






2025深度学习发论文&模型涨点之——强化学习+卡尔曼滤波
强化学习(Reinforcement Learning, RL)和卡尔曼滤波(Kalman Filter, KF)是两种不同的方法,分别用于决策制定和状态估计。将它们结合起来,可以提高系统在不确定环境中的性能。
-
探索阶段: 通过尝试不同的动作来探索环境。
- 利用阶段: 通过选择最优动作来利用已知的环境信息。
小编整理了一些强化学习+卡尔曼滤波【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学扫码添加我
回复“强化学习+卡尔曼滤波”即可全部领取

论文精选
论文1:
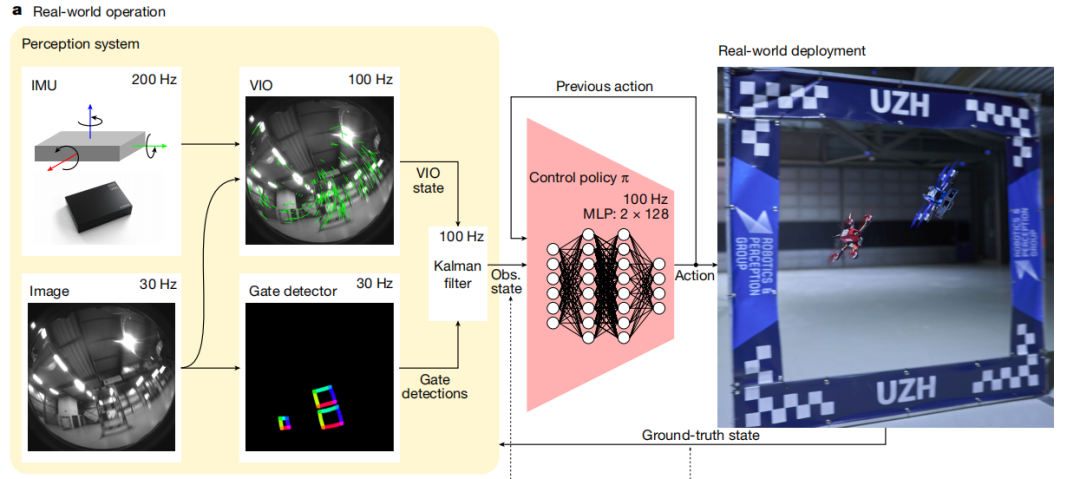
Champion-level drone racing using deep reinforcement learning
使用深度强化学习的冠军级无人机竞速
方法
-
深度强化学习(Deep RL):利用深度强化学习训练无人机的控制策略,使其能够在模拟环境中学习最优飞行路径。
感知系统:结合视觉和惯性信息,将高维的视觉和惯性数据转化为低维的表示,用于无人机的状态估计。
控制策略:通过深度强化学习训练的前馈神经网络,将感知系统的输出转化为无人机的控制指令。
模拟与现实结合:使用模拟环境进行策略训练,并通过在真实环境中收集的数据来调整模拟环境,以减少模拟与现实之间的差异。
创新点
-
冠军级性能:Swift系统首次实现了自主无人机在真实世界中达到人类世界冠军级别的竞速性能,展现了人工智能在物理世界中的高水平应用。
