






2025深度学习发论文&模型涨点之——多模态embedding
多模态embedding的目标是将多种模态的数据表示为统一的向量形式,消除模态间的语义鸿沟,实现跨模态的理解和交互。其核心在于通过深度学习模型(如卷积神经网络、Transformer等)将不同模态的数据映射到一个共享的语义空间。
-
模型架构创新:例如CLIP模型通过对比学习将图像和文本嵌入到同一空间,实现了零样本图像分类。
-
统一多模态表征:如阿里云的GME(General MultiModal Embedding)模型,基于Qwen2-VL多模态大语言模型构建,采用对比学习方法,显著提升了多模态检索的效率和精准度。
-
数据增强策略:通过合成海量混合模态相关性数据,增强模型的表征能力和泛化能力。
- 多模态大模型的应用:多模态embedding技术在大模型中被广泛应用,如百度的文心一言和阿里云的通义千问等,推动了多模态信息处理与检索技术的发展。
小编整理了一些多模态embedding【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“ 多模态embedding”即可全部领取
论文精选
论文1:
ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map
通过模态融合图进行多模态嵌入的视觉探测与对齐
方法
-
模态融合图(Modal Fusion Map, MFM):提出了一种新颖的参数化降维方法,通过整合度量和非度量目标来增强模态融合。MFM通过将文本和图像嵌入投影到一个共同的子空间中,解决了多模态嵌入中的模态差距问题。
嵌入探测:利用MFM对多模态嵌入进行可视化探测,帮助用户发现嵌入空间中的概念纠缠和错位。
嵌入对齐:设计了一种交互式对齐方案,允许用户在点集和集合级别上进行对齐操作,包括点集对齐和集合对齐。
概念轴视图:引入了概念轴视图,允许用户在文本嵌入空间中探索图像嵌入与文本概念的关系。
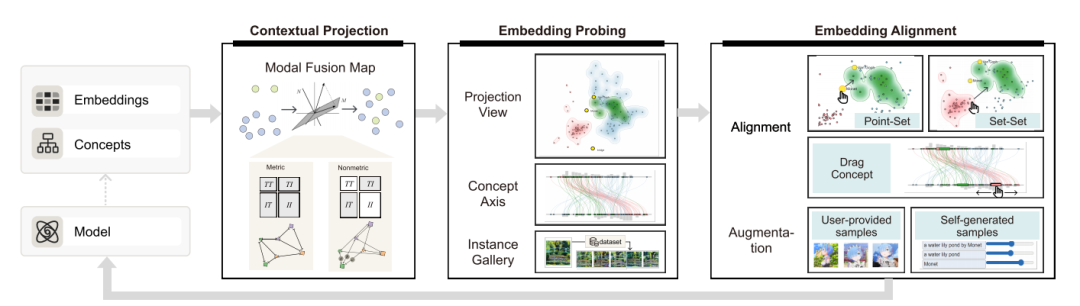
