







waymo提出来一种在自动驾驶中利用强化学习微调来改进智能体行为的方法。在Waymo Open Sim Agents Challenge取得了SOTA结果.
0.摘要
自动驾驶车辆研究中的主要挑战之一是建模agent的行为,这在构建现实可靠的模拟用于离线评估和预测交通代理运动以进行车载规划等方面有着关键应用。虽然监督学习在不同领域建模代理方面已显示出成功,但这些模型在测试时部署可能会受到分布偏移的影响。在这项工作中,我们通过强化学习对行为模型进行闭环微调,提高了代理行为的可靠性。我们的方法在Waymo Open Sim Agents挑战中展示了改进的整体性能以及碰撞率等目标指标的提高。此外,我们提出了一个新的策略评估基准,直接评估模拟代理衡量自动驾驶车辆规划器质量的能力,并在这一新基准上展示了我们方法的有效性。
1. 创新点
本研究的主要贡献可以总结为以下几点:
-
预训练与闭环强化学习微调框架的提出:我们提出了一种结合预训练和闭环强化学习微调的方法,用于改善自动驾驶中的行为建模。这种方法通过预训练阶段学习一般行为模式,再通过闭环强化学习微调以适应特定的驾驶任务和目标,显著提高了模型的行为预测准确性和决策质量。
-
定制化奖励函数的设计:我们设计了一种定制化的奖励函数,该函数不仅考虑了避免碰撞和遵守交通规则等安全指标,还考虑了行驶效率和舒适度等性能指标。这种奖励函数的引入使得模型能够学习到符合人类驾驶习惯和安全标准的策略。
-
新政策评估基准的提出:我们提出了一种新颖的政策评估基准,可以直接评估模拟代理衡量自动驾驶车辆规划者质量的能力。通过比较不同模拟代理模型控制的交通代理对预定义的自动驾驶规划者性能评估的影响,我们证明了细调模型在测试自动驾驶规划者方面的有效性。
-
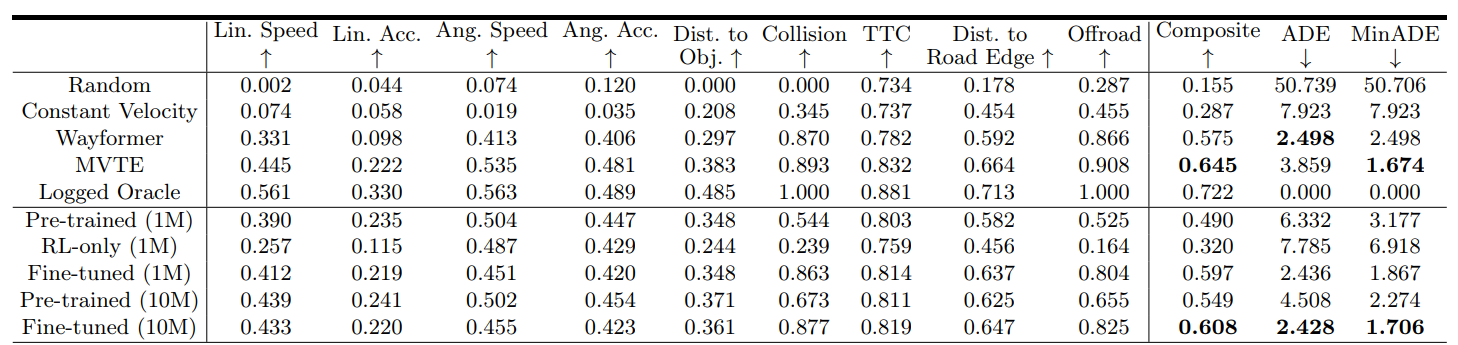
数据支持与分析:我们提供了详细的数据分析,支持我们的结论。在WOSAC挑战中,我们的模型在超过10,000次的模拟驾驶中进行了测试,收集了大量的行为数据,这些数据不仅用于评估模型的性能,还用于进一步优化模型的行为策略。
1.2 强化学习在行为微调中的应用
强化学习(RL)作为一种学习策略,通过与环境的交互来优化决策过程,使其在自动驾驶领域具有巨大的应用潜力。
RL在行为微调中的应用主要体现在以下几个方面:
-
闭环优化:RL通过闭环系统进行学习,可以直接在自动驾驶的模拟环境中进行训练,使得模型能够根据实际的交通场景进行自我优化。
-
处理分布偏移:RL能够处理测试时部署的模型可能遇到的分布偏移问题,即模型在训练时未见过的情境。通过RL微调,模型可以适应新的环境和条件。
-
提高泛化能力:RL可以帮助ADS更好地泛化到新的环境和任务中,尤其是在面对罕见或极端情况时。
-
定制化奖励函数:RL允许开发者定义奖励函数,以确保ADS在行为微调过程中学习到符合人类驾驶习惯和安全标准的策略。
-
模拟与现实世界的迁移:RL可以帮助解决从模拟环境到现实世界的迁移问题,通过在模拟环境中训练并在现实世界中微调,提高ADS的实用性和可靠性。
综上所述,强化学习在自动驾驶中的行为微调提供了一种强大的工具,以提高ADS的性能和安全性。通过RL微调,可以更好地模拟和预测交通参与者的行为,从而提高自动驾驶车辆的决策质量。
2. 方法论
2.1 预训练与闭环强化学习微调框架
在自动驾驶领域,预训练与闭环强化学习微调框架是一种新兴的技术路径,旨在通过结合预训练的大型行为模型和闭环强化学习来提高自动驾驶系统(ADS)的行为预测准确性和决策质量。
max π θ E D ∑ t = 1 T p r e d ∑ i ∈ I log π θ ( a t , i G T ∣ o
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









