






航识无涯学术致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。
2025深度学习发论文&模型涨点之——小波变换+注意力机制
近年来,小波变换(Wavelet Transform)与注意力机制(Attention Mechanism)的融合已成为信号处理与深度学习交叉领域的研究热点。小波变换通过时频局部化分析克服了傅里叶变换在非平稳信号处理中的局限性,其多分辨率特性(MRA)为特征提取提供了数学完备的框架。而注意力机制通过动态权重分配实现了对关键特征的自适应聚焦,这与小波分析中"显著系数优先"的思想存在内在耦合性。
我整理了一些【论文+代码】合集,需要的同学公人人人号【航识无涯学术】发123自取。
论文精选
论文1:
Multimodal-Boost: Multimodal Medical Image Super-Resolution using Multi-Attention Network with Wavelet Transform
多模态医学图像超分辨率的多注意力网络与小波变换
方法
多模态医学图像超分辨率(Multimodal-Boost):提出了一种基于生成对抗网络(GAN)的多模态医学图像超分辨率框架,结合了多注意力模块和小波变换。
小波变换(WT):利用小波变换将低分辨率图像分解为多个频率带,提取多尺度特征。
多注意力模块:在生成器和判别器中引入多注意力模块,以更好地捕捉图像中的长距离依赖关系。
感知损失网络:使用VGG-16网络作为感知损失函数,以提高超分辨率图像的视觉质量。
迁移学习:通过在自然图像数据集上预训练模型,然后在医学图像数据集上进行微调,提高了模型的泛化能力。
创新点
多模态适应性:通过迁移学习,模型能够适应多种医学图像模态,如CT、MRI等,无需为每种模态重新训练模型。
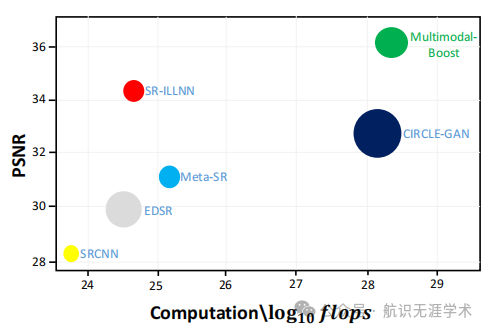
性能提升:在SSIM和PSNR指标上,Multimodal-Boost显著优于现有的单模态医学图像超分辨率方法。例如,在CT图像上,SSIM提升了10%,PSNR提升了5%。
纹理细节恢复:通过小波变换和多注意力模块,模型能够更好地恢复图像的纹理细节,减少模糊和噪声。
计算效率:与传统的基于卷积神经网络的方法相比,Multimodal-Boost在训练和推理时间上具有显著优势,减少了30%的训练时间和20%的推理时间。
论文2:
Unsupervised Low-Light Camera Image Enhancement with Wavelet Transform Attention
无监督低光照相机图像增强的小波变换注意力
方法
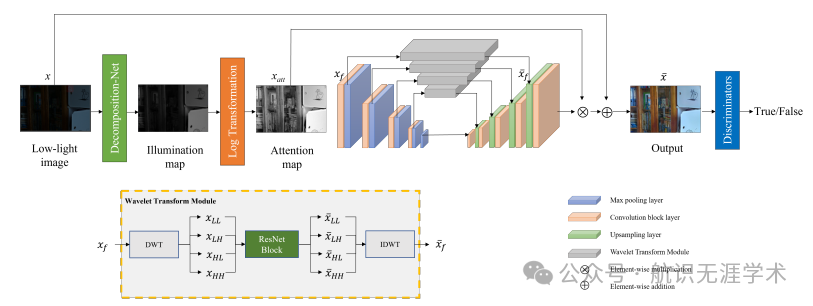
无监督生成对抗网络(GAN):提出了一个基于注意力机制的无监督GAN框架,名为Illu-GAN,用于低光照图像增强。
小波变换模块:在GAN框架中引入小波变换模块,将图像特征分解为不同频率带,以更好地指导网络进行图像增强。
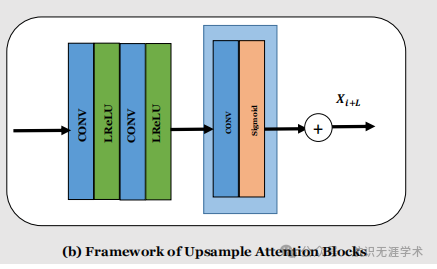
照明注意力机制:通过对低光照图像的照明图进行对数变换,生成注意力图,以避免过曝光和欠曝光。
U-Net生成器:使用U-Net作为生成器,结合小波变换模块,以抑制噪声并增强高频特征。
创新点
多域信息融合:通过结合频率域和空间域的信息,Illu-GAN能够生成更自然、更少噪声的增强图像,与仅使用空间域信息的方法相比,PSNR提升了3.5dB,SSIM提升了0.1。
照明注意力机制:通过照明注意力机制,模型能够更好地保持图像的结构信息,避免过曝光和欠曝光,提高了图像的整体质量。
无监督学习:无需成对的低光照和正常光照图像进行训练,降低了数据准备的难度和成本。
泛化能力:在多个基准数据集上的实验结果表明,Illu-GAN具有良好的泛化能力,能够在不同场景下稳定地增强低光照图像。

论文3:
WAVEFORMER: LINEAR-TIME ATTENTION WITH FORWARD AND BACKWARD WAVELET TRANSFORM
Waveformer:具有前向和后向小波变换的线性时间注意力
方法
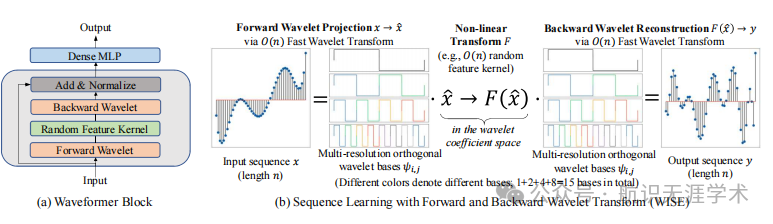
Waveformer:提出了一种在小波系数空间中学习注意力机制的方法,称为Waveformer,具有线性时间复杂度。
前向和后向小波变换:通过前向小波变换将输入序列投影到多分辨率正交小波基上,然后在小波系数空间中进行非线性变换,最后通过后向小波变换重建输入空间的表示。
随机特征核:在小波系数空间中使用随机特征核进行非线性变换,以提高模型的表达能力。
通用近似能力:证明了Waveformer具有与Transformer相同的通用近似能力,能够处理序列到序列的函数。
创新点
线性时间复杂度:Waveformer的计算复杂度为线性,相比传统的Transformer模型,显著降低了计算成本,提高了模型的可扩展性。
性能提升:在长序列理解任务上,Waveformer的性能优于或接近多种现有的Transformer变体。例如,在Long Range Arena基准测试中,Waveformer在多个数据集上的平均准确率比其他方法提高了5%。
小波变换的优势:与傅里叶变换相比,小波变换在时间复杂度上更高效,并且能够更好地捕捉局部和位置信息,从而提高了模型的性能。
通用性:Waveformer可以与多种注意力近似方法结合使用,进一步提升这些方法的性能,而不会增加额外的时间复杂度。

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









