






2024深度学习发论文&模型涨点之——预训练+医学图像
预训练模型在医学图像分析领域正变得越来越重要,它们通过利用大规模数据集和先进的学习策略,提高了模型的性能和效率,尤其是在数据稀缺的情况下。
1. STU-Net:具有1.4B参数的大规模预训练医学图像分割模型,它基于最大的公共数据集进行训练,并在多个挑战数据集上展现出卓越的性能。
2. SuPreM:预训练3D模型套件,它结合了大规模数据集和逐体素注释,展示了在多种3D医学成像任务中的可转移性。
3. MITER:医学图像/文本联合预训练框架,通过对比学习实现,并在多个医学任务上超越了现有基准模型。
这些研究进展表明,预训练模型通过结合大规模数据集、先进的学习策略和医学知识,不仅提高了医学图像分析的准确性,还增强了模型在新任务上的适应性和泛化能力。随着技术的进步,预训练模型有望在未来的医学图像分析中发挥更大的作用。
小编整理了一些预训练+医学图像【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“预训练+医学图像”即可全部领取
论文精选
论文1:
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
预训练视觉语言模型中的伪提示生成用于多标签医学图像分类
方法
-
伪提示生成(PsPG):利用基于RNN的解码器,自动回归生成类别定制的嵌入向量,即伪提示。
-
多模态特征利用:结合视觉全局特征和类别文本特征,生成不依赖于类别名称的完整伪提示。
-
自回归方法:通过逐步构建输出来生成序列,用于构造伪提示。