创新点
-
模态融合图(MFM):通过整合度量和非度量目标,MFM在处理多模态嵌入时表现出更高的信任度和连续性。例如,在COCO数据集上的实验中,MFM在跨模态信任度和连续性指标上分别比DCM提高了2%以上。
交互式对齐:支持用户在多个层面上进行对齐操作,包括点集对齐和集合对齐。这种灵活的对齐方式使得用户能够更直观地调整模型的嵌入空间,从而提高模型的性能。例如,在零样本分类任务中,通过一次点集对齐操作,模型的准确率从69.28%提升到了70.66%。
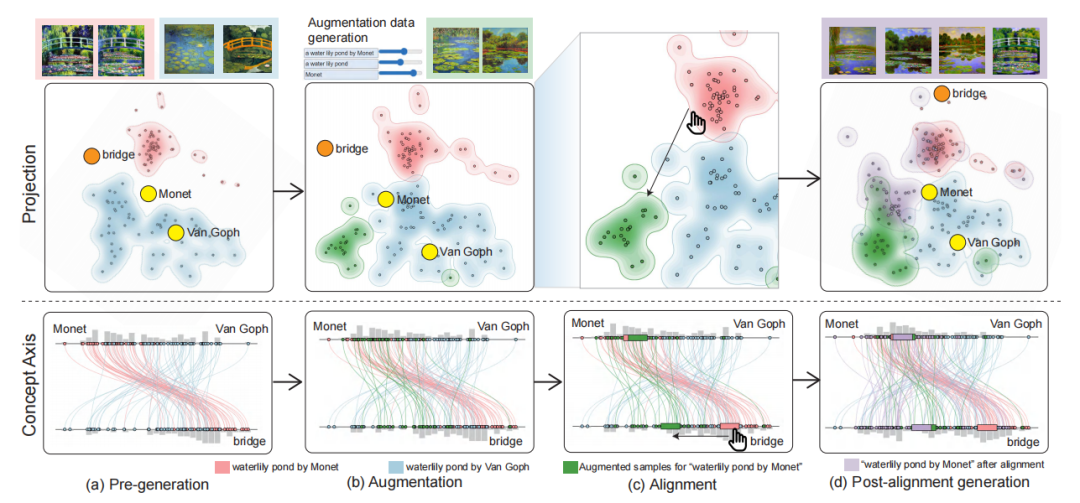
概念轴视图:通过概念轴视图,用户可以更直观地探索图像嵌入与文本概念的关系。例如,在跨模态检索任务中,用户可以通过概念轴视图发现并修正模型在理解“桥”和“莫奈”概念时的错位。
论文2:
SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models
SPHINX:多模态大型语言模型中权重、任务和视觉嵌入的联合混合
方法
-
权重混合:在预训练阶段,将大型语言模型(LLM)的权重与视觉语言数据的权重进行混合,以增强视觉-语言对齐。
任务混合:在微调阶段,将多种视觉指令任务混合在一起,包括视觉问答、区域级理解、文档布局检测和人体姿态估计等。
视觉嵌入混合:从不同的视觉网络架构中提取综合视觉嵌入,包括CNN和ViT,以及监督和自监督预训练的视觉编码器。
高分辨率子图像混合:为了提高对高分辨率图像的细粒度理解,将输入的高分辨率图像分割成多个子图像,并将其与低分辨率图像一起输入模型。
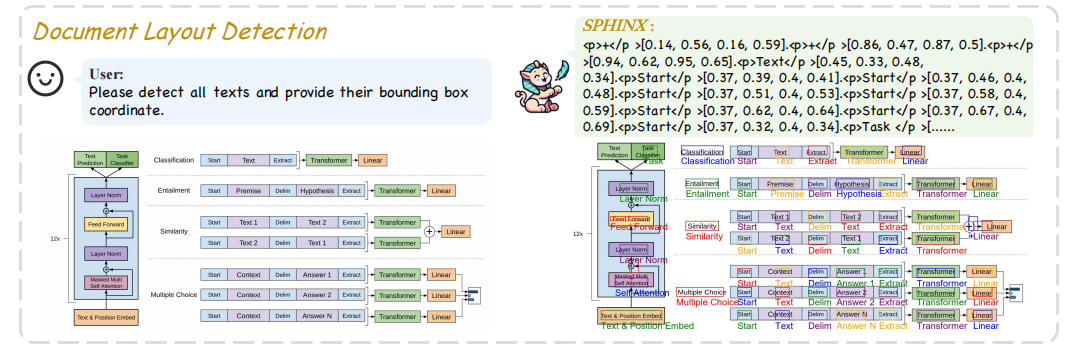
创新点
-
权重混合:通过将预训练的LLM与视觉语言数据的权重进行混合,SPHINX在跨模态理解任务中表现出色。例如,在POPE基准测试中,SPHINX的性能比其他方法提高了6%以上。
任务混合:通过多任务微调,SPHINX在多种视觉任务上表现出色。例如,在VQAv2数据集上,SPHINX的准确率达到了62.1%,比其他方法提高了2%以上。
