



交叉注意力+特征融合的应用多光谱目标检测(ICAFusion):提出了一种新颖的双交叉注意力特征融合方法,用于多光谱目标检测,同时聚合了RGB和热红外图像的互补信息。这种方法包括单模态特征提取、双模态特征融合和检测三个阶段。通过交叉注意力机制聚合来自不同分支的特征,提升了目标检测的性能。
点云分割(2D-3D Interlaced Transformer):提出了一种多模态交错注意力变换器(MIT),用于弱监督的点云分割。该方法通过交叉注意力实现了2D和3D特征的隐式融合,增强了2D和3D特征之间的交互,提升了分割精度。
医学图像分割(CFATransUnet):提出了一种新的U形网络结构,使用Transformer和CNN块作为主干网络,配备了通道级交叉融合注意力Transformer(CCFAT)模块。。我给大家准备了10种创新思路和源码,一起来看有需要的搜索人人人人人人人工重号(AI科技探寻)免费领取
该模块通过自注意力机制重新整合不同阶段的语义信息,减少了不同级别特征之间的语义不对称性,从而提高了分割性能。 这些方法展示了交叉注意力和特征融合在多模态学习中的有效性,它们通过结合来自不同模态的信息,提高了模型在各种视觉任务中的性能和鲁棒性。
论文1
标题:
CAFF-DINO: Multi-spectral Object Detection Transformers with Cross-attention Features Fusion
CAFF-DINO:基于交叉注意力特征融合的多光谱目标检测Transformer
方法:
-
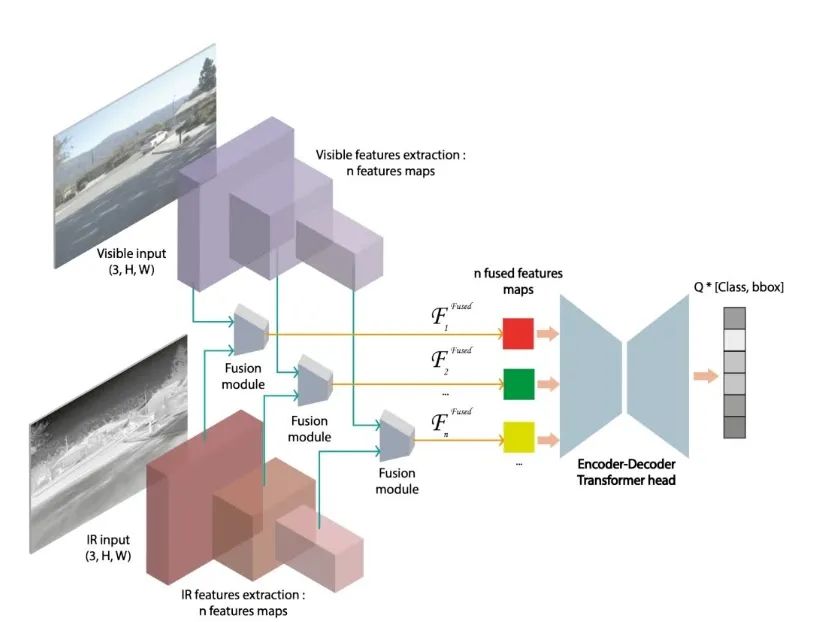
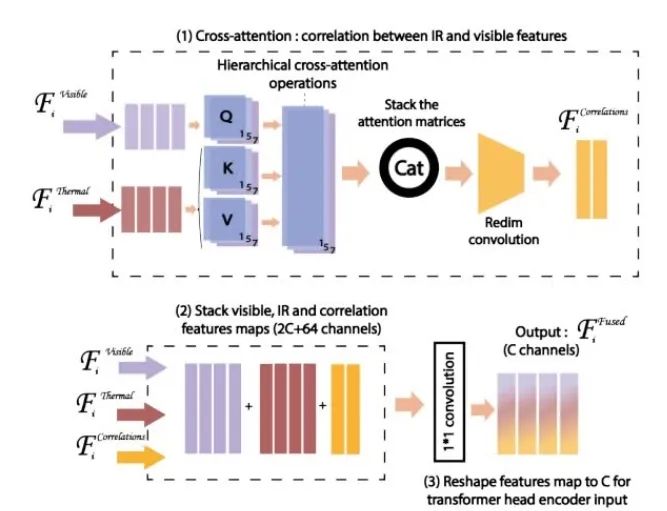
交叉注意力特征融合模块(CAFF):在红外(IR)与可见光(Vis)模态间引入交叉注意力机制,通过多尺度卷积核提取跨模态关联特征。
-
层次化融合策略:在特征提取的每一层独立执行融合,避免反向传播影响单模态主干网络,保留预训练权重。
-
通用性设计:模块可嵌入任意单模态Transformer检测器(如DINO),无需修改主干架构。
创新点:
-
性能提升显著:在LLVIP数据集上,CAFF-DINO相比CFT-YOLOv5的mAP提升4.9%(68.5% vs 63.6%);在FLIR-aligned数据集上,相比ICA-Fusion提升9.1%(50.5% vs 41.4%)。
-
鲁棒性验证:在200像素系统性IR图像错位下,CAFF-DINO的mAP仅下降21%,优于CFT-YOLOv5的27%。
-
轻量化融合:相比循环融合方法,CAFF模块参数量减少约30%,且支持直接替换单模态检测器。
论文2
标题:
Feature Fusion Based on Mutual-Cross-Attention Mechanism for EEG Emotion Recognition
基于互交叉注意力机制的EEG情感识别特征融合
方法:
-
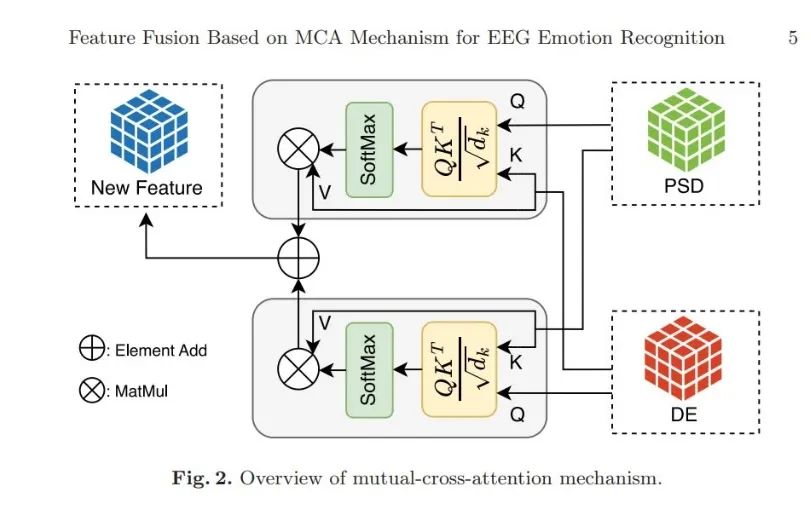