空间融合(Spatial Fusion):通过轻量级空间注意力模块,结合图像的全局和局部特征。
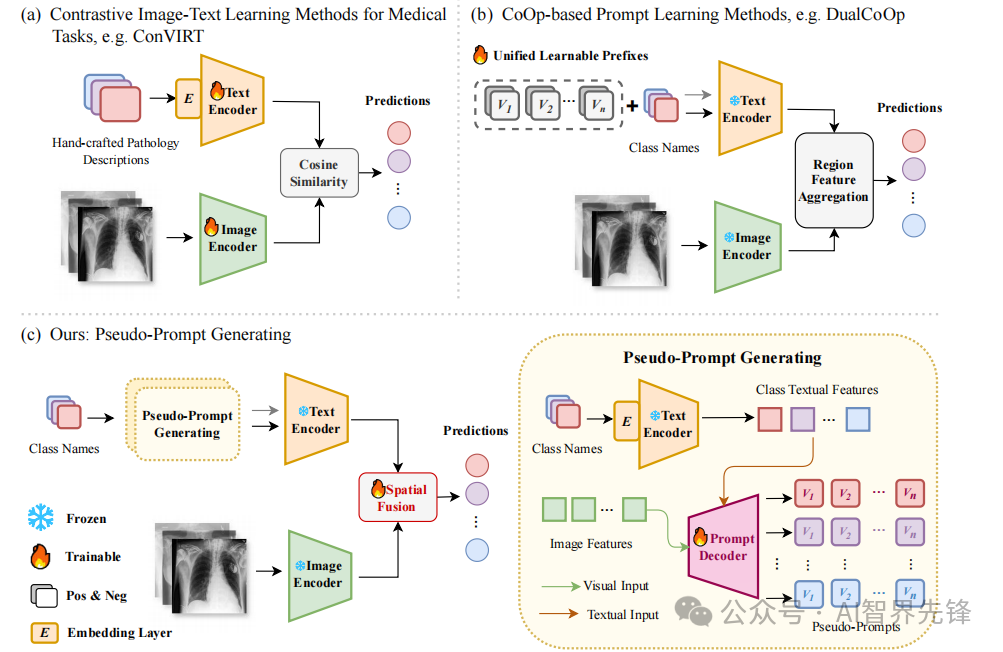
创新点
-
伪提示生成(PsPG):首次将文本生成技术应用于提示学习,生成基于多模态知识的动态伪提示,提升了多标签零样本学习的性能。在CheXpert数据集上,PsPG在Macro AUC和mAP上分别达到了85.2%和49.3%的性能,超越了其他领先的医学视觉语言模型和多标签提示学习方法。
-
空间融合(Spatial Fusion):通过引入全局和局部特征的自注意力,增强了对细粒度病理的辨识能力,提升了模型在多标签分类任务中的性能。
-
计算效率:PsPG在保持模型效能的同时,降低了计算需求,与需要大量训练数据的方法相比,PsPG展示了在多标签零样本分类任务中以显著较低的计算成本达到接近或超过最先进性能的能力。
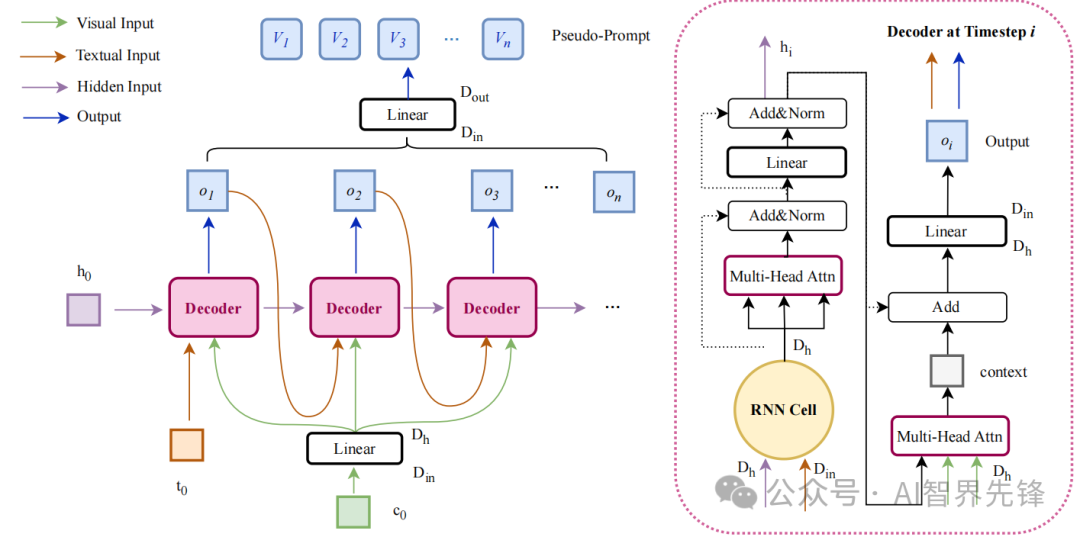
论文2:
Pre-Training Auto-Generated Volumetric Shapes for 3D Medical Image Segmentation
预训练自动生成体积形状用于3D医学图像分割
方法
-
自动生成体积形状数据库(AVS-DB):基于多边形和形状相似比率变化,自动生成3D模型的组合。
-
3D形状合成:通过在xy平面和z轴方向上定义规则并结合两者来构建3D形状。
-
形状排列:在3D空间中有意安排合成的形状以产生重叠。
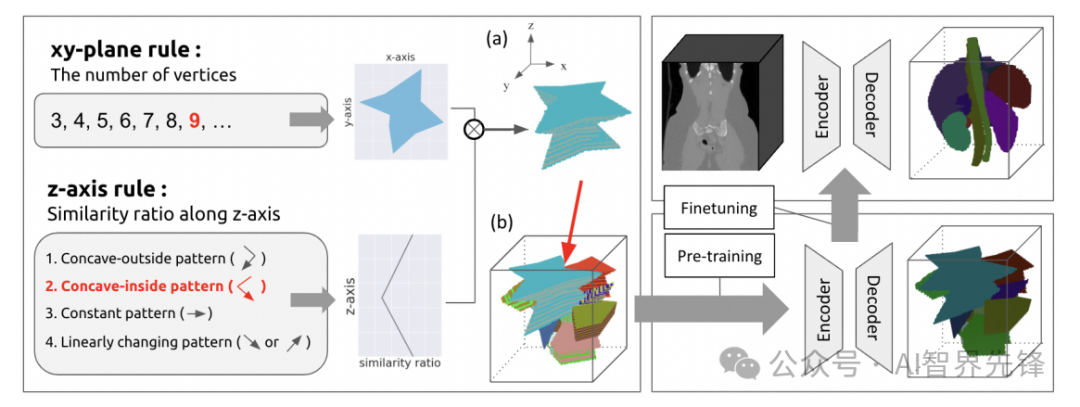