视觉嵌入混合:通过混合不同架构和预训练方法的视觉嵌入,SPHINX在视觉-语言对齐任务中表现出色。例如,在OKVQA数据集上,SPHINX的准确率达到了46.8%,比其他方法提高了4%以上。
高分辨率子图像混合:通过混合高分辨率子图像,SPHINX在细粒度视觉理解任务中表现出色。例如,在高分辨率图像的区域级描述任务中,SPHINX的性能比其他方法提高了5%以上。

论文3:
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
VISTA:用于通用多模态检索的可视化文本嵌入
方法
-
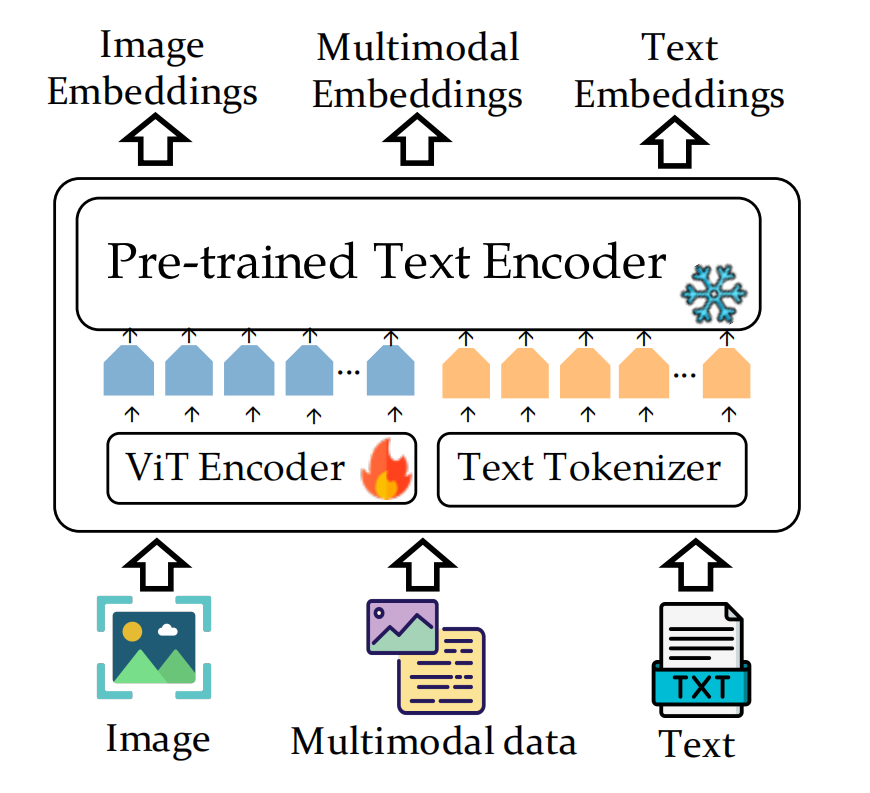
灵活的模型架构:通过引入视觉标记嵌入,将强大的文本编码器扩展为具有图像理解能力的模型。VISTA使用Vision Transformer(ViT)作为图像标记器,使预训练的文本模型能够识别图像标记,同时保持冻结状态。
数据生成策略:提出了两种数据生成策略,用于自动生成高质量的图像-文本组合数据,以训练多模态嵌入模型。这些策略包括Image&Text To Image (IT2I)和Text To Image&Text (T2IT)数据集。
两阶段训练算法:首先使用大规模弱标注的跨模态数据对视觉标记嵌入与文本编码器进行对齐,然后使用生成的组合图像-文本数据进行多模态表示能力的训练。
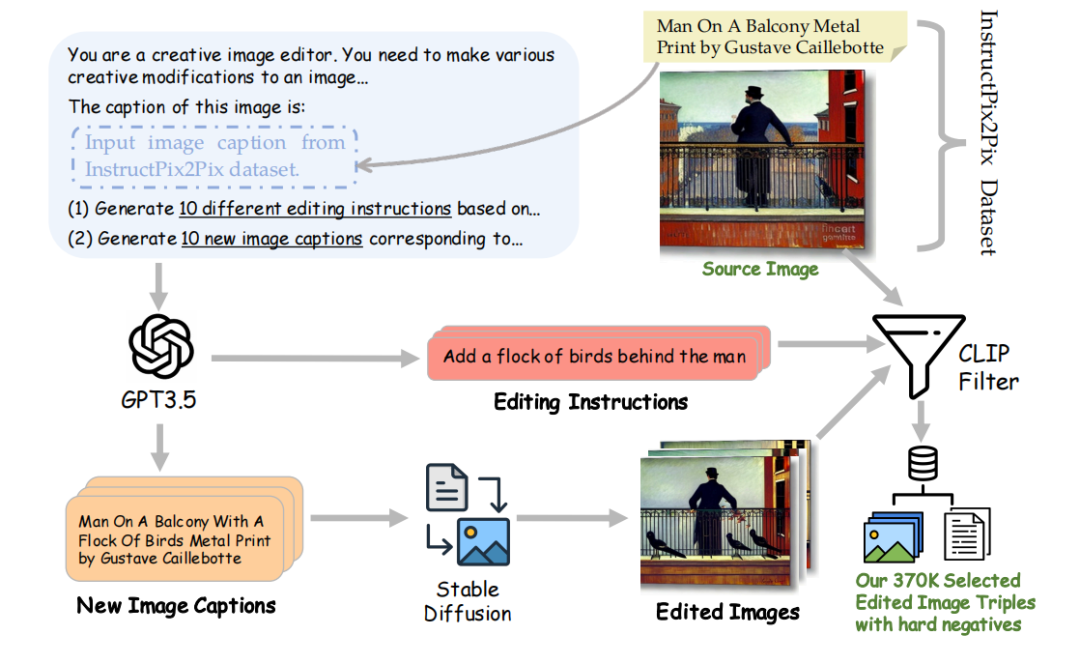
创新点
-
灵活的模型架构:VISTA通过将ViT作为图像标记器,实现了文本和图像数据的深度融合,同时保留了文本嵌入的原始性能。例如,在WebQA数据集上,VISTA的Recall@5达到了60.11%,比其他方法提高了9%以上。
数据生成策略:通过自动生成高质量的图像-文本组合数据,VISTA能够在不需要人工标注的情况下训练多模态嵌入模型。例如,IT2I数据集生成了307K个查询-候选对,T2IT数据集生成了213K个查询-候选对。
