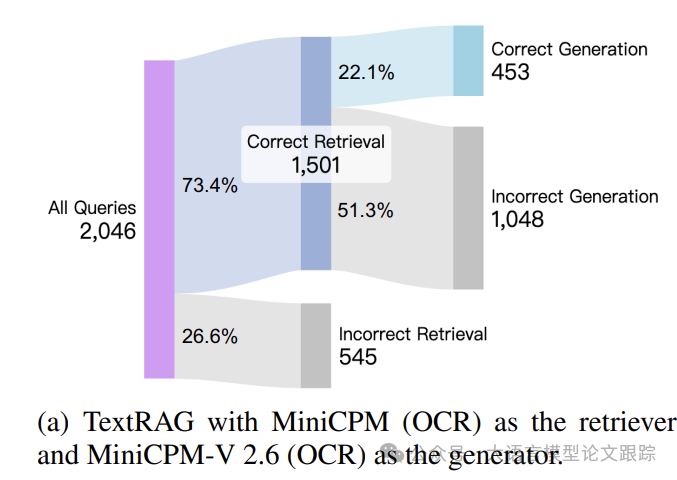
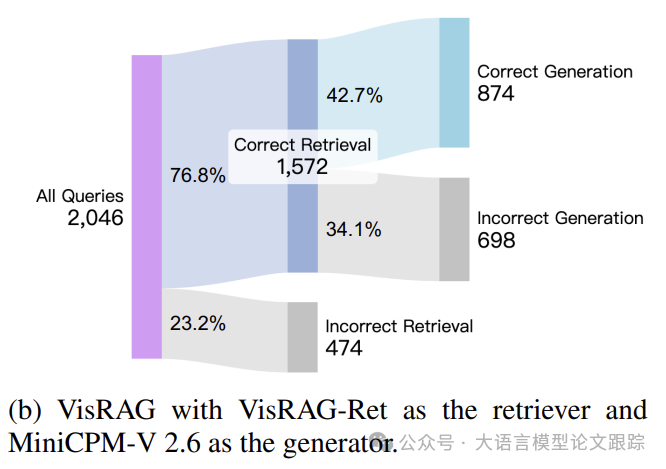
上面两个图展示了在InfographicsVQA数据集上的性能表现。
VisRAG在精确检索文档的比率上超越了TextRAG,并且在从精确检索到的文档生成正确答案的比率上也有显著提升。检索和生成两个阶段的综合改进,使得整体准确率从22.1%提升至42.7%。
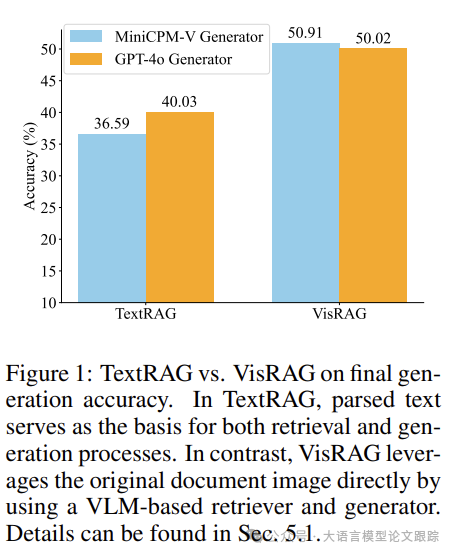
在六个评估数据集中,VisRAG平均实现了39%的准确率提升(如上图)。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}