创新点
-
AVS-DB:提出了一种新的数据稀缺3D医学图像分割任务的数据预训练方法,通过自动生成的数据集显著提高了模型性能,与从头开始训练的模型相比,性能有了显著提升。
-
性能提升:在BTCV和MSD(Task06和Task09)基准数据集上,与现有自监督学习方法相比,AVS-DB预训练模型分别实现了+0.4%,+2.01%和+2.04%的性能提升。
-
数据效率:AVS-DB使得3D医学图像分割模型能够在不依赖真实世界数据的情况下,以更数据高效的方式进行预训练,解决了数据收集成本和隐私问题。

论文3:
Pick the Best Pre-trained Model Towards Transferability Estimation for Medical Image Segmentation
选择最佳预训练模型:面向医学图像分割的可转移性估计
方法
-
转移性估计(TE)方法:分析了现有TE算法在医学图像分割中的不足,并设计了一个无需源信息的TE框架,考虑了类别一致性和特征多样性以更好地估计。
-
类别一致性与特征多样性(CC-FV):通过测量样本中同一类别的前景体素的特征分布的距离来评估类别一致性,利用全局特征图中采样的特征分布的均匀性来衡量特征本身的有效性。
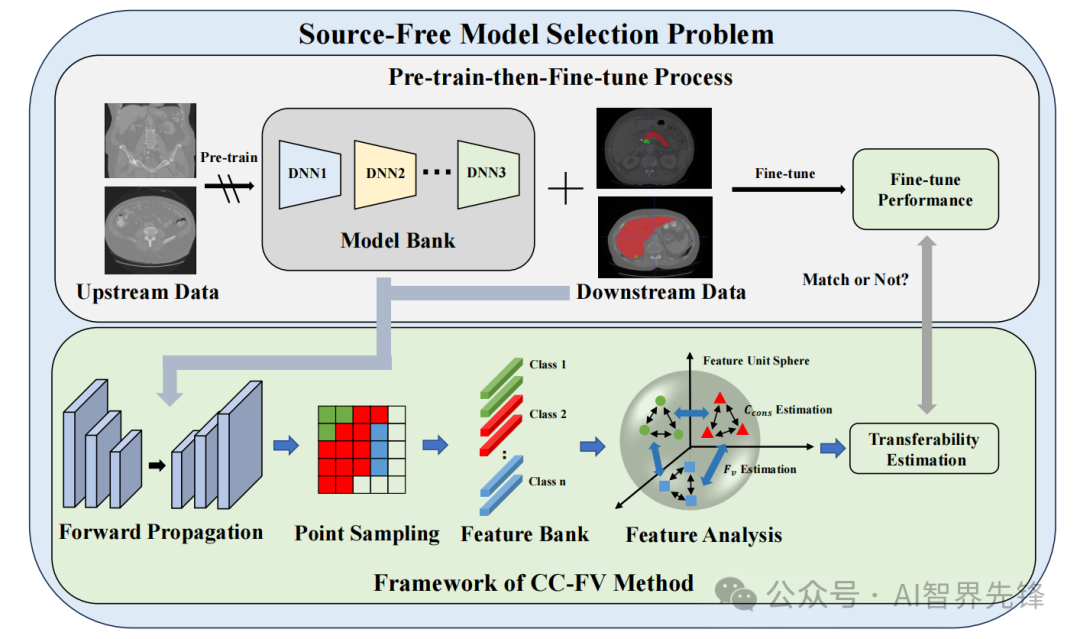
创新点
-
CC-FV TE方法:提出了一个新的方法,使用类别一致性和特征多样性来估计医学图像分割任务中的模型可转移性。在MSD数据集上的实验结果表明,该方法在转移性估计方面超越了所有当前的算法。
-