模拟到现实的转移:通过在真实环境中收集数据并将其用于模拟环境的调整,显著提高了模拟训练策略在实际应用中的性能,减少了模拟与现实之间的差距。
性能提升:Swift在与三位人类冠军的比赛中多次获胜,并创下了最快比赛时间记录,比人类冠军的最佳成绩快了半秒,展示了其在速度和灵活性方面的优势。
论文2:
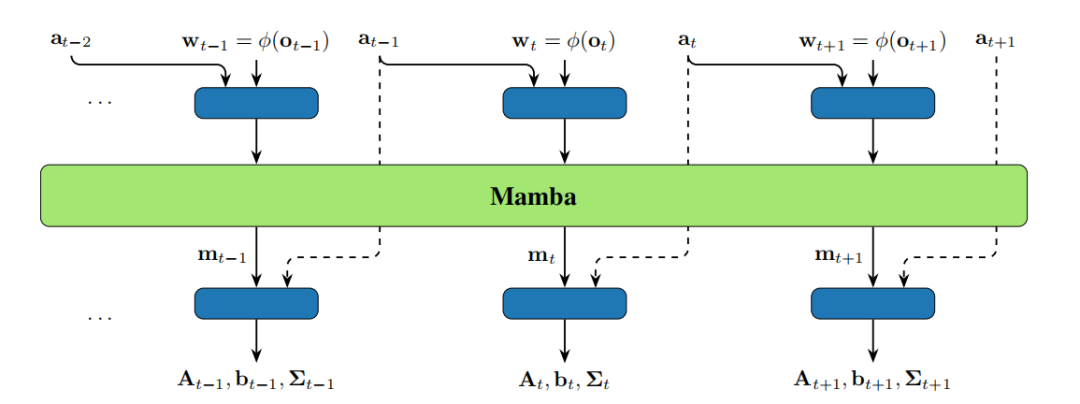
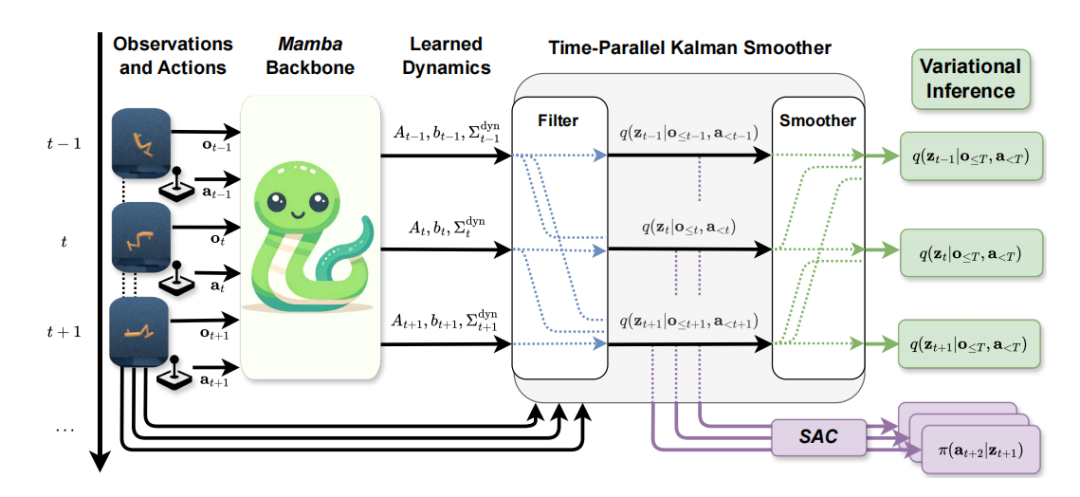
KalMamba: Towards Efficient Probabilistic State Space Models for RL under Uncertainty
KalMamba:面向不确定条件下强化学习的高效概率状态空间模型
方法
-
概率状态空间模型(SSM):结合了概率SSM的不确定性和确定性SSM的可扩展性,通过线性高斯SSM在潜在空间中进行推断。
Mamba架构:利用Mamba学习潜在空间中线性高斯SSM的动态参数,实现高效的并行计算。
卡尔曼滤波与平滑:在潜在空间中使用卡尔曼滤波和平滑进行推断,以获得用于控制的信念状态。
变分推断:采用变分推断方法,通过紧致的变分下界优化模型,提高对不确定性的建模能力。
创新点
-
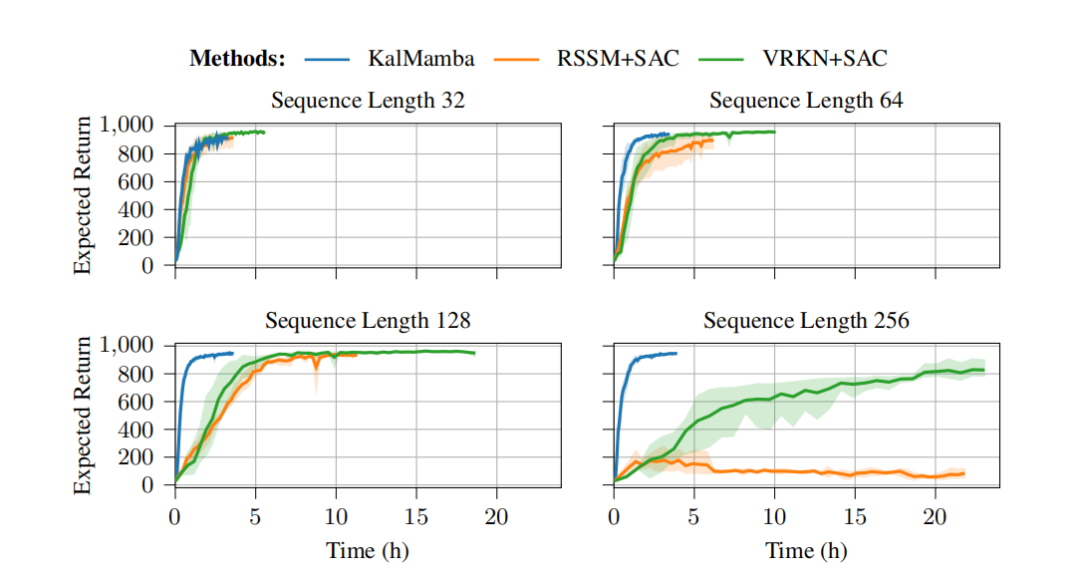
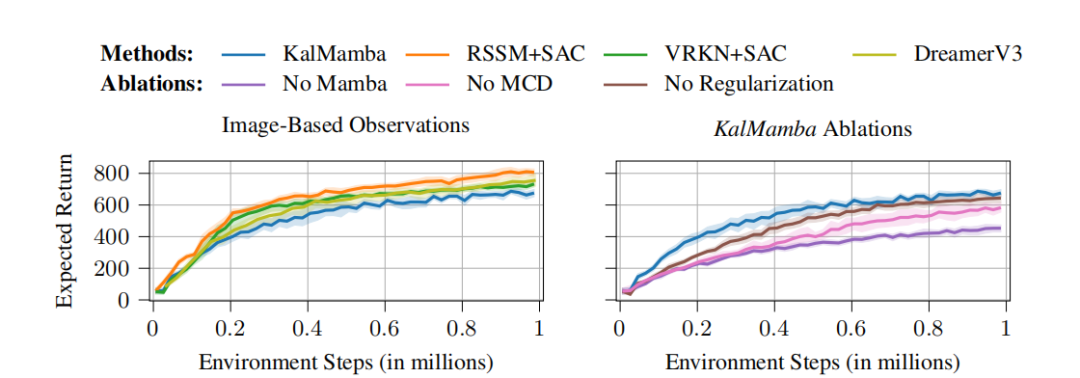