两阶段训练算法:通过两阶段训练,VISTA在多模态检索任务中表现出色。例如,在CIRR数据集上,VISTA的Recall@5达到了22.51%,在FashionIQ数据集上,VISTA的Recall@5达到了7.51%。
论文4:
Watermarking Vision-Language Pre-trained Models for Multi-modal Embedding as a Service
用于多模态嵌入即服务的视觉-语言预训练模型的水印技术
方法
-
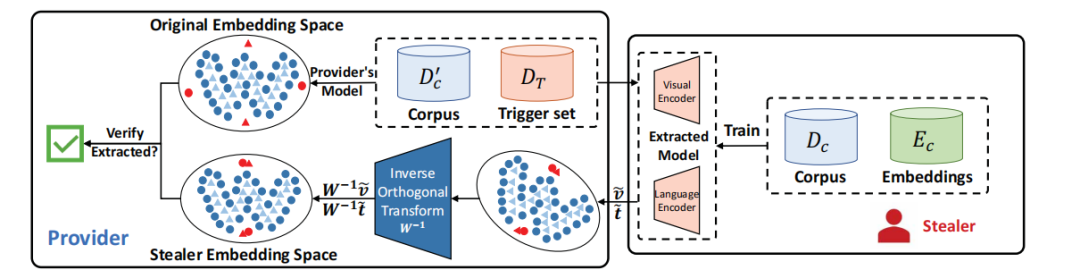
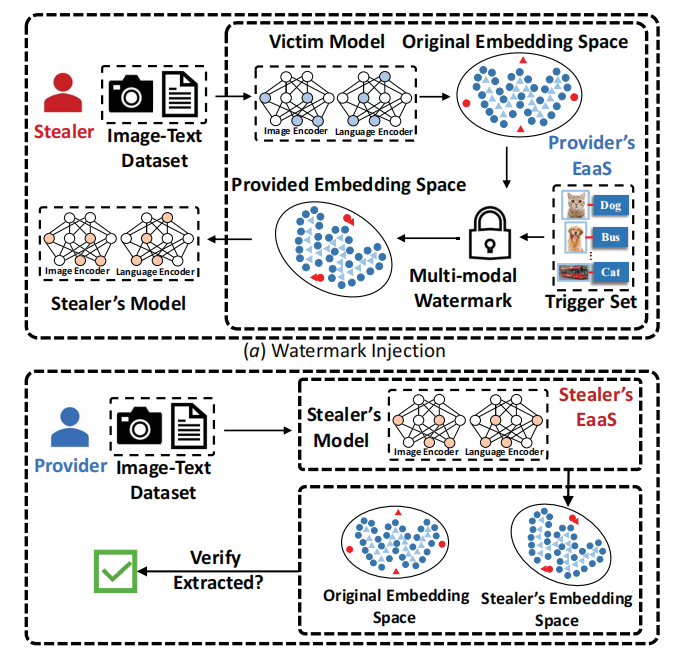
水印注入:通过学习一个近似正交变换矩阵,将预定义的触发器嵌入到视觉-语言预训练模型(VLP)中。这个变换矩阵将原始嵌入空间转换为包含预定义承诺和用户特定信息的提供嵌入空间。
版权验证:通过比较窃取者的嵌入空间和提供者的原始嵌入空间,验证版权。具体来说,通过计算触发器的相似度和嵌入分布的相似度来验证版权。
触发器选择:使用与原始训练数据分布不同的公共图像-文本样本作为触发器,以提高水印的安全性。
创新点
-
水印注入:通过正交变换矩阵注入水印,确保水印注入过程对模型性能的影响最小。例如,在MS-COCO数据集上,VLPMarker的Recall@5达到了91.1%,与原始模型性能相当。
版权验证:通过结合触发器和嵌入分布验证,提高了水印对常见攻击的鲁棒性。例如,在模型提取攻击中,VLPMarker的检测性能比EmbMarker提高了10%以上。
触发器选择:使用与原始训练数据分布不同的公共图像-文本样本作为触发器,提高了水印的安全性。例如,在不同触发器数量的实验中,VLPMarker在32到64个触发器时表现出最佳的检测性能。
小编整理了多模态embedding论文代码合集
需要的同学
回复“ 多模态embedding”即可全部领取

















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