性能提升:在MSD数据集的5个任务中,CC-FV方法在Dice分数和估计值之间的相关性方面表现优于基线方法,特别是在Task03 Liver任务中,CC-FV方法的加权Kendall's 𝜋?和Pearson相关系数分别为0.6374和0.8608,显示出与DSC性能更正相关的估计结果。
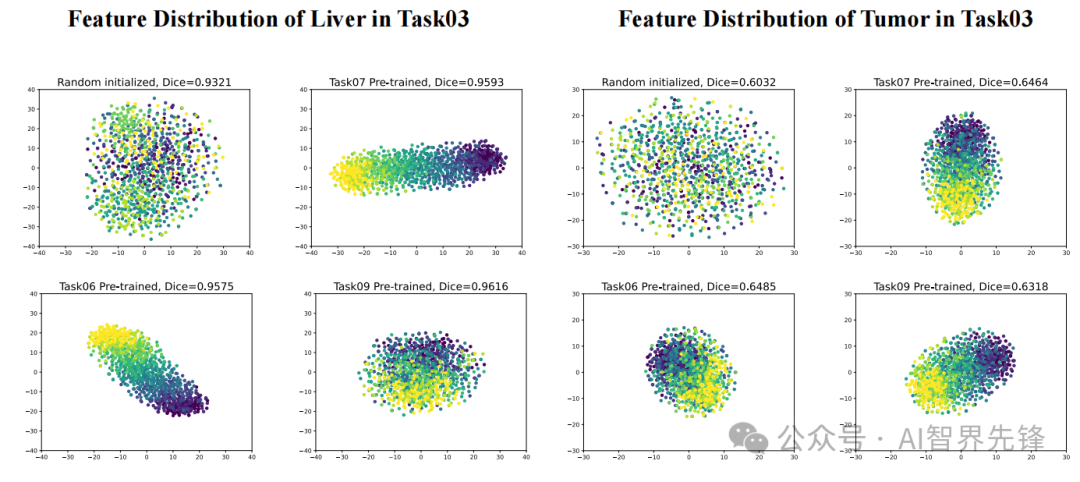
论文4:
Effect of Pre-Training Scale on Intra- and Inter-Domain Full and Few-Shot Transfer Learning for Natural and Medical X-Ray Chest Images
预训练规模对自然和医学X射线胸部图像在领域内和跨领域全额及少量镜头迁移学习的影响
方法
-
大规模预训练:结合大型公开可用的医学X射线胸部成像数据集,达到与自然图像领域中常用的ImageNet-1k相当的规模,进行监督预训练。
-
网络规模和源数据规模变化:在预训练中变化网络规模(ResNet-50x1和ResNet-152x4)和源数据规模(大型自然图像数据集ImageNet-1k/21k或大型医学胸部X射线数据集)。
-
跨领域迁移:将预训练模型转移到不同的自然或医学目标数据集上,包括全额和少量镜头迁移学习。
-
分布式训练:利用最先进的超级计算机(JUWELS Booster)进行分布式训练,以处理大规模预训练所需的计算资源。
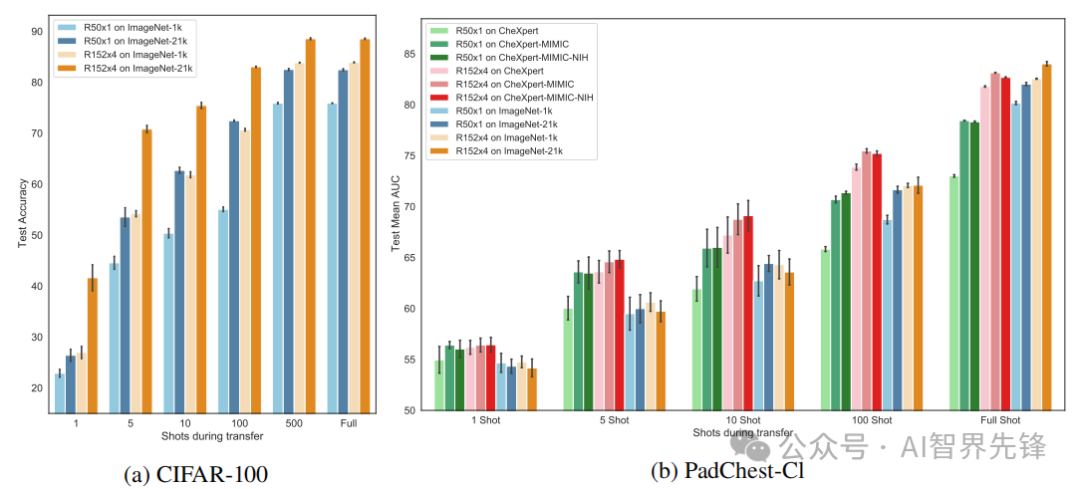
创新点
-