高效并行化:通过使用Mamba和卡尔曼滤波的并行化实现,KalMamba在处理长序列数据时具有显著的计算效率提升,与现有方法相比,训练时间大幅缩短。
不确定性建模:通过变分推断和紧致的变分下界,KalMamba能够更准确地建模系统中的不确定性,特别是在长序列任务中表现突出。
性能提升:在DeepMind Control Suite的多个任务中,KalMamba在性能上与现有的先进SSM方法相当,同时在训练速度上具有明显优势,特别是在长序列任务中。
论文3:
Sim-to-real deep reinforcement learning based obstacle avoidance for UAVs under measurement uncertainty
基于测量不确定性的无人机避障的模拟到现实深度强化学习
方法
-
深度强化学习(DRL):使用深度强化学习中的近端策略优化(PPO)算法训练无人机的避障策略。
噪声建模:将测量噪声建模为具有未知均值和方差的高斯分布,模拟真实传感器的噪声特性。
去噪技术:使用低通滤波器和卡尔曼滤波器等去噪技术来提高在噪声环境下的性能。
模拟到现实的转移:在模拟环境中训练的策略可以直接部署到真实无人机上,无需进一步调整。
创新点
-
噪声鲁棒性:通过在训练过程中注入噪声,提高了策略在真实世界中的鲁棒性,即使在存在测量噪声的情况下也能有效避障。
性能提升:在真实环境中,通过注入适当方差的噪声,可以显著提高策略的成功率,即使在存在偏差的情况下也能提高性能。
直接部署:训练得到的策略可以直接应用于真实无人机,无需额外调整,验证了模拟到现实转移的有效性。