互交叉注意力(MCA):通过双向交叉注意力融合差分熵(DE)和功率谱密度(PSD)特征,分别将DE作为查询/键、PSD作为值,反之亦然。
-
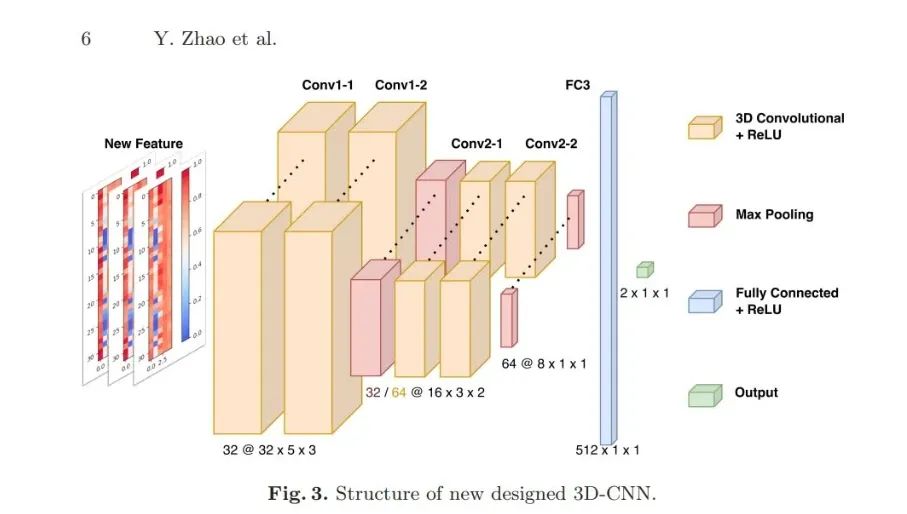
3D-CNN架构:设计Channel-PSD-DE的3D特征结构(通道×频带×时间),结合轻量级3D卷积网络实现实时分类。
-
频带划分:将4-45Hz脑电信号划分为θ、α、β、γ等5个频带,分别提取DE和PSD特征。
创新点:
-
精度突破:在DEAP数据集上,MCA-3D-CNN的效价(valence)和唤醒度(arousal)分类准确率达99.49%和99.30%,较传统DE+PSD拼接方法提升8.59%和7.99%。
-
数学可解释性:MCA为纯数学方法,无需额外网络参数,相比CNN+SVM(75.22%)和TSFFN(98.27%)显著简化模型复杂度。
-
3D特征优化:Channel-PSD-DE结构在3D-CNN下的valence精度达89.88%,优于2D拓扑结构(89.78%)和Channel-Time-Frame(87.44%)。
论文3
标题:
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合
方法:
-
-
迭代特征增强(ICFE):共享参数的迭代机制(1次迭代最优)替代堆叠Transformer块,减少参数量(120.2M vs 517.1M)。
-
混合池化压缩:采用自适应混合池化(平均+最大池化)压缩特征图,降低计算复杂度。
创新点:
-
速度与精度平衡:在FLIR数据集上,单次迭代的ICAFusion相比堆叠10个CFE模块,mAP50提升0.7%(79.2% vs 78.5%),但FPS从17.3提升至36.7。
-
鲁棒性验证:在KAIST数据集上,对200像素错位时MR仅7.85%,优于HalfwayFusion(26.67%)。
-
通用性验证:适配YOLOv5和FCOS检测头,在CSPDarknet53下KAIST的MR从8.33%降至7.17%,FLIR的mAP提升2.7%。
论文4
标题:
MMViT: Multiscale Multiview Vision Transformers
MMViT:多尺度多视角视觉Transformer
方法:
-
-
分层缩放:通过池化注意力逐步降低空间分辨率(如2×2 stride)并翻倍通道数,平衡计算与精度。
-
跨模态迁移:利用ImageNet预训练权重初始化音频模型,提出音频专用CutMix(时域切割)防止过拟合。
创新点
-
音频任务SOTA:在AudioSet全数据集上,MMViT mAP达43%,超越MViTv2(42.4%)和AST(37.2%)。
-
图像任务提升:ImageNet1K分类Top-1准确率达83.2%,较MViTv2(82.7%)提升0.5%。
-
多模态通用性:同一架构在音频(43% mAP)和图像(83.2%)任务均达SOTA,验证跨域泛化能力。

















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