跨领域迁移学习:首次结合大规模自然图像和医学X射线胸部成像数据集进行预训练,以研究在领域内和跨领域全额及少量镜头迁移学习中,预训练规模的影响。
-
大规模预训练的效益:在自然-自然和医学-医学领域内迁移学习中,由于更大的预训练规模,观察到显著的性能提升。例如,在全额镜头转移中,使用ResNet-152x4和ImageNet-21k预训练的模型在CIFAR-100上达到了88.54%的准确率,比使用ResNet-50x1和ImageNet-1k预训练的模型高12.64%。
-
跨领域迁移的性能提升:在自然-医学跨领域全额镜头迁移学习中,对于较大的X射线目标,由于更大的预训练规模,观察到性能提升。例如,使用ResNet-152x4和ImageNet-21k预训练的模型在CheXpert数据集上达到了87.77%的AUC分数,比使用ResNet-50x1和ImageNet-1k预训练的模型高3.94%。
-
无需大量医学领域特定数据:研究表明,通过显著增加模型和通用自然图像源数据规模的预训练,可以获得与或优于使用大量医学领域特定X射线数据预训练的模型。例如,在全额镜头转移到大型X射线目标时,使用ResNet-152x4和ImageNet-21k预训练的模型与使用最大医学X射线超集数据预训练的模型表现相当或更好。
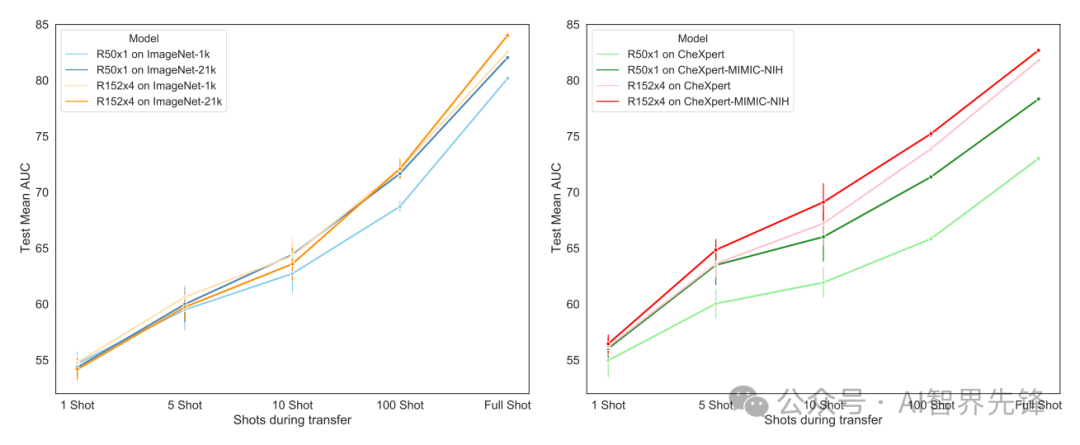
小编整理了预训练+医学图像论文代码合集
需要的同学
回复“预训练+医学图像”即可全部领取

















 6765
6765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