论文4:
Value-based reinforcement learning for digital twins in cloud computing
云计算中基于价值的数字孪生强化学习
方法
-
数字孪生(DT):构建一个数字孪生模型,用于实时监控和预测物理系统的状态。
强化学习(RL):使用强化学习算法优化控制策略,同时考虑状态估计的准确性和通信成本。
信息价值(VoI):基于信息价值的算法选择最具信息价值的传感器进行数据采集,以满足数字孪生模型的预测精度要求。
扩展卡尔曼滤波(EKF):使用扩展卡尔曼滤波技术提高状态估计的准确性。
创新点
-
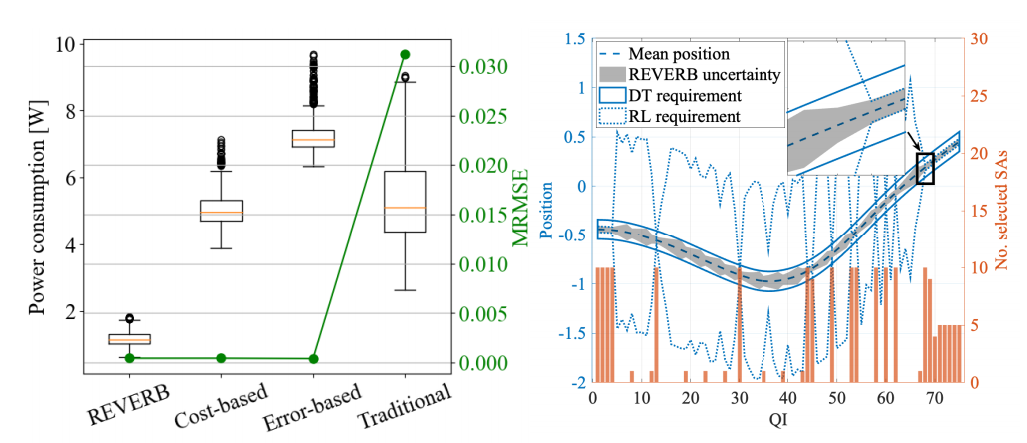
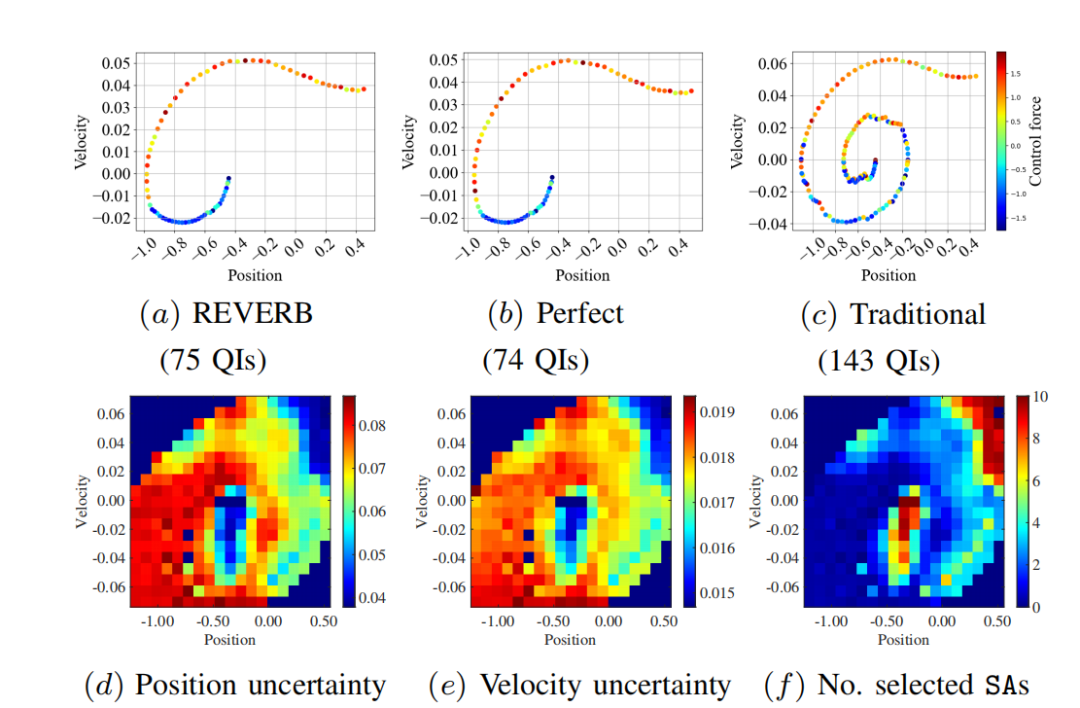
联合优化:通过强化学习和信息价值算法联合优化控制策略和传感器选择,显著提高了数字孪生模型的性能。
通信成本降低:通过选择最具信息价值的传感器,减少了不必要的数据传输,降低了通信成本,最高可达五倍。
性能提升:在模拟实验中,提出的REVERB算法在控制精度和通信效率方面均优于传统方法,显示出其在复杂系统中的适用性。

小编整理了强化学习+卡尔曼滤波论文代码合集
需要的同学扫码添加我
回复“ 强化学习+卡尔曼滤波”即可全部领取


















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









